| 类型 | 内容 |
|---|---|
| 标题 | Predicting Impending Exposure to Malicious Content from User Behavior |
| 时间 | 2018 |
| 会议 | CCS |
| 引用 | Sharif M, Urakawa J, Christin N, et al. Predicting impending exposure to malicious content from user behavior[C]//Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security. 2018: 1487-1501. |
感想
感觉这是一篇水文,但对这种研究方法还是值得学习的,拿到一个数据集,用各种方法分析并得出各种奇怪的结论。
摘要
许多计算机安全防御是被动的,它们只在安全事件发生时或之后运行。最近有努力试图在安全事件发生之前预测,以使防御者能够主动保护其设备和网络。这些努力主要集中在长期预测上。
我们提出了一个系统,它可以在单个浏览会话的级别上实现主动防御。通过观察用户行为,它可以提前几秒发现用户是否是会暴露在恶意内容中,从而为主动防御找到了机会。
我们使用一家大型蜂窝运营商的20645名用户在2017年生成的三个月的HTTP流量对我们的系统进行评估,结果表明它是非常有用的。
我们还通过调查直接与用户接触,询问他们与人口统计和安全相关的问题,以评估自我报告数据在预测恶意内容暴露方面的效用。我们发现,自我报告的数据有助于长期预测暴露风险。然而,即使是长期的自我报告的数据也不如行为测量对准确预测暴露的重要性。
介绍
一个用户用手机浏览了恶意网站,可能导致手机中毒,最后丢失个人信息和财产,这样即暴露在恶意内容中。
文章主题是通过分析用户的行为(例如大量浏览可疑的网页)判断在接下来的一段时间(例如30秒左右)是否会暴露在恶意的内容中。
系统利用 用户自己报告的安全行为和对过去行为的观察,用户浏览会话的上下文特征,来预测用户是否会暴露在恶意内容之下。
贡献:
- 利用大型移动服务提供商的超过20,600名用户的三个月历史数据,记录了移动用户在线遭受恶意攻击(例如恶意软件)的程度,表明至少有11%的用户在受到过攻击。
