- I. 介绍
- III. 具有相关攻击特征的攻击分类
- IV. 机器学习:技术与特征选择
- V. 基于单/多分类器机器学习方法的入侵检测综述
- VI. 特定攻击检测技术的分类
- VII. 不同机器学习算法在入侵检测中的性能分析
- VIII. 低频攻击检测中的几个问题
- XI. 结论
- 引用
| 类型 | 内容 |
|---|---|
| 标题 | A Detailed Investigation and Analysis of using Machine Learning Techniques for Intrusion Detection |
| 时间 | 2018 |
| 会议 | 2018 IEEE Communications Surveys & Tutorials |
| 引用 | Mishra P, Varadharajan V, Tupakula U, et al. A detailed investigation and analysis of using machine learning techniques for intrusion detection[J]. IEEE Communications Surveys & Tutorials, 2018, 21(1): 686-728. |
本文是一篇来自2018年S&T的关于IDS的综述。
I. 介绍
随着科技的发展,黑客事件日益增多。公司每年都会报告大量的黑客事件。2007年,俄罗斯对爱沙尼亚网站发起分布式拒绝服务(DDoS)攻击。2008年6月17日,Amazon[2]开始从其一个位置的多个用户接收一些经过身份验证的请求。请求开始显著增加,导致服务器速度减慢。2013年1月,欧洲网络和信息安全局(ENISA)报告说,Dropbox受到DDoS攻击,并在超过15小时的时间内遭受严重服务损失,影响到全球所有用户。2014年9月28日,Facebook遭到疑似DDos攻击。Panjwani等人报告在50%的网络系统攻击前会有网络扫描活动。攻击者不仅发起了泛洪和探测攻击,而且还以病毒、蠕虫、垃圾邮件的形式传播恶意软件文件,以利用现有软件中存在的漏洞,对存储在计算机上的用户敏感信息造成威胁。
思科年度安全报告提到与波士顿马拉松爆炸案有关的垃圾邮件占2013年4月17日全球所有垃圾邮件的40%。在思科最近于2017年进行的一项调查中,特洛伊木马被列为五大恶意软件之一,用于获得用户计算机和组织网络的初始访问权限。因此,在这样一个复杂的技术环境中,安全是一个巨大的挑战,需要智能地加以解决。
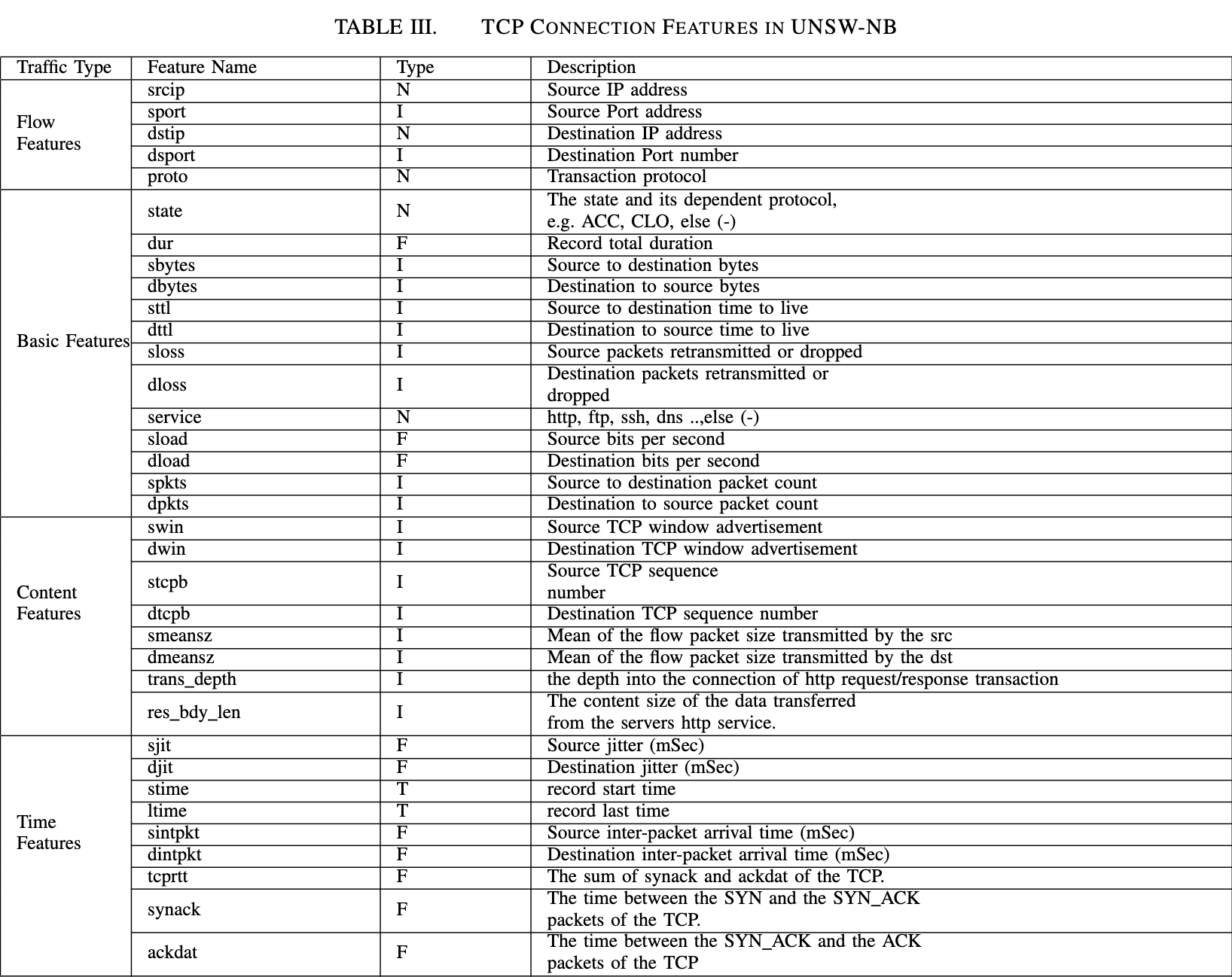
研究人员考虑了另一种入侵检测攻击类型。例如,基于KDD’99数据集的DoS(Denial of Service)攻击、扫描攻击(Probe)和R2L(Remote to Local)攻击以及U2R(User to Root)攻击。最近的一个攻击数据集(UNSW-NB1)将攻击分为九类:模糊攻击、分析攻击、侦察攻击、ShellCode、Worm、一般攻击、Dos、Exploit and Generic。第三节详细讨论了所有这些攻击。
目前的安全解决方案包括使用防火墙、杀毒软件和入侵检测系统(IDS)等middle-box。防火墙根据源地址或目标地址控制进入或离开网络的流量,它根据防火墙规则控制流量。防火墙受限于可用状态的数量及其对网络中主机的了解。IDS是一种安全工具,它监视网络流量,扫描系统中的可疑活动,并向系统或网络管理员发出警报。这是本文关注的主要焦点。
入侵检测系统主要有两种类型:基于主机的入侵检测系统和基于网络的入侵检测系统。基于主机的入侵检测系统(HIDS,Host based Intrusion Detection System)监视单个主机或设备,并在检测到可疑活动(如修改或删除系统文件,错误的系统调用,配置的意外更改)时向用户发送警报。基于网络的入侵检测系统(NIDS,Network based Intrusion Detection System)通常放置在网关和路由器上,以检查网络流量中是否存在入侵。
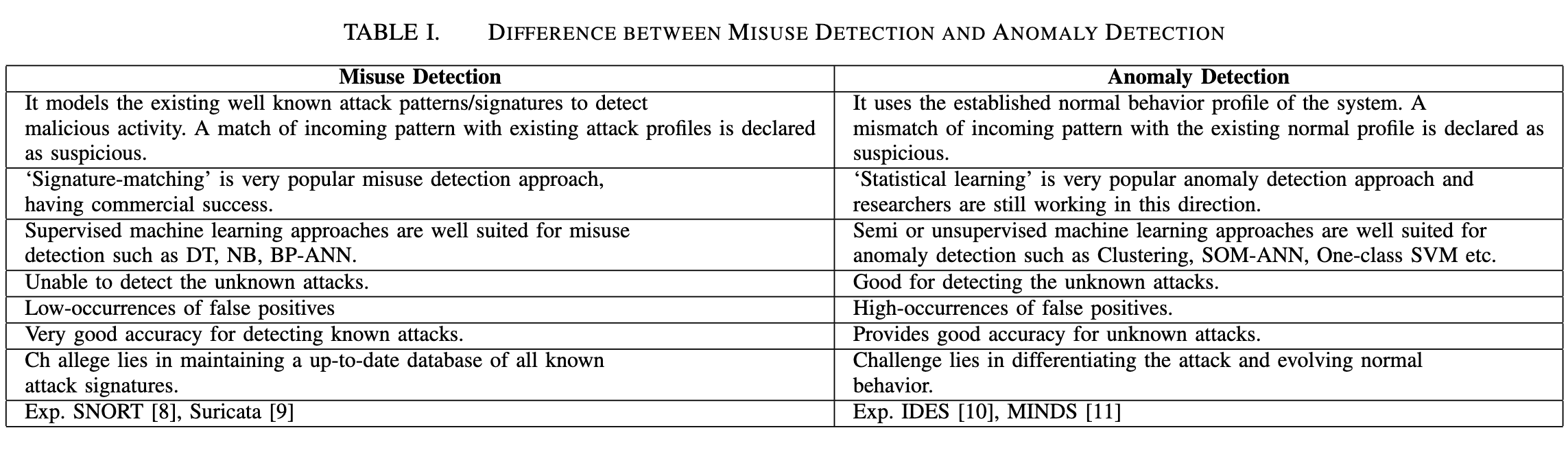
从高层次上讲,这些IDS使用的检测机制分为三种类型:误用检测,异常检测和混合检测。 在误用检测方法中,IDS维护一组知识库(规则)以检测已知的攻击类型。误用检测技术可大致分为基于知识库的技术和基于机器学习的技术。在基于知识库的技术中,将网络流量或主机审计数据(如系统调用跟踪)与预定义的规则或攻击模式进行比较。基于知识库的技术可分为三类:(i)特征匹配(ii)状态转移分析和(iii)基于规则的专家系统2。
基于特征匹配的误用检测技术根据固定模式扫描数据包。如果任何模式与数据包头匹配,则该数据包被标记为异常。基于状态转移分析的方法针对已知的可疑模式维护系统的状态转移模型。模型的不同分支导致机器的最终受损状态。基于规则的专家系统为不同的入侵场景维护规则数据库。基于知识库的入侵检测系统需要动态地对知识库进行定期维护,并且无法检测到攻击的变体。误用检测也可以使用有监督的机器学习算法,如反向传播人工神经网络(BP-ANN)、决策树 C4.5和多类支持向量机(SVM)。
基于机器学习的IDS提供了一个可以基于学习到的正常行为和攻击行为来判断攻击类别的系统。基于机器学习的IDS(有监督的)的目标是生成已知攻击的一般表示。误用检测技术无法检测未知攻击,但可以准确的检测已知攻击。这种类型的IDS还需要对特征数据库进行定期维护,这增加了人工成本。
基于误用检测的IDS特别是基于特征匹配的IDS非常受欢迎,并获得了商业成功。 与这些方法相关的优缺点如表I所示。这些IDS维护着一个已知攻击特征的数据库。 它可以采用代码,系统调用模式序列或行为配置文件等形式来表示,IDS以某种格式存储攻击特征。 我们使用TCP-ping攻击来说明基于特征的滥用检测系统(特别是SNORT)。如果攻击者想知道计算机是否处于活动状态,他会扫描该计算机。 攻击者发送ICMP ping数据包。 如果计算机设置为不响应ICMP ECHO REQUEST ping数据包,则攻击者可以使用nmap工具将TCP ping数据包发送到端口80,并将ACK标志设置为序号0。此攻击的特征在于标志设置为’A’值,并设置确认值为03。 因为这样的数据包在受害方是不可接受的; 收到封包后,如果RST数据包会发送到攻击者的计算机,则表明计算机还处于运行状态。 例如针对IP为192.168.1.0/24网络中的计算机,检测TCP ping攻击的规则如下:
alert TCP any any ->192.168.1.0/24 any,(flags: A;ack: 0; msg: ”TCP ping detected”;)
基于特征匹配的IDS的主要限制是需要定期更新系统以添加规则。它对于未定义规则的新攻击会生成很多假警报。所以,异常检测方法也被用来检测入侵。
基于异常检测的IDS基于以下假设:攻击者的行为与正常用户的行为不同4。 它有助于检测不断发展的攻击。 基于异常检测的IDS对系统的正常行为进行建模,并不断对其进行更新。 例如,每个网络连接由一组特征值来标识(例如协议,服务,登录尝试次数,每个流的数据包,每个流的字节,源地址,目标地址,源端口,目标端口等)。 这些特征值的行为统计信息会在一段时间内被记录。 对于流中特征值中的异常偏差都将被异常检测引擎标记为异常。 异常检测技术大致分为三类:统计技术,基于机器学习的技术和基于有限状态机(FSM)的技术。 有限状态机(FSM)会生成一个由状态,转移和动作组成的行为模型。 Kumar等人提出了一种IDS,它利用隐马尔可夫模型对较长时间范围内的用户行为进行建模5。异常检测也可以使用半监督和非监督机器学习算法,如自组织映射(SOM,Self Organizing Map)神经网络,聚类算法和一类支持向量机(SVM)。基于异常检测的且基于机器学习的IDS提供了一个系统来发现零日攻击。 但是由于这些技术在区分攻击行为和正常行为方面的存在局限性,所以有较高的误报率。 表I显示了误用检测和异常检测方法之间的区别。
混合检测方法将误用和异常检测方法集成在一起以检测攻击。 第五部分介绍了这些方法的详细信息。通常,与传统的基于特征的IDS相比,使用基于机器学习的IDS的一些优势如下:
- 在攻击模式中进行一些细微的改变,可以很容易的绕过基于特征的IDS,而基于监督学习的IDS可以在学习流量的行为时,可以轻松检测到攻击行为的变化。
- 在基于机器学习的IDS中,CPU负载相对较低,因为它们不像基于特征的IDS那样分析特征数据库中的所有特征。
- 一些基于机器学习的IDS,尤其是基于无监督学习算法的IDS,可以检测到新颖的攻击。
- 不同类型的攻击不断发展。 基于特征的IDS将需要不时维护特征数据库并保持其最新,而基于聚类和离群点检测的机器学习IDS系统则不需要更新。
我们的贡献如下:
- 介绍了基于攻击特征的攻击分类。 讨论了机器学习技术难以检测低频攻击(如U2R和R2L,蠕虫,ShellCode等)的各种因素,并提出了提高检测率的方法。
- 对现有的入侵检测文献进行了讨论,重点介绍了关键特征、检测机制、特征选择、攻击检测能力。
- 分析了各种入侵检测技术在攻击检测能力方面的性能,还讨论了局限性及与其它方法的比较。并对每一种技术都提供了改进的建议。
- 为基于机器学习的入侵检测应用程序提供了未来的方向。
论文分为十一个部分。在第二节中与相关的调查进行比较,突出我们工作方面的具体贡献。第三节详细描述了不同类型的攻击及其特点。第四节介绍了各种机器学习技术及其特点,讨论了特征选择在机器学习中的重要性。第五节对不同的入侵检测机器学习方法进行了详细而全面的总结,第六节根据它们检测攻击的能力对它们进行了分类。第七节讨论了几种用于检测不同安全攻击的机器学习技术的性能分析。讨论了与各类机器学习技术相关的安全问题,并提出了解决方案。第八节描述了检测低频攻击时的问题,随后介绍了提高其检测率的各种有效措施。第九节讨论了用于机器学习和深度学习的各种数据挖掘工具。在第十节中,提供了未来的方向,以便对正在进行的和未来的研究工作进行简要的了解。最后,在第十一节中,提出了总结意见和今后的工作范围。
III. 具有相关攻击特征的攻击分类
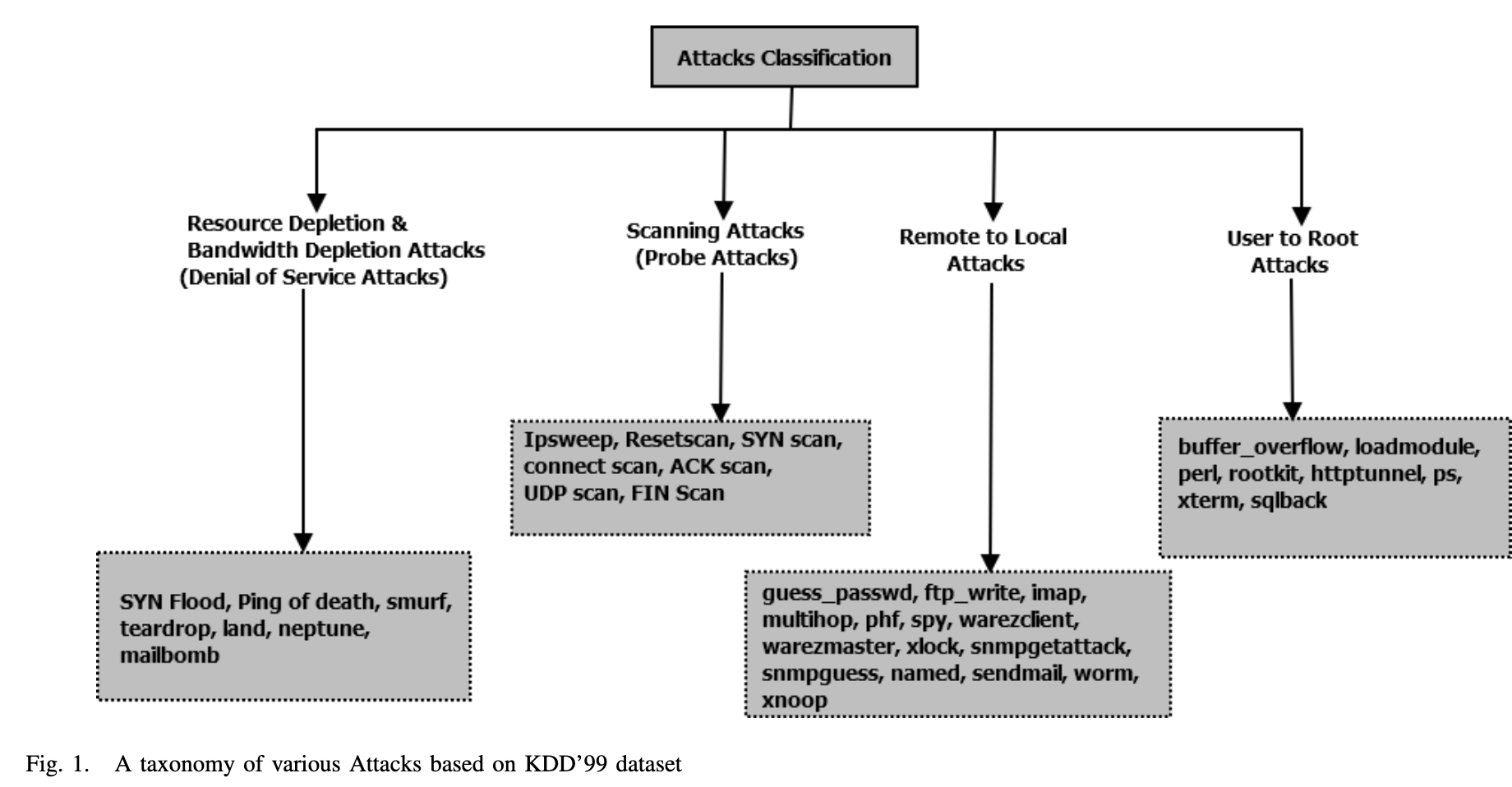
A. 拒绝服务攻击(资源耗尽和带宽耗尽攻击)
