| 类型 | 内容 |
|---|---|
| 标题 | Exploring Domain Name Based Features on the Effectiveness of DNS Caching |
| 时间 | 2017 |
| 会议 | ACM SIGCOMM Computer Communication Review |
| DOI | 10.1145/3041027.3041032 |
| 引用 | Hao S, Wang H. Exploring domain name based features on the effectiveness of dns caching[J]. ACM SIGCOMM Computer Communication Review, 2017, 47(1): 36-42. |
速读
文章的目的概括为:
- 找出一次性域名的特征
- 构建可以区分一次性域名和正常域名的分类器
- 提出提高DNS缓存器的性能的策略
使用决策树和随机森林构建的分类器可以达到85+%的正确率。
最终的策略使DNS缓存器的命中率提高了7%-8%,达到了92%-93%。 å
简介
这篇文章的题目翻译成中文是《基于dns缓存有效性的域名特征研究》,其本质目的在于根据域名的特征将域名划分为两类:一次性域名(disposable domains/one-time-used domains/once-used domains)和可重用域名(reused domains),并且研究一种策略让DNS缓存器不再缓存一次性域名以提高性能。
文章中提到DNS是互联网中的一项基本的服务,所以其在互联网中的流量很少受到阻塞。于是在互联网上就发现了对DNS的滥用情况,这种滥用情况就是利用一次性域名来传递消息。这种一次性域名往往在使用一次后就不再使用了,但是DNS缓存器会在一定时间内(TTL)缓存这条记录。
其中一次性域名不一定是恶意域名,它广泛存在于各类服务提供商中,包括流行的搜索引擎、社交网络、CDN和安全公司。但由于此类域名的使用越来越多,所以DNS缓存将充满这种一次性域名,这就导致了DNS缓存的性能下降。
TTL的概念
(此部分论文没讲,为自己收集的补充资料)
TTL即Time-To-Live,代表一条域名解析记录(RR)在DNS服务器中的存留时间