- 其次,我们以Google安全浏览为例说明了黑名单的局限性,我们发现恶意网页在被加入黑名单之前就经常被访问:大量访问发生在黑名单的前几天甚至更早(最多87天)。
- 第三,我们的测量还显示了暴露于恶意页面的用户与未暴露于恶意页面的用户在浏览模式(例如浏览会话的长度)上的明显差异。
- 第四,通过问卷调查这些用户,我们建立了逻辑回归以估计自我报告的数据可以在多大程度上提供风险暴露的有意义的指标。
第五,我们设计了一个长期的预测分类器,它可以根据过去的行为特征来确定用户在一个月内暴露于恶意网站的风险。
第六,也是最重要的一点是,我们结合从所有这些实验中获得的知识,设计出一种短期分类器,该分类器由易于实时计算的特征构建而成,可以在30秒左右的时间内准确预测出用户的暴露风险( 第7节)。相关工作
我们的研究发处于四个不同的工作领域的交汇处:进行测量研究以确定移动恶意软件在多大程度上构成实际威胁;对保护终端用户(不仅仅使用黑名单)的系统研究;安全事件的预测;人为因素及其对安全性的影响的研究。
移动恶意软件的流行. 研究人员从早期就研究了移动恶意软件的生态系统。 Zhou和Jiang发现,他们研究的1200个恶意软件样本中,有80%以上是对合法软件的重新打包版本,而超过90%将主机变成了bots。
对恶意软件感染流行率的估计相差很大。一项研究通过美国一家大型移动提供商收集的DNS流量估计了恶意软件的流行率,并断言每百万台设备中只有不到九台被感染。另一个团队收集有关在用户设备上运行进程的信息,得出截然不同的结论——他们估计每千台设备中约有三台受到感染。
每个估计都有其自身的局限性:在前一项工作中,可能无法检测到使用硬编码IP地址的恶意软件(因为它不执行DNS查找),而在后一项工作中,总体样本可能有偏差。
保护系统和网络 有很多黑名单机制和反病毒来帮助保护网络系统。 例如Gu提出了检测网络内僵尸程序的技术。 另一个例子是,Nazca通过检查网络上设备产生的总体流量来检测下载驱动攻击(drive-by-download attacks)。 早先的方案只能在暴露后进行干预,而本论文是提前预测可能导致感染和数据泄露的事件。