这类攻击导致合法用户无法获得服务,因此也称为DoS攻击6。让我们以攻击场景为例:攻击者可以发送多个服务请求,以向企业注册或访问企业中运行的任何有效服务实例。在这种情况下,管理服务器将疲于应对许多个服务请求,并且将无法向其他合法用户提供服务。可能还有另一种攻击场景,使用多台计算机启动DoS攻击:大量计算机连接到一个组织/企业网络。如果攻击者可以访问组织/企业的一台或多台计算机。 它可以滥用此特权,并且对同一个局域网内的其他计算机发起DoS攻击。有时攻击面非常广泛,攻击者可以占领多台计算机(僵尸机)并使用它们发起DoS攻击, 这种DoS也称为分布式拒绝服务攻击(DDoS)。 DoS攻击分为两种类型:带宽消耗攻击和资源消耗攻击。 在带宽消耗攻击中,攻击者试图通过网络数据包使网络超载。 带宽消耗攻击分为两类:泛洪攻击和放大攻击。 在泛洪攻击中,攻击者尝试发送大量的ICMP或UDP数据包来充满网络,从而导致网络资源过载。 在放大攻击中,攻击者试图利用大多数路由器的IP地址广播功能。 此功能允许发送系统将广播IP地址指定为目标地址,而不是特定地址(例如smurf 和fraggle攻击7)。 在资源耗尽攻击中,攻击者占用了受害系统的资源。 可以通过利用网络协议(例如海王星,邮件炸弹)或形成格式不正确的数据包(例如Land,Apche2,Back,Teardrop,Ping of Death等)来发起攻击,这些数据包会通过网络发送到受害计算机。 下面简要介绍其中一些攻击:
-
Land:在Land攻击中,攻击者发送伪造的SYN包,其中源地址与目标地址相同。它在某些TCP/IP实现中是有效的。
攻击特征:通过考虑特征“Land”来检测攻击。如果特征“Land”的值为1,则表示源地址和目标地址相同。因此此特征对于识别此攻击最为重要。
-
Teardrop:攻击者试图将分段的数据包发送到目标计算机。他设置片段偏移量的方式使得后续的数据包彼此重叠。如果目标操作系统的IP分片重组代码中存在错误,则可能由于不正确处理重叠的数据包而导致机器崩溃。这种攻击在很多操作系统上都是成功的(例如Windows3.1x、Windows95、WindowsNT和内核版本在2.1.63之前的Linux)。
攻击特征:特征“错误片段”是在一次连接中数据包错误校验和的总和,它提供了有关错误IP数据包的一些线索。因此,此特征对于识别此攻击非常重要。
-
Smurf:Smurf攻击是一种基于放大的Dos,攻击者将大量ICMP的echo消息发送到广播IP地址,并将受害者机器的源IP作为欺骗地址。在接收到数据包时,广播网络中的每台机器都会回复受害者的机器,使其资源变得忙碌但毫无意义8。
攻击特征:通过查看对受害者计算机的大量ICMP echo响应,而不从受害者计算机发送任何ICMP echo请求数据包,可以在受害者计算机中轻松检测到此攻击。有一些特征,如“服务”(ICMP)、“持续时间”,“Dst host same srv rate”(用于查找到来自攻击者机器的同一服务和同一目标IP地址的连接百分比)和“same srv rate”(用于查找到来自受害者机器的同一服务和同一目标IP地址的连接百分比),这在确定在一段时间内到受害者计算机的ICMP echo数据包总数以及在一段时间内从受害者计算机收到的ICMP应答数据包总数时很有用。
-
Ping of Death:Ping of Death(PoD)是一种DoS攻击,IP分组允许的最大值加上分组报头(通常为20字节)为65535字节,攻击者故意发送大于IP协议允许的65536字节的IP数据包。这种攻击会导致系统崩溃或死机。许多操作系统都易受此攻击9。
攻击特征:通过记录所有ICMP数据包的大小并标记长度超过65535字节的数据包,可以识别尝试Ping of Death。连接中的“Dst bytes”(接收的字节总数)和“Duration”功能可能有助于提供有关PoD攻击的一些线索,这意味着将在短时间内接收的字节总数与某个阈值(65535)进行比较。
-
Mailbomb:在Mailbomb攻击中,未经授权的用户向特定邮件服务器发送大量带有大型附件的电子邮件,从而填满磁盘空间,导致拒绝向其他用户发送电子邮件服务[57]。
攻击特征:此攻击可通过在短时间内查找来自特定用户的数千封邮件来识别。“目标IP”、“Dst bytes”(接收的总字节)、“服务”(SMTP/MIME)和“Dst host same src port rate”(到同一端口和同一目标IP地址的连接百分比)等是检测此攻击行为的重要特征。
-
SYN Flood:在SYN Flood中,利用了TCP/IP实现。攻击者将SYN请求发送到受害者计算机。受害者由ACK回复并等待回复。服务器在挂起连接队列中添加每个半打开连接的信息。受害者服务器系统上的半开连接最终将填满队列,系统将无法接受任何新的传入连接10。
攻击特征:SYN flood攻击可以与正常的网络流量区分开来,方法是查找从无法访问的主机发送到特定计算机的多个同步SYN数据包,或者设置时间阈值内系统必须等待应答的数据包。因此,诸如“持续时间”、“Flag”(S0:“初始SYN,但无进一步通信”等)、“Dst host count”(与同一目标IP(受害者计算机)的连接百分比)等特征对于识别此攻击非常重要。因此,注意那些在短时间内没有建立连接的情况下提升SYN标志的连接对于检测攻击是有用的。
B. 扫描攻击
扫描活动是一个网络安全方面日益关注的问题,因为它是入侵检测尝试的主要阶段,用于定位网络中的目标系统,然后利用已知漏洞进行攻击。攻击者使用nmap、satan、saint、msscan等扫描工具发送大量扫描数据包以获取有关机器的详细描述。Bou Harb和Guven11提供了有关扫描技术的详细讨论。他们将网络扫描主题分为三个部分:性质、策略和方法。扫描攻击的性质可以是主动的,也可以是被动的。攻击策略可以是远程到本地、本地到远程、本地到本地和远程到远程。他们还对19种网络扫描技术进行了利弊分类。在高层次上,这19种扫描都被分为五大类:开放扫描、半开放扫描、隐蔽扫描、sweep扫描和其他扫描。例如图二所示是开放扫描和隐蔽扫描(特别是SYN-ACK扫描)。开放扫描使用TCP握手连接。它利用SYN标志和TCP协议检测TCP端口。关闭的端口用RST 标志集(图i)应答,而打开的端口用ACK 标志集(图ii)应答。攻击者现在可以通过发送RST和ACK重置连接。防火墙可以通过查看日志来检测这种简单的扫描。隐蔽扫描推进了开放式扫描,并利用其他标志和SYN标志一起使用,以避免被检测。对于隐秘的SYN-ACK扫描,攻击者向目标发送SYN和ACK标志,关闭端口发送RST 标志(图iii),而打开端口将生成任何响应(图iiii)。
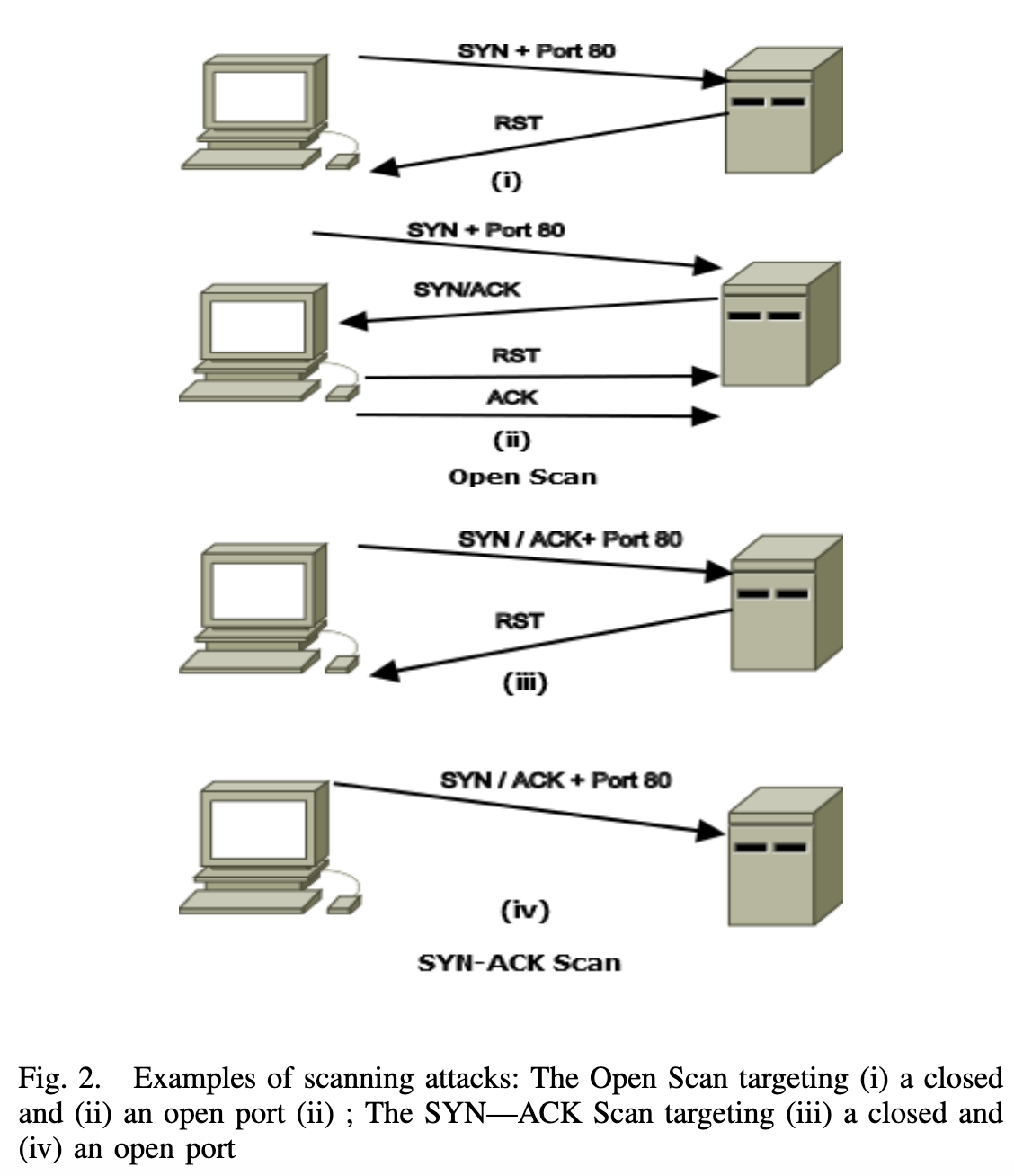
这是一个相对快速的方法,不需要三次握手或单独的SYN标志。除了给出扫描方案外,作者还解决了网络扫描时的IP版本问题。对基于扫描活动的一对一、一对多、多对一和多对多的分布式检测技术进有单独的文献综述。这些扫描在未来发动攻击时很有用12。一些扫描攻击描述如下:
-
Ipsweep:Ipsweep用于通过发送许多ping数据包来确定哪些主机正在网络上监听。如果目标主机回复,则会向攻击者显示目标IP地址。
攻击特征:IDS可以检测短时间内到达的ping包总数。“持续时间”、“服务”(ICMP)、“Dst host same srv rate”(用于查找到同一服务的连接)和“标志”(用于查找连接状态)等特征对于在短时间内查找总ping消息和当前连接状态以检测ipsweep攻击非常重要。
-
重置扫描:在重置扫描中,攻击者向受攻击的机器发送重置数据包(RST flag up)以确定该机器是否处于活动状态。如果目标机器没有发送任何重置数据包的响应,则机器是活动的。
攻击特征:可以通过检查短时间内到达具有相同服务的易受攻击机器的各种RST数据包来检测这些扫描。“持续时间”、“服务”、“标志”、“Dst host count”(用于查找到易受攻击计算机的连接总数)等特征对于查找使用相同服务协议且以较短时间有重置RST数据包的连接总数非常重要。
-
SYN扫描:SYN扫描是一种半开放式扫描攻击,因为攻击者没有建立完整的TCP连接。 攻击者将大量的SYN数据包发送到不同的端口。 打开的端口以SYN-ACK响应,关闭的端口以RST响应。
攻击特征:可以通过检查带有REJ(连接被拒绝;初始SYN发出,一个RST应答)或S1(SYN未交换任何进一步的信息)标记的半开连接来检测这种扫描。因此,诸如“持续时间”、“标志”、“Dst host diff srv rate”(到不同端口和同一目标IP的连接百分比)等是检测此攻击的重要特征。
C. User to Root 攻击
U2R攻击指的是一组漏洞的利用,用于本地用户获得对计算机的Root权限。这些漏洞以不同的方式获得对机器的Root访问权限。
例如缓冲区溢出攻击,攻击者利用用户程序的漏洞,该程序在静态缓冲区中不检查而复制过多数据。攻击者会试图操纵溢出缓冲区的数据,并导致操作系统执行任意命令。
在Ffbconfig攻击13中,攻击者利用与某些操作系统一起分发的Ffbconfig程序。攻击者覆盖ffbconfigct程序的内部堆栈空间,该程序不会对参数执行足够的检查。ffbconfig程序是快速帧缓冲(FFB,Fast Frame Buffer)图形加速器的一部分。
在loadmodule攻击中,攻击者试图利用某些操作系统中存在的漏洞进行攻击14。loadmodule程序将动态加载的内核驱动程序加载到当前运行的系统中,并在/dev目录中创建特殊设备。攻击者利用loadmodule程序中存在的错误获得对计算机的Root访问权限。
Perl攻击利用了保存在Perl的Suidperl版本中的set user ID和set group ID脚本中的错误。在此版本中,当更改有效的用户和组ID时,解释器会错误地免除root权限。
另一个例子是Rootkit攻击15,Rootkits是一种隐蔽的程序,用于向攻击者系统安装后门或隐藏入口,以绕过计算机的Root权限。Rootkits允许攻击者从机器中隐藏可疑进程并安装软件(如sniffier、keylogger),以破坏机器的安全。
攻击特征:KDD’99的特征不足以观察攻击行为,而且它的特征很难区分这些攻击。但是KDD’99中的一些特性(如“Num failed login”、“Su attempted”、“Is hot login”、“Num Shell”、“Root Shell”和“Num Root”、“Duration”和“Service”)提供了一些关于Root用户异常行为的提示,因此有助于检测U2R攻击。
D. Remote to User攻击
R2L攻击是指一组漏洞的利用,只要攻击者可以通过网络向受攻击机器发送数据包,这些漏洞组可用于获得对远程机器的访问权限。有多种方法可以发动攻击以获得对机器的非法权限。
在字典/猜测密码攻击中,攻击者重复猜测可能的用户名和密码,并使用许多提供登录功能的服务(如telnet、ftp、pop、rlogin和imap)尝试攻击。
在FTPwrite攻击中,攻击者试图利用ftp错误的配置进行攻击16。在ftp配置中,如果ftp根目录或子目录不受写保护并且位于ftp帐户的同一组中。攻击者可以将文件添加到这些目录中(如rhost文件),并获得对计算机的访问权限。
在IMAP攻击中,攻击者试图利用登录事务的认证代码中存在的IMAP服务器缓冲区溢出17,攻击者发送精心设计的文本以执行任意指令。