- 一般以秒为单位,很多域名的默认值是3600,即1小时。
- 增大TTL值,可以节约域名解析时间
- 减小TTL值,可以减少更新域名记录时的不可访问时间
数据集
数据集来自于在特拉华大学(UD)和威廉与玛丽学院(WM)的DNS服务器上捕获的两周内的DNS查询日志。(移除了本地域名的查询)
数据集存在局限性:
- 日志是从校园的DNS服务器上获取的,无法反映在大型ISP的DNS服务器上观察到的域名动态。
- 日志记录的周期跨度有限。DNS的TTL值通常短于一天,所以影响不大
特征
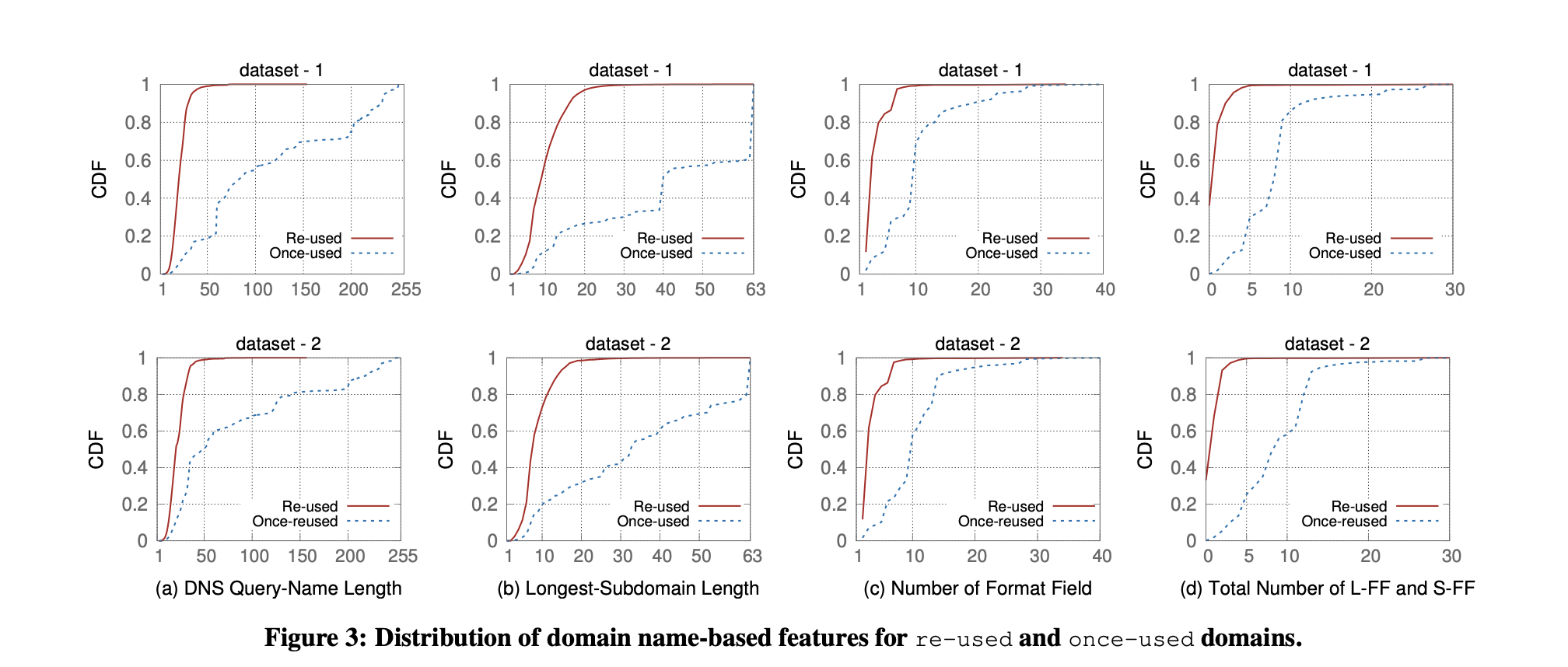
作者为一次性域名总结了4个特征:
- F1:域名的总长度太长:很多一次性域名通过DNS查询来发送消息,所以这类域名会有更长的查询名称来打包尽可能多的信息
- F2:最长子域名的长度太长
- F3a:域名的深度太深:一次性域名会使用’.’来作为分隔符,对信息进行格式化,这样查询名称中就会有大量的子域名
- F3b:格式化字段的数量太多:和上面提到的’.’一样,作者观察到’-‘也被用于做字段分隔符
- F4:异常字段数量太多:许多字段可能异常的长或异常的短(LL-F:长度大于10的字段数量,SS-F:长度短于3的字段数量)
如下图所示,给出了一些一次性域名的例子,他们分别满足不同的特征,在最右侧分别表明该条域名满足哪几条特征。

对于特征是否有效的验证:
Ground Truth
作者将数据集中提取的只出现过一次的域名标记为“一次性域名”。
可能存在某些不常见的域名因为只被查询了一次导致被误标记为“一次性域名”,但是考虑到某一个地区的网络用户在数千人左右,所以对实际情况影响不大,因为这个域名记录的缓存可能在下一次查询之前就已经被淘汰了。
分类
作者分别使用决策树和随机森林构建分类器。
分类结果如图所示:
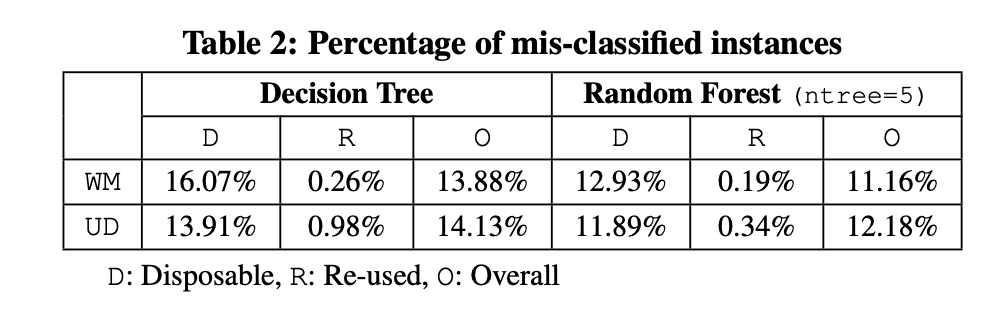
效果:
- 85%-88%的一次性域名的解析记录能被正确的标记
- 只有0.2%-1%的正常的域名解析记录被错误的标记
单独观察每个特征的表现:
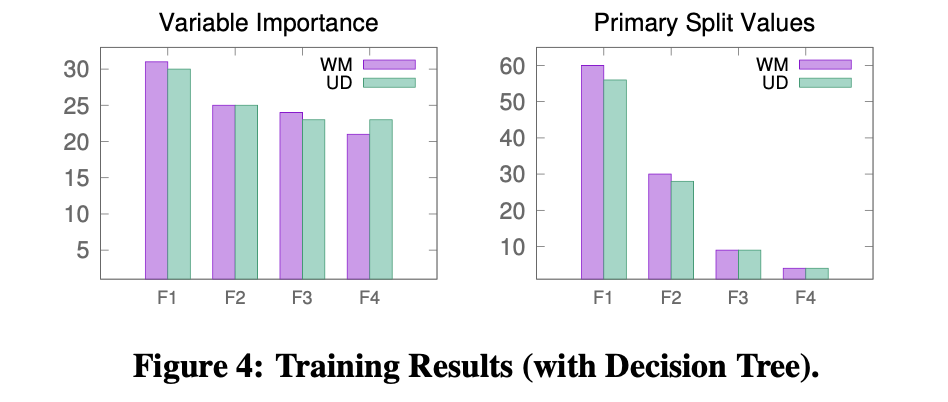 结论:
结论:
- 所有特征都在分类中起着重要作用。