预测安全事件 Soska和Christin表明,使用公开可用的指标,他们可以预测网站是否会在一年内遭到入侵。 Hao可以预测恶意域名的注册。 Liu等证明了人们可以使用外部观察到的指标(例如DNS错误配置)来预测企业将来是否会遭受安全事故(例如服务器违规)。 Sabottke重点集中在使用从Twitter提要中收集的信息来预测哪些漏洞将被利用,而Kang等人提出方法来预测一个国家内有多少百分比的主机可能被特定恶意软件感染。
影响安全的人为因素 计算机安全中的人为因素已得到广泛研究。Christin等人发现运行防病毒软件的用户更有可能将其设备置于危险之中。 我们的结果重现了这一发现。
一些研究人员试图通过安装在其机器上的软件监视用户的行为,从而提高用户研究的生态有效性。 令人惊讶的是,他们发现专家的行为不一定比非专家更安全。 某些类型的网站(例如流媒体和色情网站)比其他网站具有更高的感染风险,并且访问那些被列入黑名单的网站和这些类网站的行为高度相关。
Egelman和Peer制定了“安全行为意图量表”(SeBIS),以此作为评估安全行为的简单手段。 他们发现,SeBIS的不同子量表与某些计算机安全行为密切相关(例如,在所谓的“主动意识”子量表上得分较高的用户不太可能受到网络钓鱼攻击)。 其他人则质疑像SeBIS这样的量表是否真正预测了该领域的实际行为。 我们使用修订的SeBIS(RSeBIS)的主动意识子量表来探讨这个问题,该量表对语言翻译更健壮。
数据收集
KDDI,日本一家大型移动互联网服务提供商提供用户数据
加入这个数据收集的用户,会允许服务提供商记录HTTP访问。
2017年6月,20895名不同的用户。
HTTP流量收集
2017年4月1日至2017年6月30日期间收集的日志,20645个手机用户出现在日志中。
每个日志条目都包含HTTP请求的时间戳、访问的URL、HTTP Referer字段的内容、上载和下载的字节数、用户代理字符串以及与客户对应的(唯一的)用户ID。
限制 数据集不包括HTTP内容(例如,通过HTTP POST发送的数据)或HTTPS请求,只包括内容类型为text/html的HTTP请求。换言之,我们无法看到图像、脚本或多媒体内容访问;同样地,由于收集只会覆盖蜂窝网络,因此我们无法访问任何Wi-Fi流量。