在Xlock攻击中,攻击者利用不受保护的X控制台来访问计算机。攻击者将修改后的xlock程序显示给用户,并等到用户在该屏幕中输入密码。 密码通过木马版的xlock程序[73]发送回攻击者。
在wazermaster攻击中,攻击者试图利用FTP服务器中存在的bug。 如果FTP服务器已授予访客帐户写权限,则攻击者可以登录FTP服务器公共域中的访客帐户,并将“ warez”(非法软件的副本)上传到服务器。 用户稍后可以下载这些文件。 Warezclient攻击是在攻击者执行warezmaster之后,合法用户在FTP连接期间发起的。 用户将从服务器上下载先前由warezmaster 创建的文件(非法软件副本)18。
攻击特征:网络连接特征不足以观察R2L攻击的行为,根据其特点也很难区分这些攻击。但是,KDD’99中有一些特征(例如“Duration”、“Service”、“Src bytes”、“Dst bytes”、“Num failed login”、“Is guest login”、“Num defected”、“Num File creation”、“Count”,“Dst host count”和“Dst host srv count”)可能提供一些有关用户在本地连接中异常行为的提示,因此有助于检测R2L攻击。
R2L和U2R攻击有一点不同。在U2R攻击中,假设用户对受害机器具有本地权限(通过R2L攻击获得)。攻击者试图在访问计算机后获取Root权限。因此在U2R的情况下,流量的特征值与正常连接相似,在这种情况下基本特征和内容特征非常重要。而在R2L攻击中,攻击者试图获得对远程计算机的访问权限。因此在R2L中所有特征都很重要。在DoS和探针攻击中,流量特征与其他特征一样非常重要。在第八节中,我们描述了使用网络攻击数据集检测这些攻击的困难。
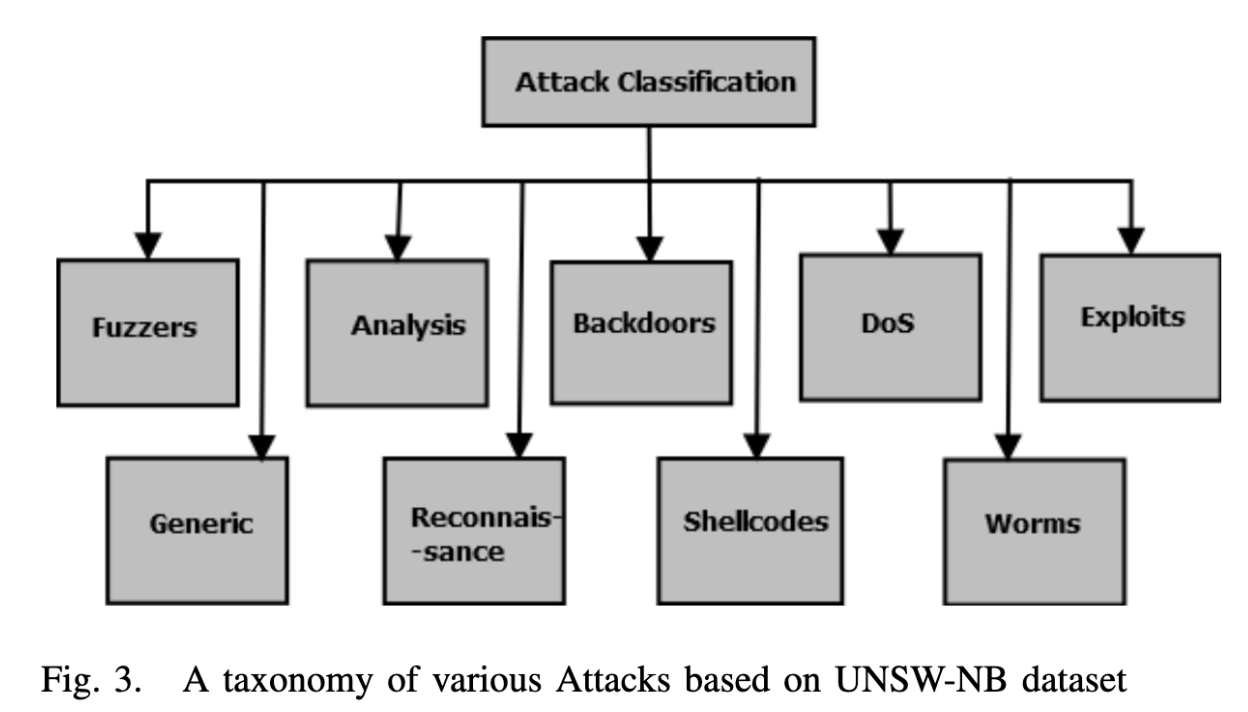
根据UNSW-NB攻击数据集,攻击分为9类,如图3所示。DoS在前面有详细描述。其他攻击描述如下:
E. Fuzzers
在Fuzzer攻击中,攻击者从命令行或以协议包的形式发送大量随机生成的输入序列。 攻击者试图发现操作系统、程序或网络中的安全漏洞,并使该服务暂停一段时间甚至直接崩溃。
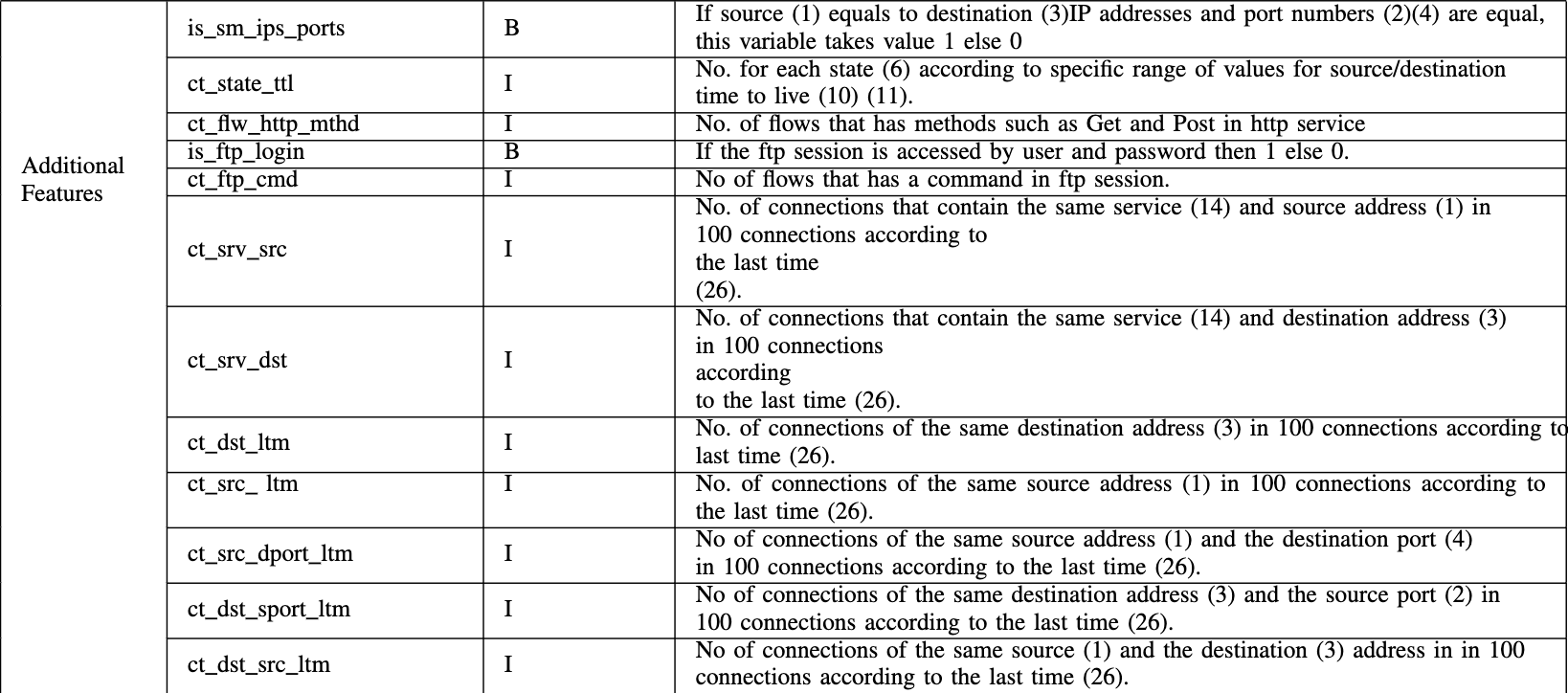
攻击特征:如果有主机在一段时间内使用相同的服务协议和/或在相同的目标端口号连续发送大量数据包,则表明可能是Fuzzer攻击。事实上一些其他特征(如源到目标的字节数、源发出的数据包的数量和流量的明显变化(或“抖动”))都可能是攻击的征兆。在这类攻击中非常有用的特性有: dur, service, sbytes, spkts, srcjitter, synack, cf_srv_src, ct_src_dport_ltm,如表三所示。
F. 分析
这类攻击是指渗透到web应用程序的各种入侵行为(例如通过端口扫描,恶意网页脚本(如HTML文件渗透)和发送垃圾邮件等)
攻击特征:在第三节(B)讨论了各种端口扫描的攻击特征和检测这些攻击的重要特征。邮件服务商虽然提供了过滤器来过滤未知来源的电子邮件,但存在垃圾邮件可以绕过这样的过滤器。因此,除了源IP地址外,还可以考虑通过表III中列出的各种的特征来分析总体网络性能。
特别是可以通过分析HTML头、电子邮件头或代码(脚本代码)来检测web应用程序攻击19。
G. 后门
在后门攻击中,攻击者可以绕过身份验证,获得对系统未经授权的远程访问。攻击者试图通过欺诈活动来定位数据,从而绕过系统的系统安全性。黑客使用后门程序安装恶意文件,修改代码或获得对系统或数据的访问。
攻击特征:特性集中必须存在的一些重要特征如下:fsport、dsport、dur、sbytes、service、ackdat、sjit、djit、ct_flw http_mthd、is_ftp_login、ct_srv_src、ct _st_ltm_g。要查找在目标机器上存在后门尝试的信息并不容易, 但是通过分析网络特征可以了解一些未授权访问的线索。
H. 漏洞利用(Exploits)
漏洞利用是指利用操作系统或软件中的漏洞、错误或故障进行攻击的入侵行为。攻击者利用对软件信息的了解发动攻击,并对系统造成危害。
攻击特征:以下特征可以检测对目标机器的漏洞利用行为:f_srcip、dstip、sport、dsport、sinpkt、synack、is_sm_ips_ports、ct_ftp_cmd、res_bdy_len、ct_src_ltm、ct_src_ltm_g(见表三)。这些特征可能会提供一些有关漏洞利用的线索。但是通过使用动态分析技术来监视操作系统的行为,可以更好地检测到漏洞利用行为。具体细节可以参考先前的文章2021。
I. Generic
针对密码系统的一般攻击会试图破坏安全系统的密钥。它独立于密码系统的实现细节,不考虑分组密码的结构。例如,生日攻击是一种将哈希函数视为黑盒的一般攻击。
攻击特征:最好考虑到一般攻击的所有可能的网络特征,在只考虑网络特征的情况下检测系统的精度就会降低。还可以使用动态分析检查在受害机器中代码的行为。UNSW-NB不提供KDD’99指定的系统特定特征,如root_login,su_attempted、Hot、Num_Shell等。
J. 侦查(Reconnaissance )
侦察是指绕过网络的安全控制收集目标计算机信息的攻击。它可以被定义为一个探测器,是为了进一步攻击而迈出的第一步。攻击者使用端口扫描系统、nslookup、dig、whois等来收集有关系统的信息。根据收集的TCP响应,我们可以对目标系统的信息进行猜测。在收集到足够的信息后,就可以发起DDoS、蠕虫、缓冲区溢出等攻击。
攻击特征:检测此类攻击的各种重要网络特征如下:fsport、dsport、srcip、dstip、dur、spkts、sinpkt、service、synack、ct_srv_src、ct_src_ltm、ct_dst_ltm_g。这些特征都提供了有关源和目标系统的网络信息。有关各种端口扫描攻击、相应的特征和攻击特征的详细信息参见第三节(B)。
K. Shellcode
Shellcode被用作在目标计算机中执行并利用软件漏洞的有效负载。因为它启动了一个受攻击者控制的shell,所以它被称为Shellcode。本地shell代码试图利用计算机上高特权进程的漏洞(例如bufferoverflow)进行攻击,远程shellcode对远程系统上易受攻击的进程进行攻击。成功执行时攻击者会获得对计算机的远程访问权限。例如,bindshell将攻击者连接到目标计算机的某个端口。
攻击特征:对分析此攻击很重要的一些特征有:fsport、dsport、srcip、dstip、dur、service、sbytes、dbytes、state、res_bdy_len、synack、is_ftp_login(见表三)。网络特征可能有助于检测远程shellcode。然而,为了降低误报警率和和提供良好的准确性,可以对程序进行行为分析来检测shellcode。这些类型的攻击属于低频攻击的范畴,攻击者只需几次尝试就可以与远程机器建立网络连接。
L. 蠕虫
蠕虫是指一种恶意程序或恶意软件,可以自我复制并传播到其他计算机上,它利用网络来传播攻击。大多数蠕虫都都设计为仅复制而不试图更改系统文件,但是它们会通过增加网络流量而导致服务中断。
攻击特征:重要的网络特征如下:srcip、dstip、sport、proto、spkts、dpkts、tcprtt、stcpb、dtcpb、ct_srv_src、ct_flw_http_mthd、is_ftp_login等(参见表三)。这有助于分析在一段时间内使用特定服务和因特网协议(IP)从同一源地址发送的数据包的传播情况。
网络攻击是指故意破坏或未经授权访问机器或以未经授权访问用户数据的行为,攻击目标一般是计算机网络和/或计算机,并损害其资源。在我们的研究中已经讨论了各种攻击。每一次攻击都是以某种方式发动的,并带有一些独特的特征,对于检测特定类别的攻击来说至关重要的网络特征也被映射到特定的攻击类别。KDD’99已被大多数研究所采用,因此我们在研究中考虑了它。然而由于它非常古老,我们还考虑了一个非常新的IDS攻击数据集,即UNSW-NB,它包含十类攻击。ISCX-IDS攻击数据集22不公开,但我们根据要求从新不伦瑞克大学(UNB)以PCAP文件的形式获得了这个数据集,但作者未提供攻击特征及其描述。因此本研究仅考虑了KDD’99和UNSW-NB。
IV. 机器学习:技术与特征选择
在本节中,我们讨论了用于检测入侵的各种最流行的机器学习技术。这些技术具有不同的特点,为入侵检测提供了不同的结果。在这里我们提到了这些技术的工作及其特点,我们进一步描述了各种特征选择方法的优缺点,并为每一次攻击提供了最优特征集。
A.机器学习中的技术
机器学习分为两个阶段:训练和测试。在训练阶段,他们在训练数据集上执行计算,并学习一段时间内的流量行为。在测试阶段,测试实例根据学习到的行为被划分为正常行为的或入侵行为。各种流行的机器学习技术描述如下:
1)决策树
2)人工神经网络
3)朴素贝叶斯分类器
4)支持向量机
5)遗传算法
6)K-means聚类
7)K近邻法
8)模糊逻辑
9)隐马尔科夫模型
10)集群智能
11)集成学习
B.机器学习中的特征选择
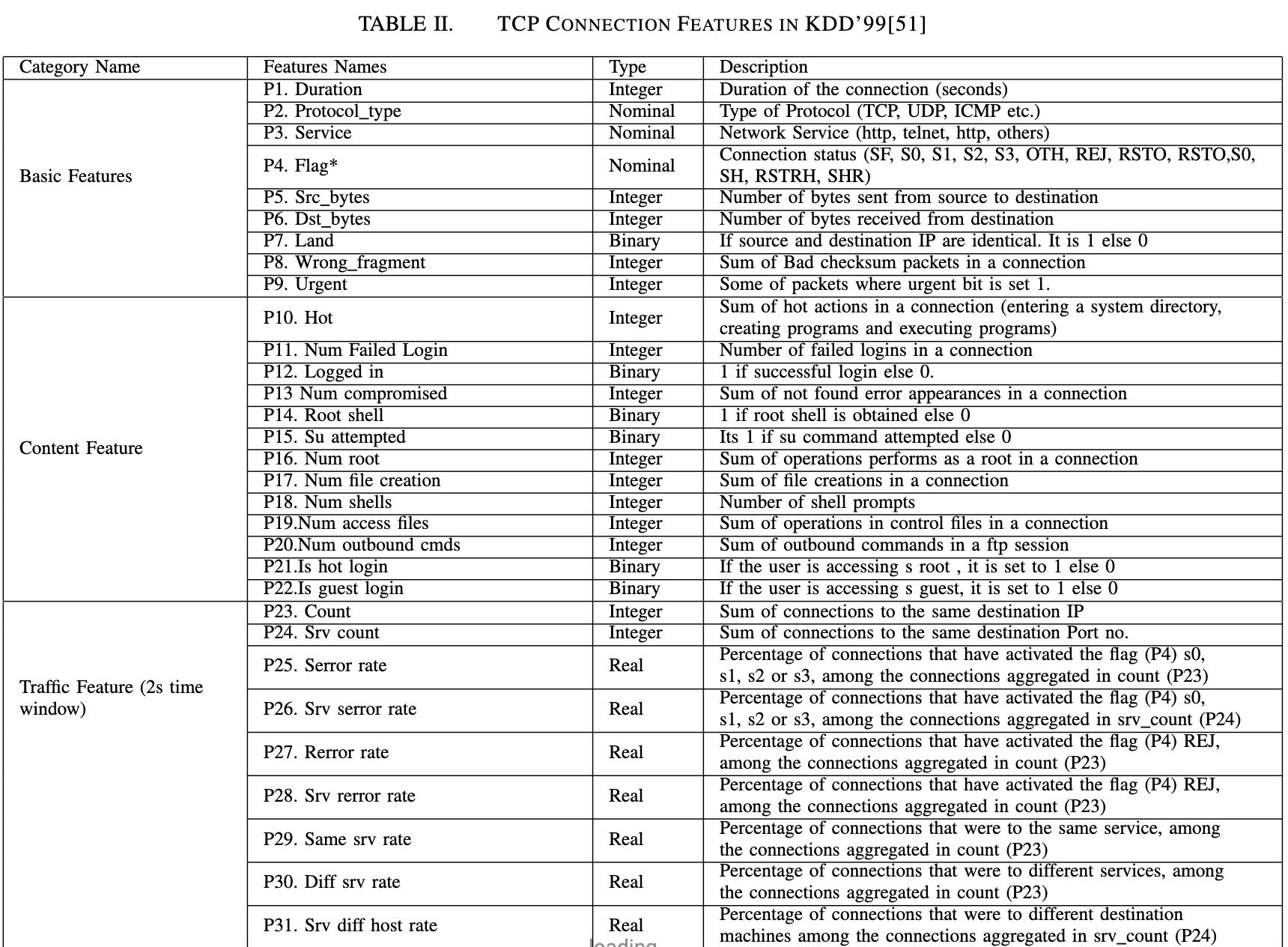
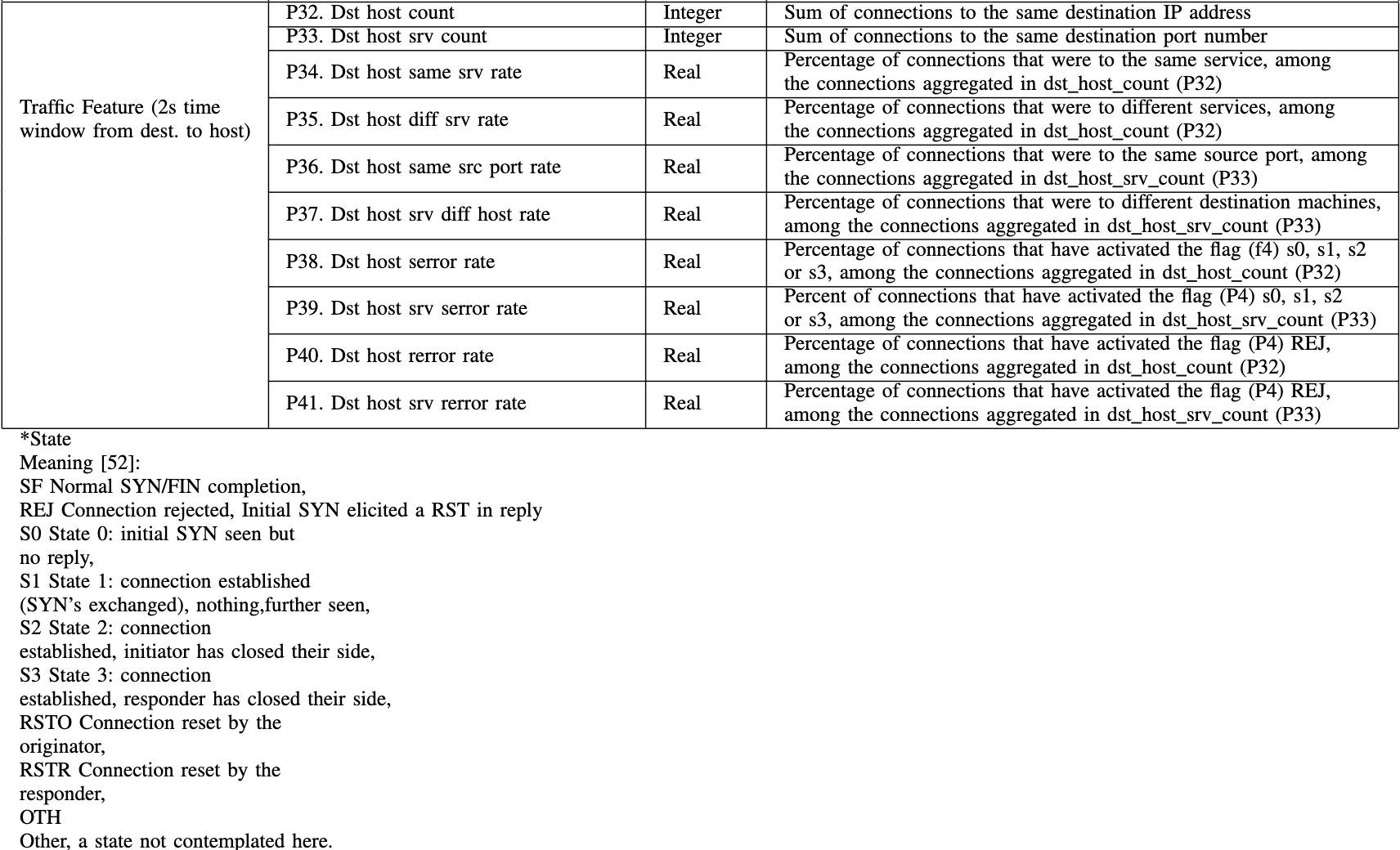
共有41个功能。表二将所有特征分为四大类:
- 基本特征(1-9):指单个TCP连接的基本特征。
- 内容特征(10-22):从包的数据部分提取内容特征。这些特性对于检测诸如U2R和R2L之类的低频攻击非常重要,这是因为DoS和Probe通常在较短的时间内涉及大量连接,而R2L和U2R通常涉及单个连接,并嵌入在数据包的数据部分中。
- 流量特征(23-31):使用2秒时间窗口计算流量特征。这些对于检测高频攻击(DoS和Probe)非常重要。
- 流量特征(32-41):从目标到主机的2秒时间窗口计算的流量特征。这些对于检测高频攻击(DoS、探测)非常重要。
V. 基于单/多分类器机器学习方法的入侵检测综述
最初,单分类器被用来对入侵进行分类,但是它们缺乏对入侵行为进行正确分类的能力。于是又提出了特征选择方法以提高检测率和降低计算量,但分类正确率没有明显提高。随后一些研究者选择数据集的41个特征,将单个分类器结合起来提高了入侵检测率,但该技术存在检测率低、计算量大等局限性,特别是对于低频攻击。在一些方法中特征选择与多分类器结合使用,大大提高了对各种类型攻击的检测率,然而因为需要经过分类器模块的多重处理,在计算成本上并没有显著的降低。随着机器学习技术在入侵检测领域的逐步发展,我们将其分为四类:
-
具有所有特征的单分类器
-
具有有限特征的单分类器
-
具有所有特征的多分类器
-
具有有限特征的多分类器
A. 具有所有特征的单分类器