- 通过将特征的组合可以降低错误率
模拟在DNS缓存中的效果
作者基于djbdns进行修改实现了一个模拟的解析器程序,遵循标准的TTL模型(即不分配默认的最小ttl)。negative caching的记录时间取决于SOA记录的TTL值。 因为现代缓存器的内存管理策略复杂,所以作者没有设置时间间隔来清理内存,仅在达到缓存上限时才使用例如LRU的策略来进行替换。
关于RR的缓存数目:作者发现根据根据前人的研究DNS缓存的命中率应该在80%-87%之间。所以作者根据数集的大小和FIFO的策略进行实验发现,RR的缓存数目设置为10万,可以使命中率达到86%。 (这个值并不适用于ISP的DNS服务器,ISP服务器可能需要一个更大的值。)
实验效果最后如图所示
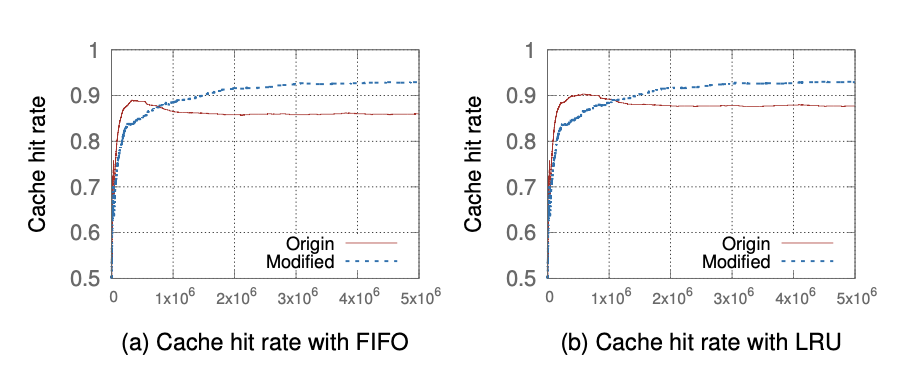
结论:
- 在FIFO算法中,可以提高8%的缓存命中率
- 在伪LRU算法中,可以提高7%的缓存命中率
- 最终两者的命中率都在92%-93%之间
补充
Chen Y , Antonakakis M , Perdisci R , et al. DNS Noise: Measuring the Pervasiveness of Disposable Domains in Modern DNS Traffic[C]// 2014 44th Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN). IEEE, 2014.
这是在此文章之前研究一次性域名的一篇论文,研究的数据集规模更大,时间跨度更广,但没有进行分类。
个人想法
这篇文章还有少许的改进地方,比如数据集的规模太小不具有代表性,或许可以选择更好的分类器。我在研讨课上汇报时,老师告诉我他们也进行一次性域名的分类,而且分类效果是高于这篇论文所声称的80%多的,能达到90%+。但我认为即使改进了也意义不大,因为这样简单的分类方法最终就可以让缓存命中率达到92%,那么再挑选更好的分类器能提升的幅度有限,可能还会花费更多的资源用于分类。
并且作者最后也指出:应该不会有人通过改变域名结构来规避分类器的规则,因为一次性的域名已经完成了通信任务,是否被缓存对他们来说不重要。
所以这个方向再去深度研究的意义已经不大了。