先前的研究发现,网络上大多数恶意流量都是基于HTTP的12
While the democra-tization of HTTPS using services such as Let’s Encrypt [2] might increase the popularity of serving malicious content over HTTPS, ourproposedmethodscanbeadaptedbyusingdomaininformationonly, instead of the entire URL. Further, corporate networks can perform HTTPS collection using “man-in-the-middle” proxies [19].
数据存在的问题:同意被收集数据的用户,可能更不在意隐私。但是隐私行为和安全行为是独立的3。
HTTP日志处理
同一个用户发出的连续http请求作为一个会话 ,当user-agent更改或者超过20分钟没有请求时,认为会话终止。
数据集中的一小部分HTTP请求(<2.2%)来自传统操作系统(如Windows、Mac OS等)
根据谷歌安全浏览v3(GSB)数据库,将HTTP请求标记为恶意或非恶意。
GSB每天更新,所以下载了每天的快照进行查询。
将HTTP请求的URL分为几类,如新闻,体育等。
使用DigitalArts开发的分类算法,i-Filter过滤系统。
使用DigitalArts手工标注的域名,训练了一个卷积神经网络将域名分为99个主题
暴露的用户至少访问过一次恶意页面,未暴露的用户没有访问过恶意页面
在线调查
要求参与的用户参加一个在线调查。
收到23419个用户响应,3.9%的回复率。有效回答有20895个。
受众特征 男性用户占61.5%,女性用户占38.5%。 (被征集用户的人数为男性55.6%,女性42.8%,未知1.6%。)受访者的平均年龄为43岁,标准差为11.8岁。受访者不包括18岁以下的未成年人。
问题:
- 是否遇到过安全事件(密码被盗)。遭遇过安全事件可能会影响用户的行为