在IDS中引入单分类器是利用机器学习技术进行入侵检测的第一步。Kim等人23提出了一种使用SVM对KDD’99数据集进行误用检测方法。在最初的步骤中,它从KDD’99收集训练和测试数据集。数据集经过预处理以供SVM分类器使用。 通过训练集对SVM进行训练生成了决策模型。该决策模型对应于具有某些支持向量和权重向量值的特征空间中的超平面。在学习过程中,C值分别取1500、1000和核函数(例如线性、2-poly和径向基函数(RBF))。系统通过调整C和核函数的不同值来验证哪个核函数是有效的。在验证过程中,测试实例被传递给经过学习的分类器以检查分类的准确性。从检测率和误分类率两个方面对其性能进行了比较,该分类器在检测扫描攻击和低频攻击时效果不佳。该方法检测DoS的检测率为91.6%,Probe攻击的检测率为36.65%,U2R攻击的检测率为12%,R2L攻击的检测率为22%。研究人员还没有给出错误警报的结果。
Amor等人24分别使用两种不同的误用检测方法(朴素贝叶斯和决策树分类器)进行入侵检测,并比较它们的性能。KDD’99数据集用于训练和测试。决策树算法根据数据集的值建立树,每个非叶节点对应于测试属性,而每个分支代表测试属性的输出。根据熵和信息增益,选择合适的测试属性。叶节点表示对象的最后一个类,决策树生成从根到叶的遍历规则。在Naive Bayes中,计算与每个类标签对应的测试实例的每个属性的条件概率,后验概率的乘积有助于确定最终的类。学习阶段结束后,将测试实例传递给分类器,根据检测率检查分类的正确性。两者在检测低频攻击(U2R和R2L)方面的性能都非常差。NB对DoS的检测率为96.65%,对Probe攻击的检测率为88.33%,而DT对DoS的检测率为97.24%,对Probe攻击的检测率为77.92%。两种方法的检出率均较低(0.53%-11.84%),如表五所示。
Bouzida等人25分别使用bp神经网络分类器和决策树进行误用检测,并比较了它们的性能。他们在KDD’99的数据集上进行了训练和测试。在神经网络训练之前,输入层神经元的数目被定义为输入变量的数目。输出层中的神经元数量等于类的总数。他们只考虑一个隐藏层,神经网络在检测DoS和探针攻击方面表现良好,但无法检测到低频攻击,因为这些攻击的记录数比其他攻击(DoS和Probe)少得多。为了改进算法,他们提出了一种改进的决策树C4.5。在改进的算法中,将默认的实例处理方式改为视作新的类别,而先前的处理方式是按普通类处理,因此任何与规则不匹配的新实例都将被视为可疑的。改进的C4.5算法也为低频攻击提供了改进。DT对DoS的检测率为99.99%,对probe的检测率为99.78%,对U2R的检测率为90.39%,对R2L的检测率为98.93%。
Tajbakhsh等人26利用KDD’99数据集,提出了基于模糊关联规则的误用检测算法。在训练阶段,成员函数用于执行特征到项目的转换,每个属性-值对都称为一个项。模糊成员函数是基于模糊C均值(FCM)聚类算法的。在下一阶段的训练中,生产的项目将减少。KDD’99包含189项,所以无法生成189项以上的规则,因为规则是基于最小支持度和置信值生成的。利用模糊关联规则建立分类器,通过规则集,实例被分配了一个标签。在测试阶段,测试实例的每个特性都使用成员函数转换为项。训练数据集分为5组(正常、DoS、探针、U2R和R2L),每一个类都制定了规则。该分类器的总执行时间为500s,但对任何一种攻击检测都没有很好的效果。DoS攻击检测的检测率为78.9%,Probe攻击的检测率为88.5%,U2R的检测率为68.6%,R2L的检测率为6.2%。总检出率为70%-90%,假阳性率为2%。
Kumar和Yadav27提出了基于神经网络的最简单的误用检测系统模型。在第一阶段,选择并准备好数据集以进行训练和测试。在此之前需要对所选数据进行预处理以使其与神经网络兼容,方式是将所有符号值转换为数值(例如ICMP=1、TCP=2和UDP=3)。在此之后执行归一化步骤,即为每个特征值计算Z-score值。接下来神经网络将在转换后的数据集上进行训练,它由输入、隐藏和输出三层组成,分别有41、29和5个神经元。学习后的分类器在测试集上的测试结果表明,神经网络在除了低频入侵(U2R和R2L)以外的其他方面都表现良好。
Amoli等人28提出了一种基于无监督聚类的异常检测方法,该方法基于异常检测对DoS、DDoS、探测攻击进行检测和分类。该模型由两个检测引擎组成,在正常或加密通信中监测和检测网络的行为,第一个引擎计算一个自适应阈值来检测由DoS、DDoS、scanning和worm等攻击引起的网络流量变化,聚类分两步进行:网络流量不超过阈值时,引擎根据DBSCAN算法对正常流量进行聚类。聚类算法计算网络实例的可接受距离,并将这些点放入聚类中。一旦流量通过阈值,就再次为异常值聚类,跨越可接受距离的点被视为异常值。第二个引擎旨在检测僵尸主机,第一个引擎将带有攻击详细信息的IP地址发送到第二个引擎,然后该引擎将数据包关联起来,以找到控制DoS的主系统。他们用ISCX数据集来验证这种方法。其正确率(accuracy)为98.39%,召回率为100%,精度(precision)为98.12%,TNR为96.39%,FPR为3.61%,优于K-均值异常检测。
Bhamare等人 29提出了使用机器学习检测网络中的攻击。他们使用KDD’99以外的两个新的网络数据集(即UNSW-NB15和ISOT数据集)执行了各种机器学习算法。这些是动态生成的新数据集,提供了真实的攻击统计信息。 带有RBF,多项式核,线性核的三种不同内核的各种误用检测算法,例如DT,NB,LR和SVM。 DT提供88.87%的准确度,NB提供73.8%的准确度,具有RBF内核的SVM提供70.15%的准确度,具有多项式内核的SVM提供68.06%的准确度,具有线性核的SVM提供69.54%的准确度,LR提供89.26%的准确度。 DT提供6.9%的FPR,具有RBF功能的SVM提供4.1%的FPR,具有poly功能的SVM提供53.3%的FPR,具有线性功能的SVM提供50.7%的FPR,NB提供7.3%的FPR,LR提供4.3%的FPR。 可以说,低FPR的Logistic回归都能提供更好的结果,然而使用简单的机器学习方法结果并不是很好。
Jazi等人 30提出了一种使用无参数的CUSUM算法检测应用层DDoS攻击的新方法。 作者研究了十三种采样技术以对数据进行过滤,他们观察到选择性流采样和sketch-guided采样技术表现更好且最有效。 选择性采样以100%的准确度提供最佳性能,并且采样率在20%以上无误报。 通用的sketch-guided采样也为检测应用层攻击提供了良好的结果。 sketch-guided采样提供了92%的检测率和40%的采样率。 作者使用不同的工具生成了各种DoS攻击跟踪,并将ISCX数据集中的攻击流量与正常流量混合在一起。
Wang等人31提出了一种将支持向量机(SVM)与数据转换方法相结合的入侵检测框架。算法中加入了特征依赖的依赖性。采用对数边际密度比变换(LMDRT,Logarithm marginal density ratios transformation)方法对进行数据变换,这样提供给支持SVM的特征经过增强具有更好的质量。LMDRT方法是由Naive Bayes分类驱动的,因为它考虑了边际密度比。利用NSL-KDD 99数据集对该框架进行了评估,准确率99.31%,检测率99.20%,误报率0.60%。
总结:本节讨论了基于单分类器的各种入侵检测技术。 单分类器简单易懂,但是其局限性(例如对输入参数选择的敏感性,核函数的选择,训练变量的数量和过拟合等)使其难以获得良好的评估结果。 其次数据集如果具有太多特征,则分类器很难快速提供分类结果,而单分类器算法与特征选择算法结合使用时可降低计算成本,这将在下一部分中进行讨论。
B. 具有有限特征的单分类器
特征选择技术与单一分类器方法一起使用可以改善性能。 Sangkatsanee 32提出了一种基于决策树C4.5的实时入侵检测系统(RT-IDS),可以检测两种不同类型的网络入侵:DoS和Probe。 该方法在上下文中进行误用检测。 该框架包括三个阶段:数据预处理、分类和后处理。 在预处理阶段会使用一个数据包嗅探器,该嗅探器使用Jpcap库和网络信息来提取IP头,TCP头,UDP头和ICMP头等,数据包的信息会包括源IP和目标IP之间所有数据包的信息。 作者使用信息增益来提取表VII中所示的12个特征。 分类阶段在已知标签的训练集上对分类器进行训练。 在测试阶段,模型将测试实例分类为正常或入侵。 后处理用于减少误报,在此阶段源与目标之间的网络数据被分为五组,如果其中的3-5个组都被分类为攻击类型,则将该记录视为攻击类型。这项技术并不检测低频攻击,但仅耗时2秒的计算就可以实现对其他攻击的检测率高于98%。它在检测Dos攻击时有99.434%的检测率和0.73%误报率,并以98.868%检测率和0.9%误报率检测探针攻击。
Amiri33提出了改进的基于相互信息的特征选择方法(MMIFS,Modified Mutual Information based feature selection approach),并将其与SVM相结合以检测低频攻击为主的攻击。他们使用了KDD’99的训练和测试数据集。在初始阶段,通过将每个属性值除以其最大值来进行数据归一化和归约。在下一阶段,对导入的训练数据进行特征选择,MMIFS先特征集设置为空。它计算特征与类别输出的相互信息,并选择具有相互信息的值最大的第一个特征。然后在特征之间计算相互信息,并选择那些满足作者在其工作中解释的特定标准的特征,重复此步骤直到拥有满足了所需数量的特征。最后一组作为输出提供给用户,其包括8个DoS特征、12个Probe特征、14个U2R特征和12个R2L特征。这些特征如表七所示。在训练阶段,对五个不同的数据集(Normal、DoS、Probe、U2R和R2L)训练五个支持向量机。在测试阶段,攻击样本被提供给每个经过训练的分类器,这些分类器将攻击样本分为五类。该方法对任何一种攻击都不能达到90%以上的检测率,并且对U2R攻击的检测率最低(30.70%)。
Lin等人34提出了一种新的基于距离的特征提取方法(CANN),该方法与基于k-NN算法的异常检测方法结合来检测入侵。在第一阶段,利用聚类算法对训练数据进行聚类,然后利用两个距离确定新的特征值:一个是特定数据点与其聚类中心之间的距离,另一个是特定数据点与其最近邻之间的距离。然后新的基于一维距离的特征值被表示为训练数据中的每个数据点。在下一阶段中,主成分分析(PCA,principal component analysis)被用来选择相关特征,如表七所示只选择了6个特征。另一个阶段是分类阶段,用新的训练数据集训练k-NN分类器。在测试阶段再次对测试数据进行CANN处理,并使用一维特征空间表示测试数据,k-NN分类器对测试数据进行分类。最后分类器的总检出率为99.99%,准确率为99.76%,误报率为0.003%,它对DoS和探针攻击检测的准确率均达到99%,但它不能够检测低频攻击。