- 用户设备上是否安装了防病毒软件。该类用户可能更容易存在风险行为
- 使用的应用市场类型。非官方应用市场有大量的恶意APP,此类用户更容易暴露
- 浏览器弹出警告时,用户的行为。忽略警告的用户更容易暴露
- 参与者对RSeBIS的主动意识量表的反应。积极主动意识得分高的参与者比其他人更不容易受到网络钓鱼的影响。得分高的参与者访问恶意网站的风险也较低。
- 参与者对计算机安全知识的自信。期望自信的参与者表现出更安全的行为。
暴露在恶意环境下
分析有三个目标 (1)确定移动用户在多大程度上暴露于恶意内容。 (2)证明在页面被列入黑名单之前,不法分子有入侵设备的机会。 (3)探索暴露和未暴露用户在多个维度上的行为差异。
用户暴露的总体比率
20,645个用户中,2172(11%)个用户至少访问了一次恶意页面。这些用户中的大多数(1,995)暴露于GSB分类为“网络钓鱼”的页面,153个用户暴露于“恶意软件”页面,而24个用户暴露于“恶意软件”和“网络钓鱼”页面。 总体而言,暴露的用户访问了201个域中的3,491个恶意页面。
至少有0.81%的用户暴露于已确认的恶意软件。但是,我们无法估计实际感染的比例,这些用户可能已被防病毒或其他内容过滤器保护。 11%的用户会暴露于可疑内容
暴露的窗口
观察那些在被加入到GSB数据库之前的URL访问日志。负x轴代表被加入之前,正x轴代表被加入之后。
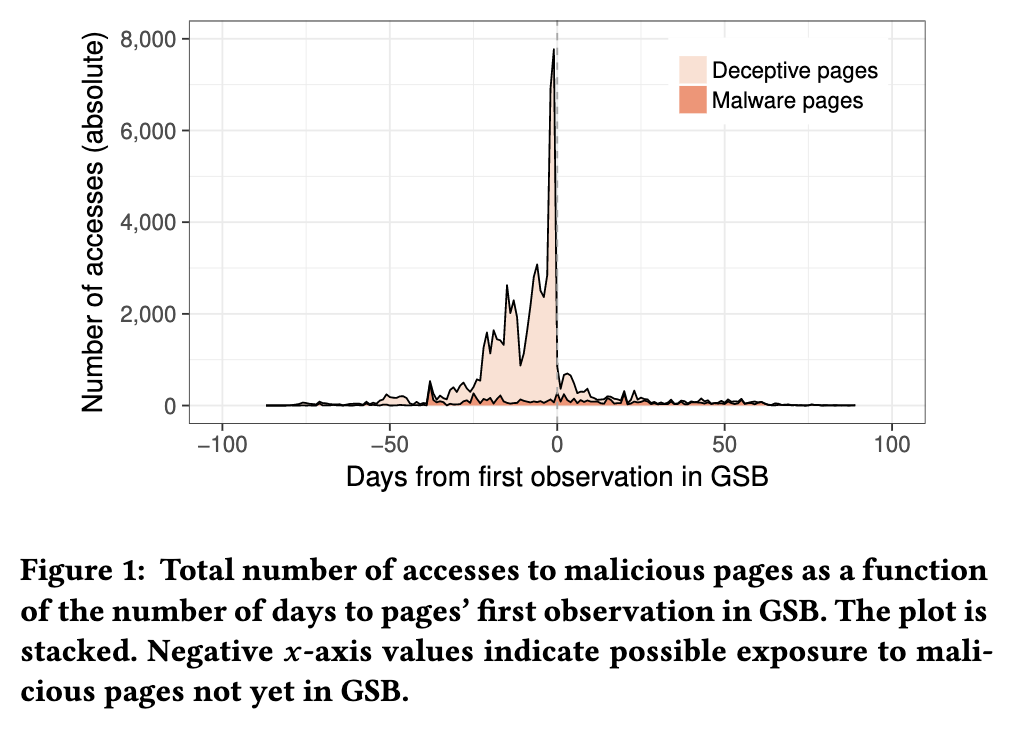 某些页面被GSB标记为恶意页面,可能存在几天或几周的延迟
某些页面被GSB标记为恶意页面,可能存在几天或几周的延迟
用户间行为的差异
知道GSB何时将页面标记为恶意,但不清楚页面何时真正变成恶意网页。
定义1 τ-恶意页面:考虑用户在时间t向URL u发出HTTP请求。如果URL u在任何时间t′出现在GSB数据库中,使得t≤t′< t+τ,则将其视为τ-恶意。
τ-恶意页面是当前被标记为良性的网页,但将被标记为恶意的网页。τ越小,危险就越大,已经是恶意页面的概率随着τ→0而增加。
τ=22天 该页面的访问次数开始显著增加
τ=2天 访问峰值最高