Koc等人35使用了隐式朴素贝叶斯分类器(它是朴素贝叶斯分类器的扩展)用于误用检测。在该框架的第一阶段,首先使用熵最小化离散化和比例k-区间离散化将属性值转换为离散值。在下一阶段采用了三种方法进行特征选择:基于相关性(CFS)、基于一致性(CONS)和交互方法。作者测试了各种离散化方法和特征选择方法与分类器的组合,以得出具有高检测精度的最佳方法。分类阶段使用隐式朴素贝叶斯分类器从训练数据中学习攻击样本的行为。朴素贝叶斯(NB)分类器是基于属性之间独立关系的假设,而隐式朴素贝叶斯(HNB)放宽了这一假设,扩展了后验概率计算公式,该公式还考虑了概率计算过程中属性的相互信息。在测试阶段,根据学习到的行为对测试实例进行分类。在入侵检测中,属性值在很大程度上互相依赖,例如我们想在一段时间内检查一些登录失败的行为,在这里内容特征(登录失败数)值和基本特征(持续时间)值都会影响输出值,并且。因此,HNB可以提高朴素贝叶斯进行入侵检测的性能。利用KDD’99数据集测试,DoS检测率为99.60%,总体检测率为93.72%。
Gharaee等人36提出了一种新的基于特征选择的入侵检测模型(GF-SVM),其中将遗传算法(GA)和SVM结合到一起以提供最佳的特征集。作者对遗传算法的适应度函数做了一些小的修改,他们没有使用特征的准确性和数量(NumF)作为适应度函数的参数,而是使用了TPR,FPR和NumF这三个参数,每个参数都将根据用户的选择乘以一定的权重。在GA的每次迭代中,将评估每个染色体,并选择分类精度最高的染色体(使用SVM)。最佳的特征用于对数据集进行过滤,最小二乘支持向量机(LSSVM)用于学习/测试具有选定特征的训练/测试数据集。他们考虑了正常攻击的7个特征和不同类型攻击的6-14个特征。使用UNSW-NB15数据集的结果表明:检测正常流量的准确率为97.45%,TPR和FPR分别为98.47%和0.04%。对各类攻击的检测准确率为79.19%~99.45%,TPR为67.31%~100%,FPR为0.01%~0.09%。
Akashdeep等人 37提供了一种使用ANN与特征约简方法相结合的入侵检测方法。 首先分别根据信息增益方法和相关方法对原始数据集的所有特征进行排名。 使用每种方法构建三个特征子集,即IG-1,IG2,IG3和CR1,CR2,CR3。 每个类别下的第一个子集包含排名1-10的特征,第二个子集包含第11-30个特征,第三个子集包含其余特征。 使用联合运算&将每个类别的第一子集合并,使用相交将每个类别的第二子集进行合并,其余子集将被忽略,最终获得特征子集(共25个,如图9所示)。具有25个特征的精简KDD’99数据集用于训练ANN分类器。 它为U2R提供86.6%的检测率,为DoS提供93.8%的检测率,为R2L提供91.9%的检测率,为Probe攻击提供89.8%的检测率。
Ambusaidi等人38提出了一种基于柔性相互信息(MI)的特征选择(FMIFS)算法,该算法可以有效地处理线性和非线性特征。 FMIFS通过删除最不相关的特征来进行特征选择。 然后通过基于机器学习的网络入侵检测技术,尤其是基于最小二乘支持向量机的IDS(LSSVM-IDS),对过滤后的数据集进行评估,根据KDD’99数据集它提供了99.46%的检测率,0.13%FPR和99.79%的准确性。 使用NSL-KDD’99数据集评估时,它有98.76%的检测率,0.28%的FPR和99.91%的准确性。 它的性能优于MIFS和基于灵活线性相关系数的特征选择(FLCFS)等其他方法。
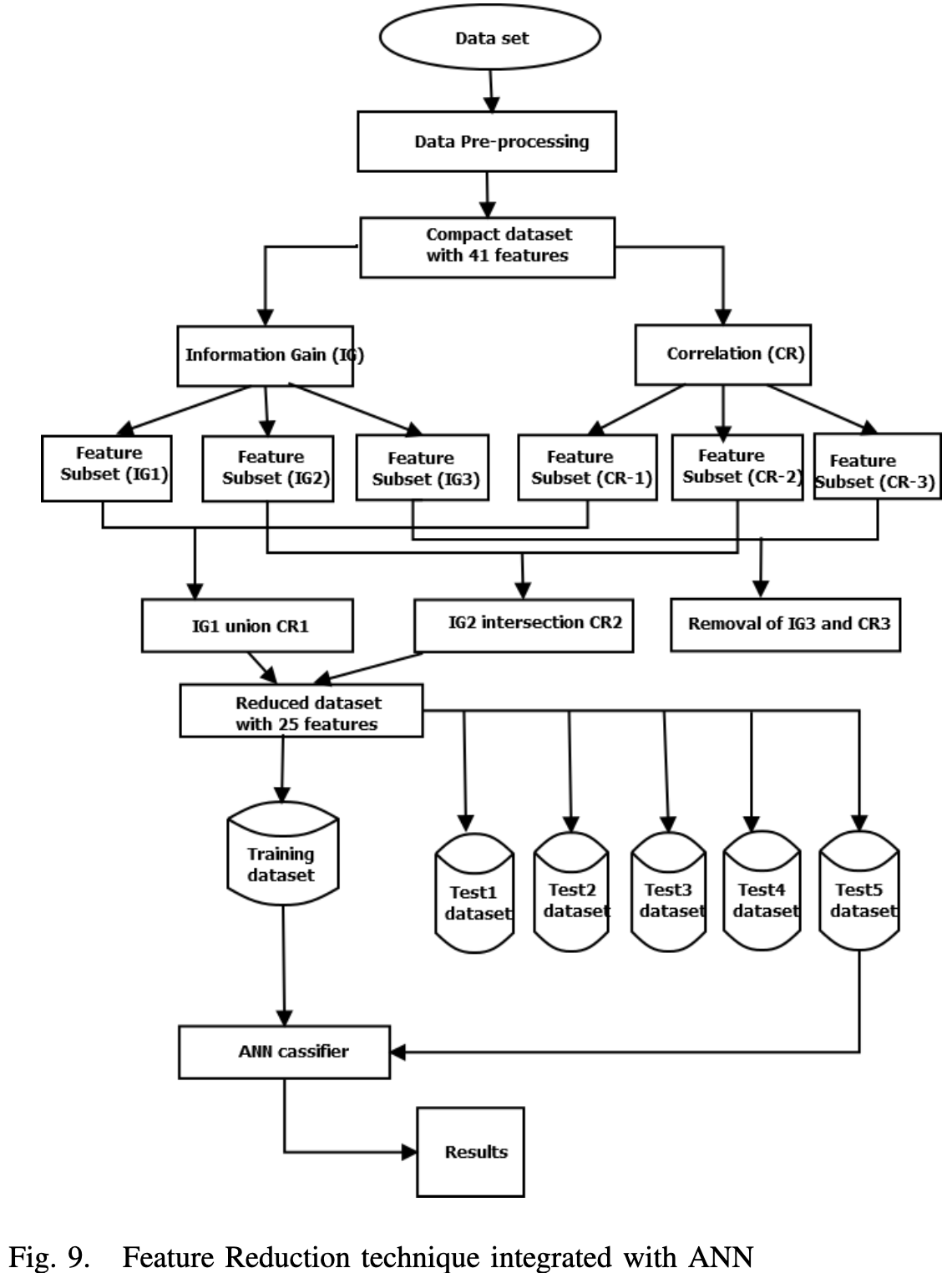
总结:本节讨论了基于单分类器和特征选择算法的各种入侵检测技术。应用特征选择虽然提高了分类的性能, 但还需要考虑特征选择和机器学习算法的不同组合,研究哪一种才能够提供最好的结果。这种方法使分类器在选定的一组特征属性上运行得更快,但对分类结果改善的不明显。当与多个分类器算法相结合时可以克服使用这种方法的缺点并改进分类结果,这将在下一节中详细讨论。
C. 具有所有特征的多分类器
Kumar等人 39了一种多目标遗传算法(MOGA,multi-objective genetic algorithm )用于误用检测,它生成多个基本分类器,然后选择分类器的子集来集成。
Mukkamala等人40提出了结合人工神经网络(ANN)、SVM和多元自适应回归样条(MARS)的集成方法。
Zhang等人41提出了基于多个径向基函数的神经网络(RBF NN)和串并行聚类算法的层次混合框架来进行误用检测和异常检测。
Toosi等人 42提出了一种神经模糊分类器,它将模糊逻辑与神经网络相结合而不使用任何特征选择技术。
Khan等人 43提出了一种混合检测方法,即使用DARPA 1998将SVM与分层聚类CT SVM进行集成,分层聚类可减少SVM的训练时间并提高其入侵检测的效率。
Tong等人 44提出了一种入侵检测系统,该系统使用DARPA 1998将径向基函数神经网络(RBF NN)与Elman网络集成在一起。
Wang等人 45提出了一种集成的混合入侵检测方法,该方法由神经网络和名为FC-ANN的模糊聚类算法组成。
Feng等人 46提出了一种入侵检测系统(CSVAC)进行误用检测和异常检测,由SVM和基于聚类的自组织蚁群网络(CSOACN)组成。
Elhag等人47结合了遗传模糊系统(GFS)和成对学习(一对一映射:OVO)架构。 模糊集的使用在规则集和成对学习之间创建了一个更平滑的边界,并提高了对低频攻击的检测精度。
Yassin等人48提出了一种结合K均值聚类和朴素贝叶斯分类器的混合检测方法。 异常检测和误用检测组合在一起可以检测更多的攻击,因为有些攻击可以绕过单一类型的检测机制。
总结:本节讨论了基于多分类器算法的各种入侵检测方法,分类器学习了训练数据集的所有特征,系统的精度有所提高, 但是计算成本和复杂性很高。 多分类器算法提高了检测率,特别是低频攻击(例如U2R和R2L)。组合多个分类器不一定效果更好,不同组合需要经过交叉验证。 通过将多分类器技术与合适的特征选择方法集成在一起可以提高性能和速度,这将在下一部分中讨论。
D. 有限特征的多分类器
Chen等人 49提出了一种使用DARPA 1998的基于柔性神经树(FNT)技术的误用检测方法。使用粒子群优化技术对FNT的参数进行了优化,遗传算法用于特征选择。
Xiang等人 50使用KDD’99数据集,提出了一种基于决策树C4.5和贝叶斯(AutoClass)聚类算法的混合检测算法。
Lin等人 51提出了一种使用SVM,决策树(DT)和模拟退火(SA)算法来进行误用检测,它利用了三个分类器的优势,例如SVM在对入侵进行分类方面表现出色,DT可以生成规则和SA覆盖率可以达到全局最优。
Casas等人 52提出了一种无监督的网络入侵检测系统(UNIDS),该系统使用了三种算法子空间聚类,DBSCAN和证据累计来查找离群点(EA4RO)实现异常检测,
Li等人 53提出了一种基于SVM,蚁群算法和聚类算法的混合方法来进行入侵检测。
Kuang等人 54提出了基于内核主成分分析(KPCA),SVM和遗传算法(GA)的误用检测系统。
Chandrasekhar等人 55提出了一种利用聚类(K-means),模糊神经网络和SVM的混合模型来进行入侵检测。
Horng等人 56使用KDD’99数据集提出了一种基于层次聚类和SVM的混合框架,目的是为了提高SVM的检测率并减少其训练时间。
Gupta等人57提出了一种分层的误用检测方法,通过使用条件随机字段(CRF,Conditional Random Fields)达到高精度,并且通过使用分层方法来实现高效率。
Mamun等人 58提出了一种DPI技术,该技术基于Shannon的熵来识别应用程序流(加密流量的一部分)。
Chowdhury等人59 组合了模拟退火算法(SA)和SVM来进行入侵检测。
Moustafa等人60提出了一种混合特征选择方法来减少不相关的特征,并与其他机器学习算法集成以进行入侵检测。 他们提出的NIDS架构在入侵检测时同时使用异常检测和误用检测方法。在这里,他们使用了三种算法,即期望最大化(EM)聚类、朴素贝叶斯和Logistic回归。
Aburomman等人61提出了一种基于集成机器学习的入侵检测方法,在KDD’99数据集上训练了6个k-NN和6个SVM分类器。
总结:本节讨论了各种入侵检测技术,他们基于多种分类器算法并结合了合适的特征选择方法。应用特征选择不仅分类的速度,某些情况下它还提高了检测率。然而时间复杂度并没有太大的减少,总体复杂度仍然很高,因为它由多个分类器和特征选择算法组成,但这类算法可以利用并行编程技术来减少训练时间。此外,如何对低频攻击进行良好的分类仍然是一个挑战。
VI. 特定攻击检测技术的分类
在这一部分中,我们将根据不同的攻击识别性能对各种技术进行分类。
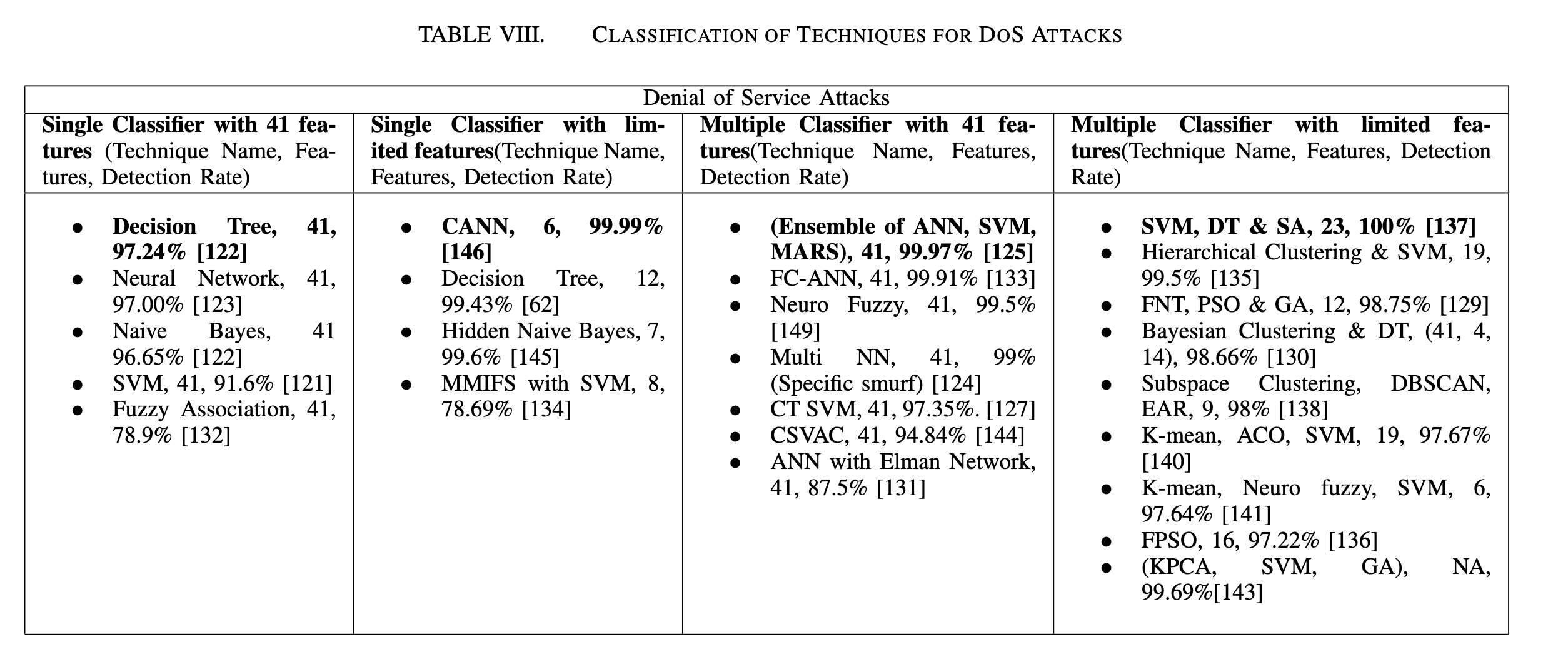
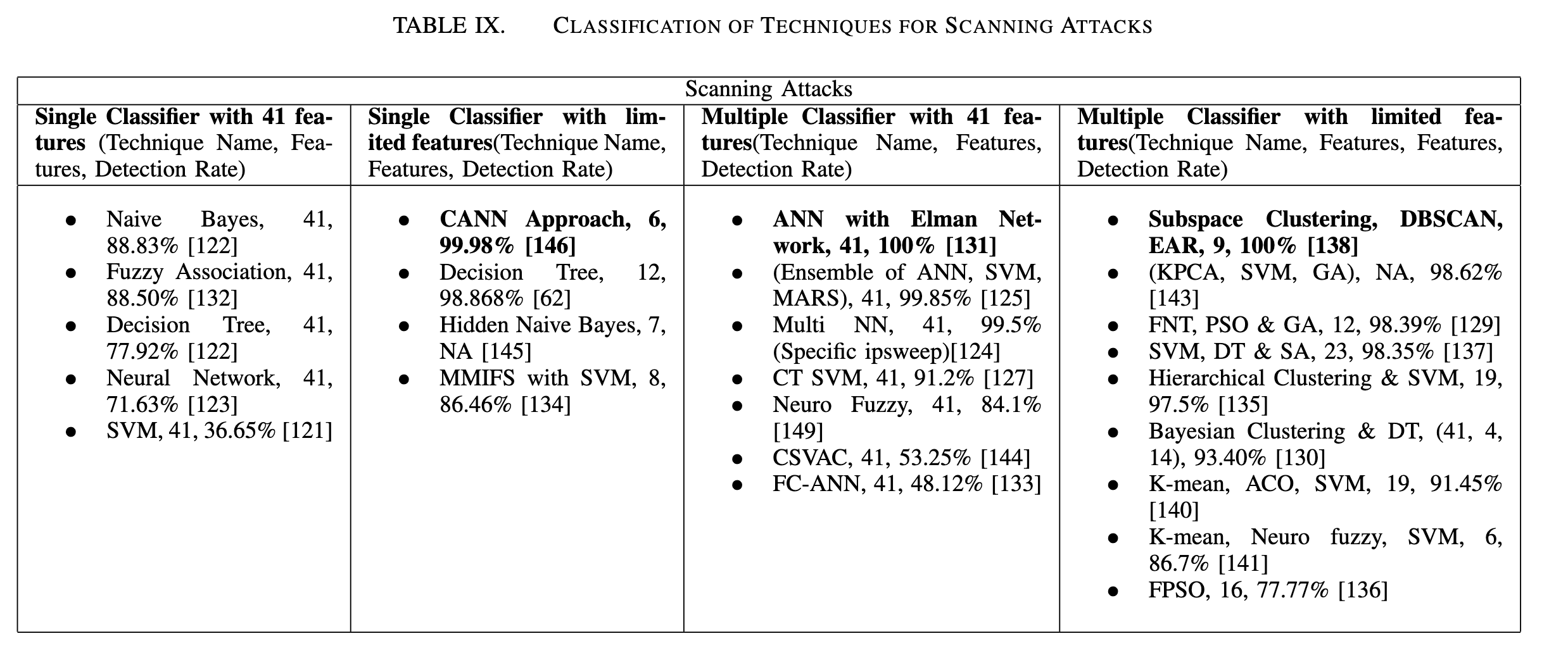
针对各个攻击类别,现在已经对基于机器学习的入侵检测方法进行了全面的分析,也讨论了每个方案的局限性,因为没有一种特定的机器学习算法可以帮助检测所有类型的攻击、所以建议使用特定算法(误用、异常或混合)来检测特定的攻击。
VII. 不同机器学习算法在入侵检测中的性能分析
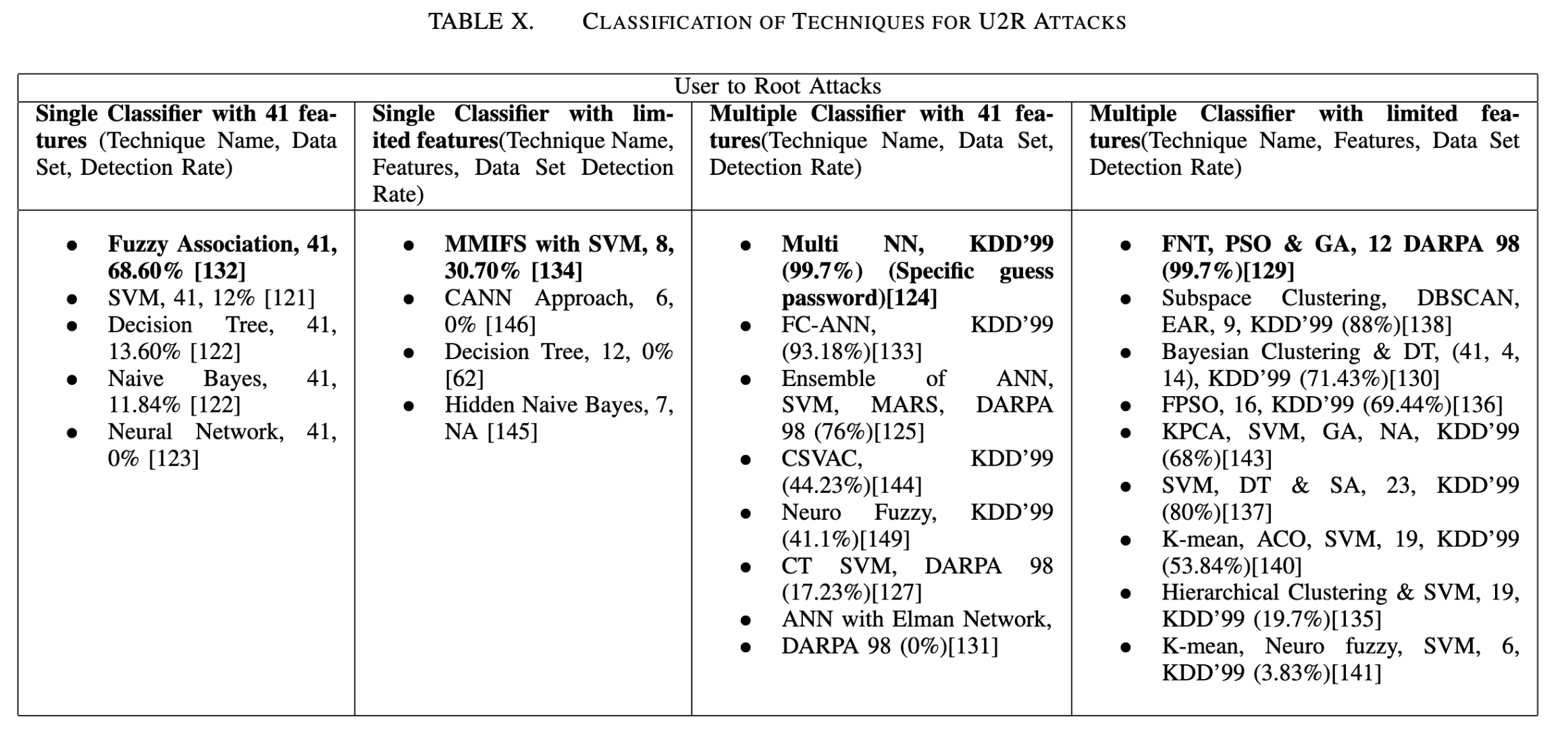
我们对各种机器学习技术在检测各类攻击时的关键性能进行了分析。
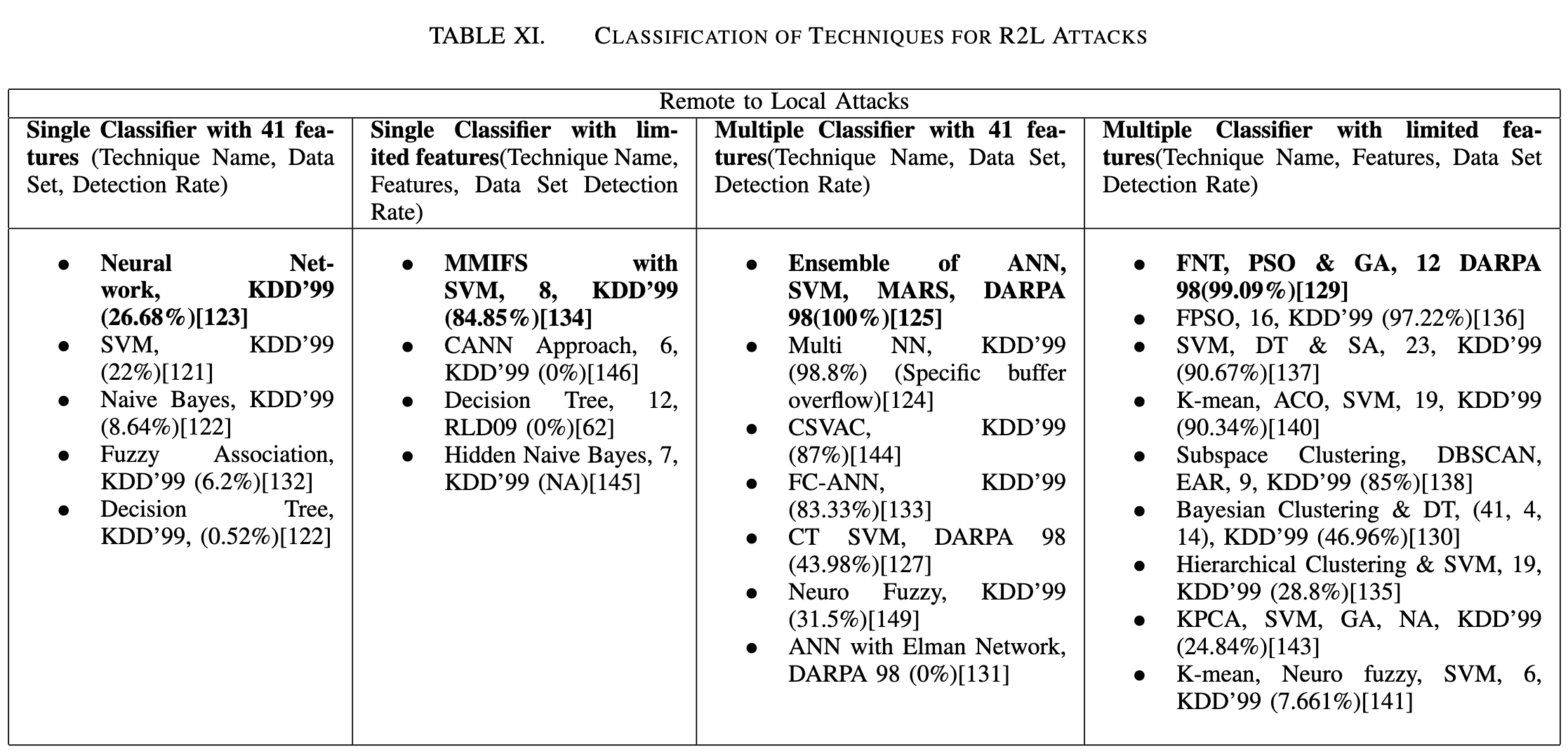
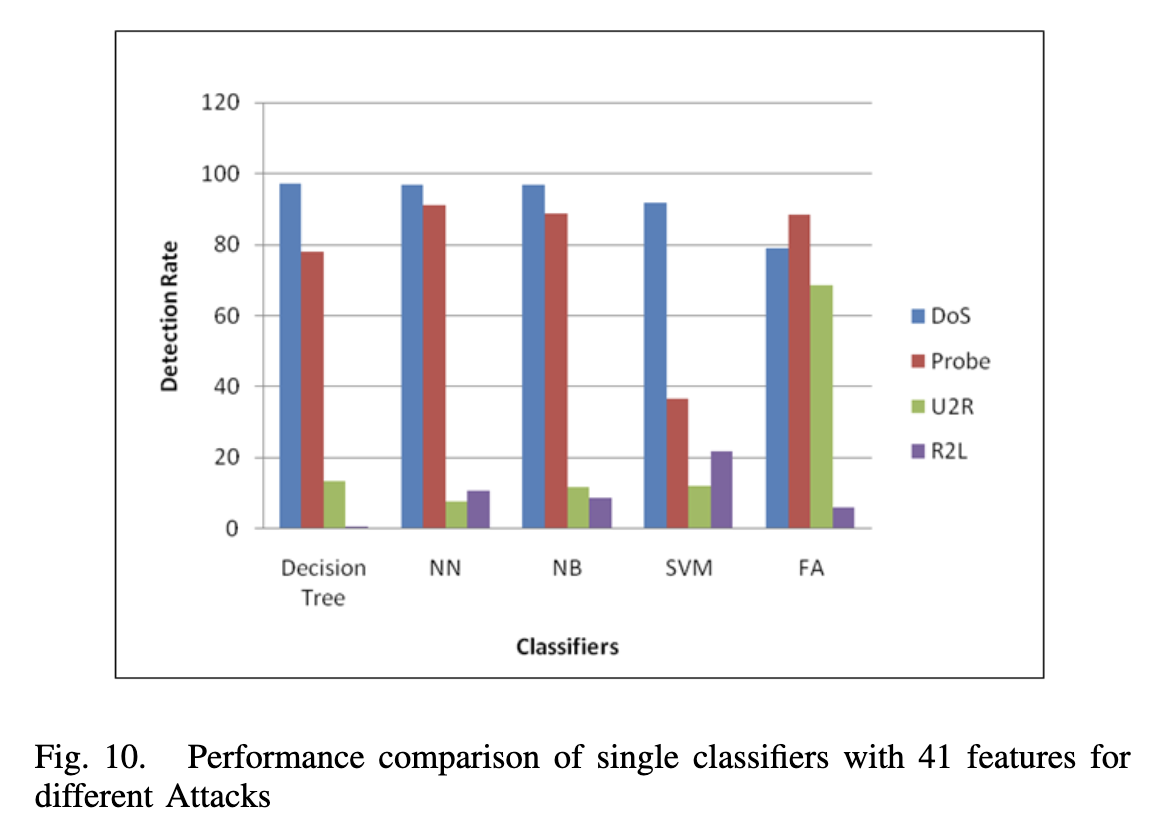
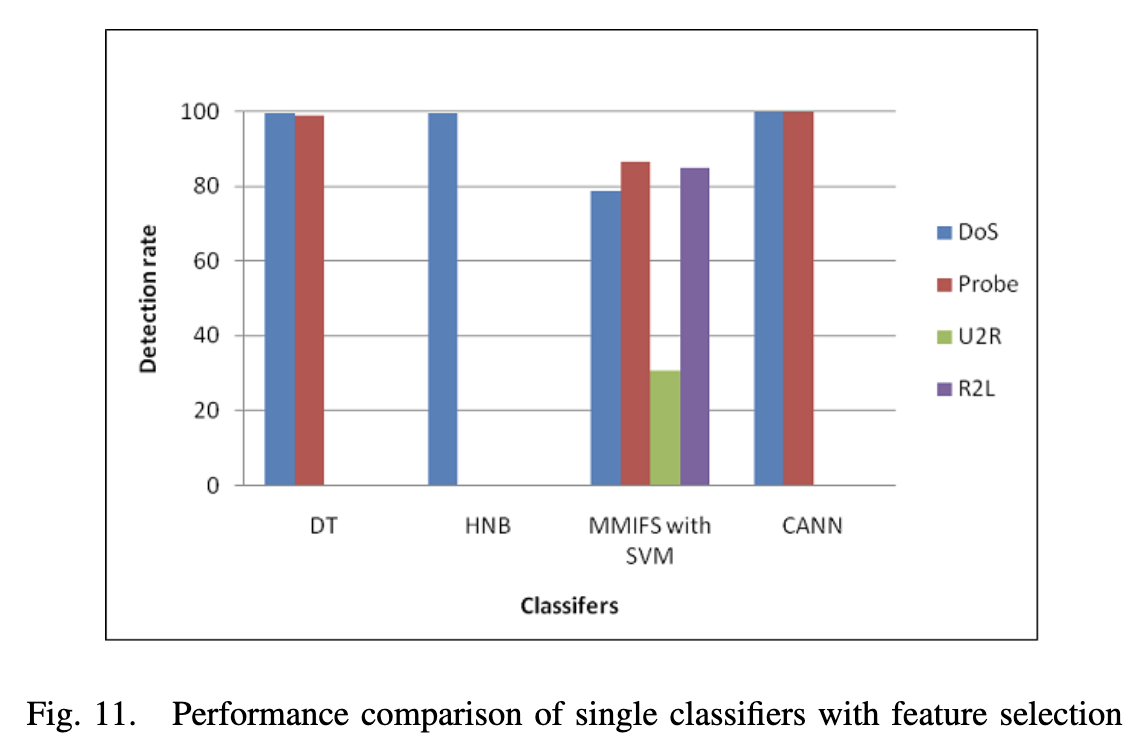
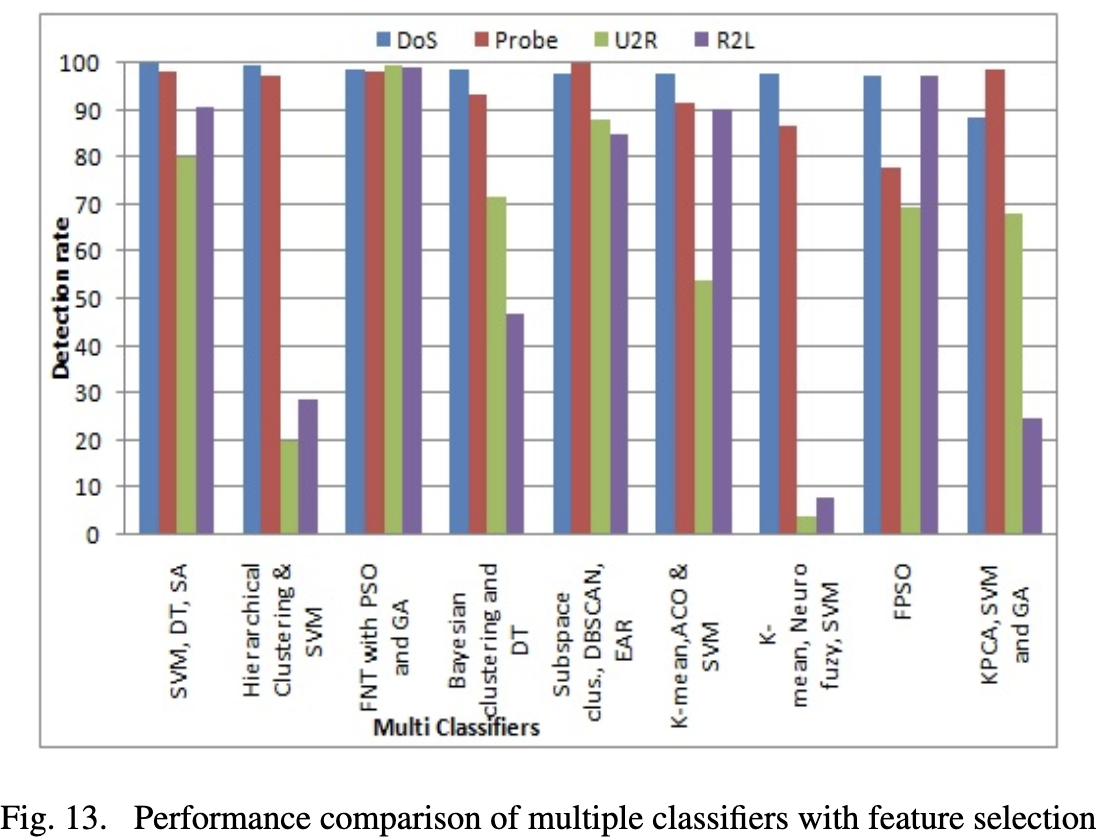
VIII. 低频攻击检测中的几个问题
使用机器学习算法对攻击数据集上的数据进行统计, 通过检查主机上的连接统计信息,可以轻松检测到DoS和Probe攻击。而即使仔细检查KDD’99上的连接统计信息,也难以检测到低频攻击(如U2R和R2L), 这是由于以下原因:
- 低频攻击的连接统计与正常的连接非常相似。
- U2R和R2L的行为非常相似,因此很难区分U2R和R2L攻击。 实际上U2R攻击是R2L攻击的变体: 在R2L攻击中,攻击者没有对计算机的访问权限。 要获取root权限,他必须先利用各种帐户劫持漏洞来获取普通帐户的权限。 在以普通用户身份登录后,他就可以发起进一步的攻击以获取root权限。
- 低频攻击可以在单个连接中发起,而 KDD’99数据集提供的信息还不够。 尽管KDD’99数据集中存在某些“内容”特征(请参阅第三节中的表II),例如登录失败的次数(P11),root shell(P14),num compromised(P13),root shell(14)等, 但是它们不足以识别低频攻击。 例如,loadmodule攻击(U2R)加载当前系统中两个可动态加载的内核驱动程序,并在/dev目录中创建特殊设备以使用这些模块。 由于loadmodule清理环境的方式中存在bug,所以普通用户可以在计算机上获得root访问权限。 在用户会话中查找关键词’set $ IFS =’V’和’loadmodule’可以检测到这种攻击,但使用KDD’99数据集的机器学习算法则很难实现这种关键词的策略。
- 与DoS和Probe攻击相比,KDD’99的训练和测试集中的U2R和R2L样本数量非常少,对此类攻击的学习不足使得分类器不太适合检测此类攻击。而且由于此类数据分布不均衡,分类器会将此类攻击视为普通攻击。
- 这些攻击活动的次数与一些正常行为(如文件创建,root 用户登录,root执行操作)的数量相似。在这种情况下识别低频攻击变得更加困难。 但是可以查看系统调用记录中是否存在特定的模块或进程、系统调用的可疑序列、特定命令的调用等。 例如,Ffbconfig攻击利用了缓冲区溢出(U2R), 它配置了快速帧缓冲(FFB)图形加速器,它是FFB配置软件包SUNWffbcf的一部分。 通过检查系统的系统调用记录中是否存在
/usr/sbin/ffbconfig/命令以及带有-dev的超大参数,可以检测到这种攻击。 - 在某些方法中检测这些攻击的准确性很高(大约90-99%),但是我们不能保证这些方法在检测未见过的或新的U2R或R2L攻击方面能达到相同的准确性。 这些方法在KDD’99的测试数据库上进行了验证,因为该数据库包含攻击的特征值足以将其与DoS和Probe分开。 例如字典攻击是一种R2L攻击:攻击者反复猜测远程计算机的用户名和密码。 通过检查两个特征就可以检测到攻击:每个服务的会话协议(P2)和一段时间内失败的登录尝试次数(P11)。 定假如特征值不能提供足够的信息,比如受害者密码强度不够,攻击者通过一两次猜测(例如通过输入其电话号码或学校名称等)就获取了访问权限,则此攻击的特征值将类似于正常值, 在这种情况下则无法检测这些攻击。
仅仅通过检查网络特征是很难检测到低频攻击的。 关于检测此类攻击(例如缓冲区溢出,密码破解,字典攻击,病毒等)的已经讨论出了一些可行的解决方案, 可以参考我们最近的工作62 20使用系统调用分析来检测这些攻击。 在我们最近的另一项工作中21,我们考虑了同时使用系统调用和网络特征来检测低频攻击。
XI. 结论
网络和主机的入侵率不断增加,严重影响了用户的安全和隐私。 研究人员研究了各种检测入侵的解决方案,本文研究了利用机器学习的方法进行入侵检测。我们描述了网络和主机系统中的各种类型的攻击,并简要描述了它们的攻击特征。分析表明,如果一种技术在检测某一种攻击方面表现良好,那么它检测其他攻击方面可能表现不佳。 因此,对于检测每一种攻击所使用的的机器学习方法的相关性已经给出。
我们对各种机器学习算法的关键性能进行了分析,不仅比较了单分类器方法和多分类器方法,还分析了特征子集对分类器的影响。我们发现即使最优特征集足以分析某一种攻击行为,也不利于分析其他攻击行为。因此,需要为每种攻击都定义最佳特征子集和合适的技术,因为攻击行为彼此不同。
我们描述了利用机器学习技术在网络数据集上检测低频攻击的困难,它激励研究人员去研究其他检测低频攻击的解决方案。我们提供了未来的研究方向,以帮助研究人员探索更有效的攻击检测解决方案。
我们描述了一些现有的文献,它们基于相似的技术,使用了流行的数据集。 但是里面提到的技术都没有被评估过以确保结果可以复现,这是我们论文的局限,所以我们非常希望以后能够改进。 在以后的研究中,我们想使用深度学习的方法训练一个攻击检测模型,可以在低频攻击的检测上有良好的表现。 未来当IDS技术开始应用于动态和不断变化的网络环境(例如云计算等)时,各种新出现的问题将成为我们关注的焦点
引用
-
N. Moustafa and J. Slay, “Unsw-nb15: A comprehensive data set for network intrusion detection systems (unsw-nb15 network data set),”in Military Communications and Information Systems Conference (MilCIS), Canberra, Australia, 2015, pp. 1–6. ↩
-
A.-S. K. Pathan, The State of the Art in Intrusion Prevention and Detection. CRC Press, 2014. ↩
-
S. Kumar, “Survey of current network intrusion detection techniques,” Washington Univ. in St. Louis, pp. 1–18, 2007. ↩
-
M. Ahmed, A. N. Mahmood, and J. Hu, “A survey of network anomaly detection techniques,”Journal of Network and Computer Applications, vol. 60, pp. 19–31, 2016. ↩
-
P. Kumar, N. Nitin, V. Sehgal, K. Shah, S. S. P. Shukla, and D. S.Chauhan, “A novel approach for security in cloud computing using hidden markov model and clustering,” in World Congress on Infor-mation and Communication Technologies (WICT). IEEE, 2011, pp. 810–815. ↩
-
G. Mantas, N. Stakhanova, H. Gonzalez, H. H. Jazi, and A. A. Ghorbani, “Application-layer denial of service attacks: taxonomy and survey,” International Journal of Information and Computer Security, vol. 7, no. 2-4, pp. 216–239, 2015. ↩
-
D. Kumar, “Ddos attacks and their types,” Network Security Attacks and Countermeasures, p. 197, 2016. ↩
-
M. Malekzadeh, M. Ashrostaghi, and M. S. Abadi, “Amplification-based attack models for discontinuance of conventional network transmissions,” International Journal of Information Engineering and Electronic Business, vol. 7, no. 6, p. 15, 2015. ↩
-
S. Maiti, C. Garai, and R. Dasgupta, “A detection mechanism of dos attack using adaptive nsa algorithm in cloud environment,” in Computing, Communication and Security (ICCCS), 2015 International Conference on. IEEE, 2015, pp. 1–7. ↩
-
T. Halagan, T. Kov ́ aˇ cik, P. Tr ́ uchly, and A. Binder, “Syn flood attack detection and type distinguishing mechanism based on counting bloom filter,” in Information and Communication Technology-EurAsia Conference. Springer, 2015, pp. 30–39. ↩
-
E. Bou-Harb, M. Debbabi, and C. Assi, “Cyber scanning: a compre-hensive survey,” IEEE Communications Surveys & Tutorials, vol. 16, no. 3, pp. 1496–1519, 2014 ↩
-
E. Raftopoulos, E. Glatz, X. Dimitropoulos, and A. Dainotti, “How dangerous is internet scanning?” in International Workshop on Traffic Monitoring and Analysis. Springer, 2015, pp. 158–172. ↩
-
M. Rostamipour and B. Sadeghiyan, “Network attack origin forensics with fuzzy logic,” in Computer and Knowledge Engineering (ICCKE), 2015 5th International Conference on. IEEE, 2015, pp. 67–72. ↩
-
S. Bahl and S. K. Sharma, “A minimal subset of features using correlation feature selection model for intrusion detection system,” in Proceedings of the Second International Conference on Computer and Communication Technologies. Springer, 2016, pp. 337–346. ↩
-
C. Edge and D. ODonnell, “Malware security: Combating viruses, worms, and root kits,” in Enterprise Mac Security. Springer, 2016, pp. 221–242. ↩
-
A. A. Ghorbani, W. Lu, and M. Tavallaee, “Network attacks,” in Network Intrusion Detection and Prevention. Springer, 2010, pp. 1–25. ↩
-
P. K. Manadhata and J. M. Wing, “An attack surface metric,” IEEE Transactions on Software Engineering, vol. 37, no. 3, pp. 371–386, 2011. ↩
-
K. S. Wutyi and M. M. S. Thwin, “Heuristic rules for attack detection charged by nsl kdd dataset,” in Genetic and Evolutionary Computing. Springer, 2016, pp. 137–153. ↩
-
P. Mishra, E. S. Pilli, and R. Joshi, “Forensic analysis of e-mail date and time spoofing,” in Third International and Communication Technology (ICCCT),. IEEE, 2012, pp. 309–314. ↩
-
P. Mishra, E. S. Pilli, V. Varadharajan, and U. Tupakula, “Vaed: Vmi-assisted evasion detection approach for infrastructure as a service cloud,” Concurrency and Computation: Practice and Experience, vol. 29, no. 12, 2017. ↩ ↩2
-
——, “Psi-netvisor: Program semantic aware intrusion detection at network and hypervisor layer in cloud,” Journal of Intelligent & Fuzzy Systems, vol. 32, no. 4, pp. 2909–2921, 2017. ↩ ↩2
-
A. Shiravi, H. Shiravi, M. Tavallaee, and A. A. Ghorbani, “Toward developing a systematic approach to generate benchmark datasets for intrusion detection,”computers & security, vol. 31, no. 3, pp. 357–374, 2012. ↩
-
D. S. Kim and J. S. Park, “Network-based intrusion detection with support vector machines,” inInformation Networking. Springer, 2003, pp. 747–756. ↩
-
N. B. Amor, S. Benferhat, and Z. Elouedi, “Naive bayes vs decisiontrees in intrusion detection systems,” in Proceedings of the 2004 ACM symposium on Applied computing. ACM, 2004, pp. 420–424. ↩
-
Y. Bouzida and F. Cuppens, “Neural networks vs. decision trees for intrusion detection,” in IEEE/IST Workshop on Monitoring, Attack Detection and Mitigation (MonAM), Tuebingen, Germany, vol. 28, 2006, p. 29. ↩
-
A. Tajbakhsh, M. Rahmati, and A. Mirzaei, “Intrusion detection using fuzzy association rules,” Applied Soft Computing, vol. 9, no. 2, pp. 462–469, 2009. ↩
-
S. Kumar and A. Yadav, “Increasing performance of intrusion de-tection system using neural network,” in Advanced Communication Control and Computing Technologies (ICACCCT), 2014 International Conference on. IEEE, 2014, pp. 546–550. ↩
-
P. V. Amoli, T. Hamalainen, G. David, M. Zolotukhin, and M. Mirzamohammad, “Unsupervised network intrusion detection sys-tems for zero-day fast-spreading attacks and botnets,” Int. J. Digit. Content Technol. Its Appl, vol. 10, no. 2, pp. 1–13, 2016. ↩
-
D. Bhamare, T. Salman, M. Samaka, A. Erbad, and R. Jain, “Feasibility of supervised machine learning for cloud security,” in International Conference on Information Science and Security (ICISS). IEEE, 2016, pp. 1–5. ↩
-
H. H. Jazi, H. Gonzalez, N. Stakhanova, and A. A. Ghorbani, “De-tecting http-based application layer dos attacks on web servers in the presence of sampling,”Computer Networks, vol. 121, pp. 25–36, 2017. ↩
-
H. Wang, J. Gu, and S. Wang, “An effective intrusion detection framework based on svm with feature augmentation,” Knowledge-Based Systems, 2017. ↩
-
P. Sangkatsanee, N. Wattanapongsakorn, and C. Charnsripinyo, “Prac-tical real-time intrusion detection using machine learning approaches,” Computer Communications, vol. 34, no. 18, pp. 2227–2235, 2011. ↩
-
F. Amiri, M. R. Yousefi, C. Lucas, A. Shakery, and N. Yazdani, “Mutual information-based feature selection for intrusion detection systems,” Journal of Network and Computer Applications, vol. 34, no. 4, pp. 1184–1199, 2011. ↩
-
W. C. Lin, S. W. Ke, and C.-F. Tsai, “Cann: An intrusion detection system based on combining cluster centers and nearest neighbors,” Knowledge-Based Systems, vol. 78, pp. 13–21, 2015. ↩
-
L. Koc, T. A. Mazzuchi, and S. Sarkani, “A network intrusion detection system based on a hidden na ̈ ıve bayes multiclass classifier,” Expert Systems with Applications, vol. 39, no. 18, pp. 13 492–13 500, 2012. ↩
-
H. Gharaee and H. Hosseinvand, “A new feature selection ids based on genetic algorithm and svm,” in 8th International Symposium on Telecommunications (IST). IEEE, 2016, pp. 139–144. ↩
-
I. Manzoor, N. Kumar et al., “A feature reduced intrusion detection system using ann classifier,”Expert Systems with Applications, vol. 88, pp. 249–257, 2017. ↩
-
M. A. Ambusaidi, X. He, P. Nanda, and Z. Tan, “Building an intrusion detection systemusing a filter-based feature selection algorithm,”IEEE transactions on computers, vol. 65, no. 10, pp. 2986–2998, 2016. ↩
-
G. Kumar and K. Kumar, “A multi-objective genetic algorithm based approach for effective intrusion detection using neural networks,” in Intelligent Methods for Cyber Warfare. Springer, 2015, pp. 173–200. ↩
-
S. Mukkamala, A. H. Sung, and A. Abraham, “Intrusion detection using an ensemble of intelligent paradigms,” Journal of network and computer applications, vol. 28, no. 2, pp. 167–182, 2005. ↩
-
S. Mukkamala, A. H. Sung, and A. Abraham, “Intrusion detection using an ensemble of intelligent paradigms,” Journal of network and computer applications, vol. 28, no. 2, pp. 167–182, 2005. ↩
-
A. N. Toosi and M. Kahani, “A new approach to intrusion detection based on an evolutionary soft computing model using neuro-fuzzy classifiers,” Computer communications, vol. 30, no. 10, pp. 2201– 2212, 2007. ↩
-
A. N. Toosi and M. Kahani, “A new approach to intrusion detection based on an evolutionary soft computing model using neuro-fuzzy classifiers,” Computer communications, vol. 30, no. 10, pp. 2201– 2212, 2007. ↩
-
X. Tong, Z. Wang, and H. Yu, “A research using hybrid rbf/elman neu-ral networks for intrusion detection system secure model,” Computer physics communications, vol. 180, no. 10, pp. 1795–1801, 2009. ↩
-
G. Wang, J. Hao, J. Ma, and L. Huang, “A new approach to intrusion detection using artificial neural networks and fuzzy clustering,” Expert Systems with Applications, vol. 37, no. 9, pp. 6225–6232, 2010. ↩
-
W. Feng, Q. Zhang, G. Hu, and J. X. Huang, “Mining network data for intrusion detection through combining svms with ant colony networks,” Future Generation Computer Systems, vol. 37, pp. 127– 140, 2014. ↩
-
S. Elhag, A. Fern ́ andez, A. Bawakid, S. Alshomrani, and F. Herrera, “On the combination of genetic fuzzy systems and pairwise learning for improving detection rates on intrusion detection systems,” Expert Systems with Applications, vol. 42, no. 1, pp. 193–202, 2015. ↩
-
W. Yassin, N. I. Udzir, Z. Muda, M. N. Sulaiman et al., “Anomaly-based intrusion detection through k-means clustering and naives bayes classification,” in Proc. 4th Int. Conf. Comput. Informatics, ICOCI, no. 49, 2013, pp. 298–303. ↩
-
Y. Chen, A. Abraham, and B. Yang, “Hybrid flexible neural-tree-based intrusion detection systems,” International Journal of Intelligent Systems, vol. 22, no. 4, pp. 337–352, 2007. ↩
-
C. Xiang, P. C. Yong, and L. S. Meng, “Design of multiple-level hybrid classifier for intrusion detection system using bayesian clustering and decision trees,” Pattern Recognition Letters, vol. 29, no. 7, pp. 918– 924, 2008. ↩
-
S. W. Lin, K. C. Ying, C.-Y. Lee, and Z.-J. Lee, “An intelligent algorithm with feature selection and decision rules applied to anomaly intrusion detection,” Applied Soft Computing, vol. 12, no. 10, pp. 3285–3290, 2012. ↩
-
P. Casas, J. Mazel, and P. Owezarski, “Unsupervised network intru-sion detection systems: Detecting the unknown without knowledge,” Computer Communications, vol. 35, no. 7, pp. 772–783, 2012. ↩
-
Y. Li, J. Xia, S. Zhang, J. Yan, X. Ai, and K. Dai, “An efficient intrusion detection system based on support vector machines and gradually feature removal method,” Expert Systems with Applications, vol. 39, no. 1, pp. 424–430, 2012. ↩
-
F. Kuang, W. Xu, and S. Zhang, “A novel hybrid kpca and svm with ga model for intrusion detection,” Applied Soft Computing, vol. 18, pp. 178–184, 2014. ↩
-
A. Chandrasekhar and K. Raghuveer, “Intrusion detection technique by using k-means, fuzzy neural network and svm classifiers,” in Com-puter Communication and Informatics (ICCCI), 2013 International Conference on. IEEE, 2013, pp. 1–7. ↩
-
S. J. Horng, M. Y. Su, Y.-H. Chen, T.-W. Kao, R.-J. Chen, J.-L. Lai, and C. D. Perkasa, “A novel intrusion detection system based on hierarchical clustering and support vector machines,” Expert systems with Applications, vol. 38, no. 1, pp. 306–313, 2011. ↩
-
K. K. Gupta, B. Nath, and R. Kotagiri, “Layered approach using conditional random fields for intrusion detection,” IEEE Transactions on dependable and secure Computing, vol. 7, no. 1, p. 35, 2010. ↩
-
M. S. I. Mamun, A. A. Ghorbani, and N. Stakhanova, “An entropy based encrypted traffic classifier,” in International Conference on Information and Communications Security. Springer, 2015, pp. 282– 294. ↩
-
M. N. Chowdhury, K. Ferens, and M. Ferens, “Network intrusion detection using machine learning,” in Int. Conf. on Security and Management (SAM). The Steering Committee of The World Congress in Computer Science, Computer Engineering and Applied Computing (WorldComp), 2016, pp. 1–7. ↩
-
N. Moustafa and J. Slay, “A hybrid feature selection for network intrusion detection systems: Central points,” pp. 1–10, 2015. ↩
-
A. A. Aburomman and M. B. I. Reaz, “A novel svm-knn-pso ensemble method for intrusion detection system,” Applied Soft Computing, vol. 38, pp. 360–372, 2016. ↩
-
P. Mishra, E. S. Pilli, V. Varadharajan, and U. Tupakula, “Securing virtual machines from anomalies using program-behavior analysis in cloud environment,” in IEEE 18th International Conference on High Performance Computing and Communications. IEEE, 2016, pp. 991– 998. ↩