暴露事件 图2显示针对恶意页面的各种定义的每个暴露用户的请求访问性页面的数量,范围从τ=0到可能的最大值(91天)。
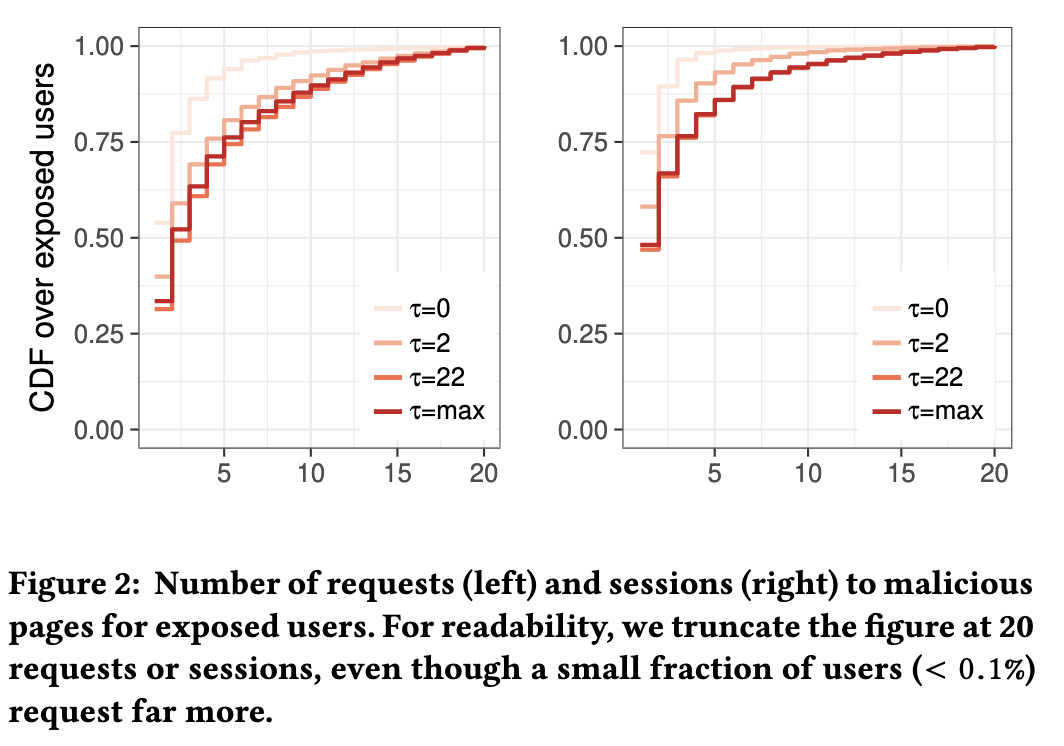
1/3 - 1/2的用户只访问了一个恶意页面,超过1/4的用户对恶意页面发出了超过3个请求。
结论2 预测分类器不能完全依赖于先前的暴露,因为我们的用户语料库中有相当一部分显示缺乏“重复”暴露
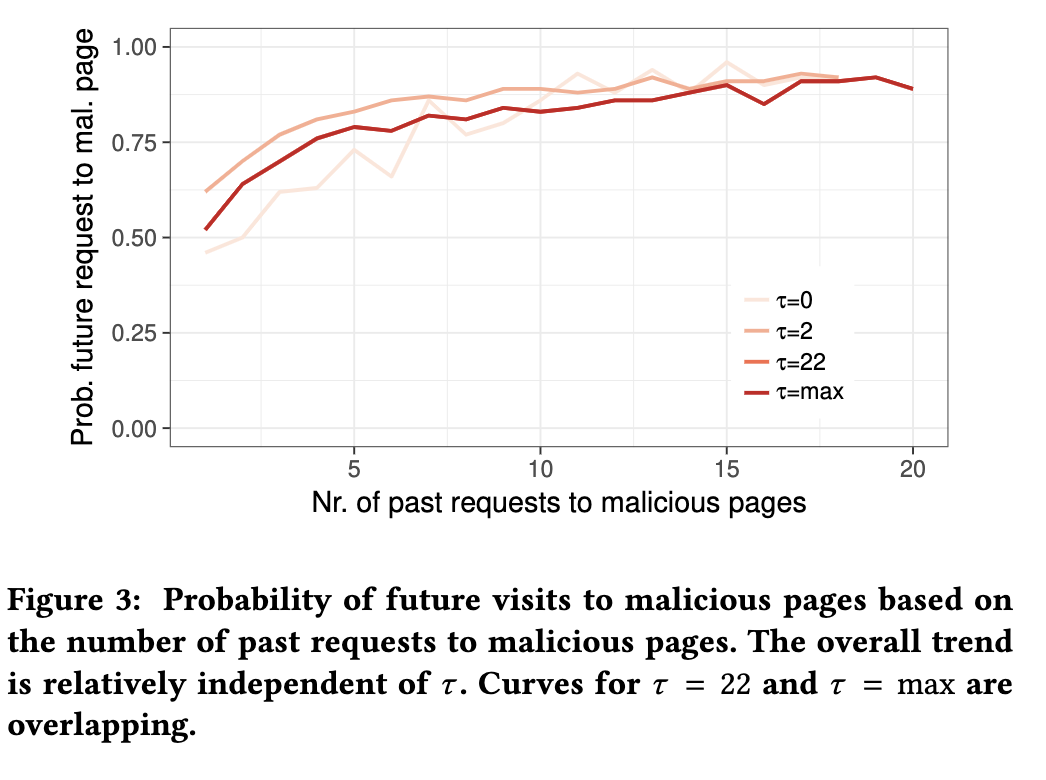
接下来,我们在图3中计算至少访问过x次恶意页面的暴露用户将来将访问恶意页面的概率。 图3报告了Pr[A(x+1)|A(x)]的经验估计,其中A(x)表示用户访问了至少x个恶意页面的事件。 我们发现:
结论3 用户暴露的次数越多,再次暴露的概率就越高
会话级度量 接下来我们将研究暴露用户和未暴露用户之间活动水平的差异。图4(a)未暴露的用户通常比暴露的用户每天请求的页面要少得多。图4(b)显示了会话长度的明显差异:未暴露的用户参与的会话通常比暴露的用户短。
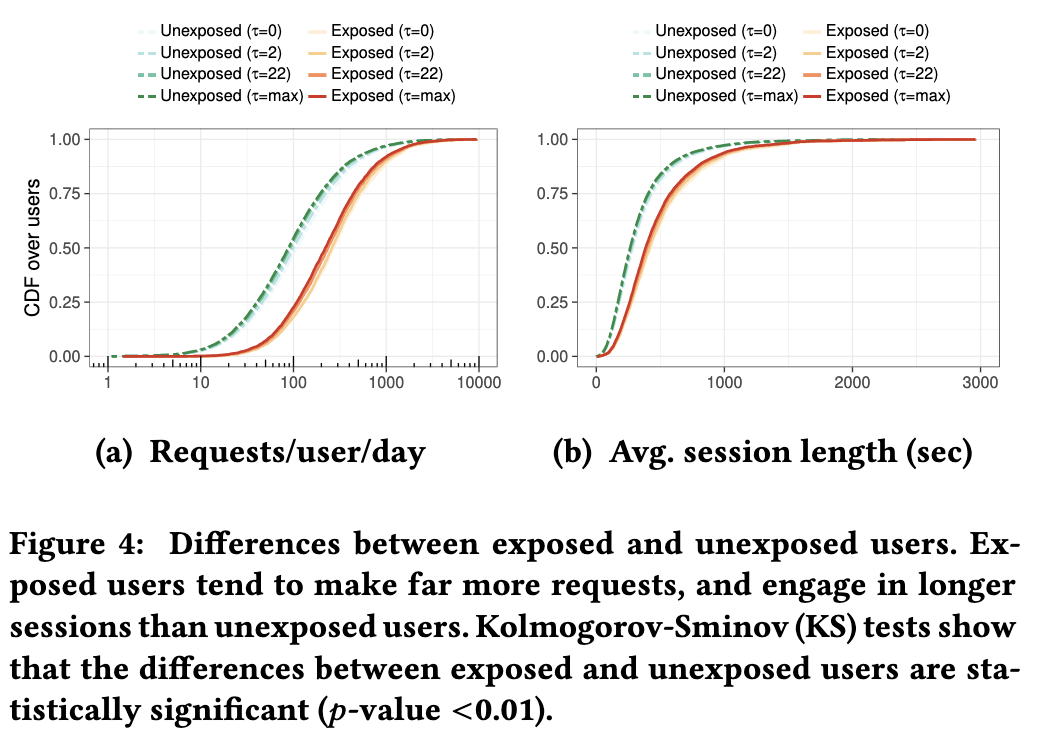
结论4 暴露的用户比未暴露的用户更活跃-他们发会出更多的HTTP请求,并参与更多更长的浏览会话
每日和每周影响 接下来,我们按小时查看每天暴露和未暴露的用户的请求量,如图5所示。为了有意义地比较不同的类,我们将每个值归一化为[0,1]范围,其中0代表每天来自给定类型的用户的最小请求数,而1是最大请求数。
人们在午餐时间浏览互联网最多,清晨(午夜至凌晨4点)是一天中最安静的时间。然而,似乎暴露的用户倾向于在一天中更均匀地请求数据;特别是,与未暴露的用户的差距在晚上最为明显。暴露的用户比未暴露的用户更经常地浏览互联网,晚上比工作时浏览风险更大的网站。
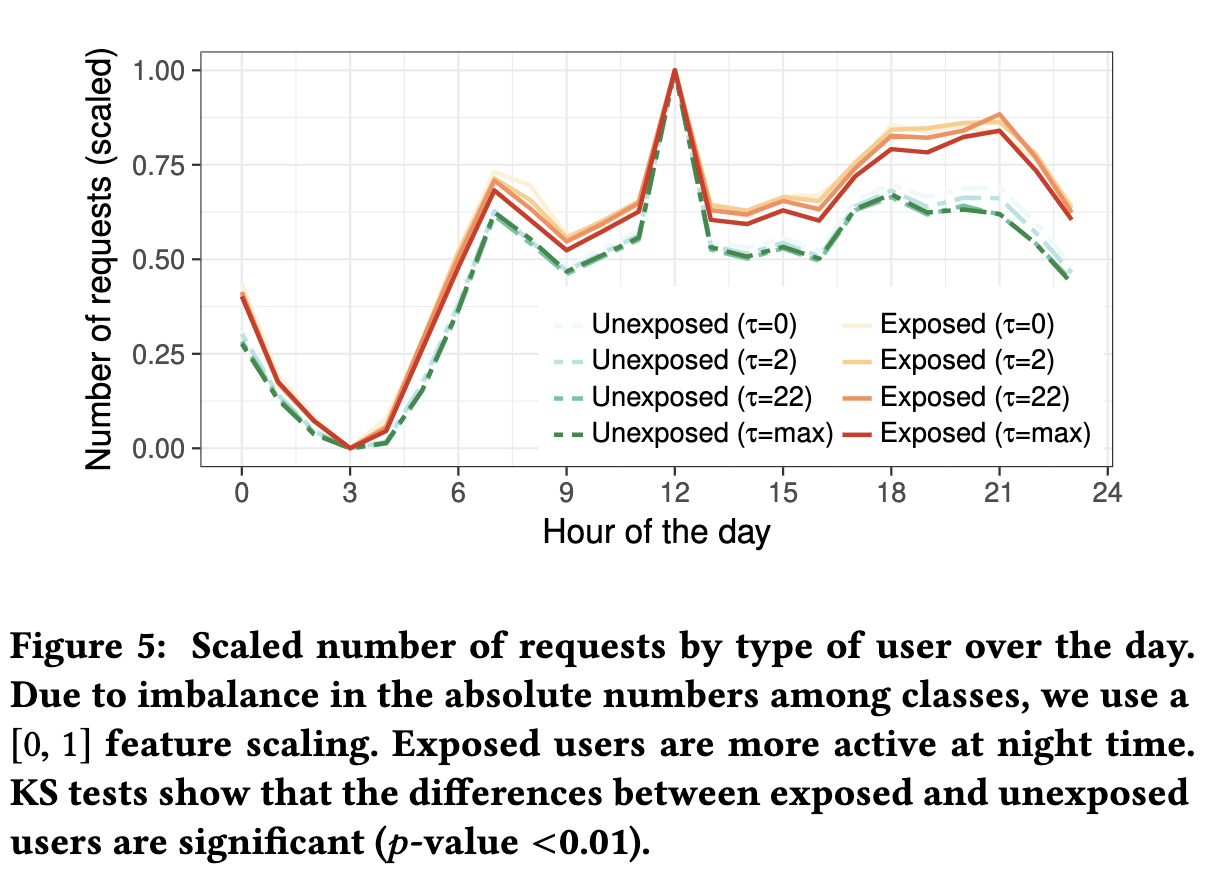
结论5 暴露的用户倾向于在晚上和工作时间之外更频繁地浏览互联网
暴露的用户在周末往往比未暴露的用户更活跃
图6展示了未暴露和暴露用户的广告和成人网页的比例。尽管我们可能会忽略一些对广告页面的请求(JavaScript)。暴露的用户相比未暴露的用户以更高的频率访问广告页面、成人内容。 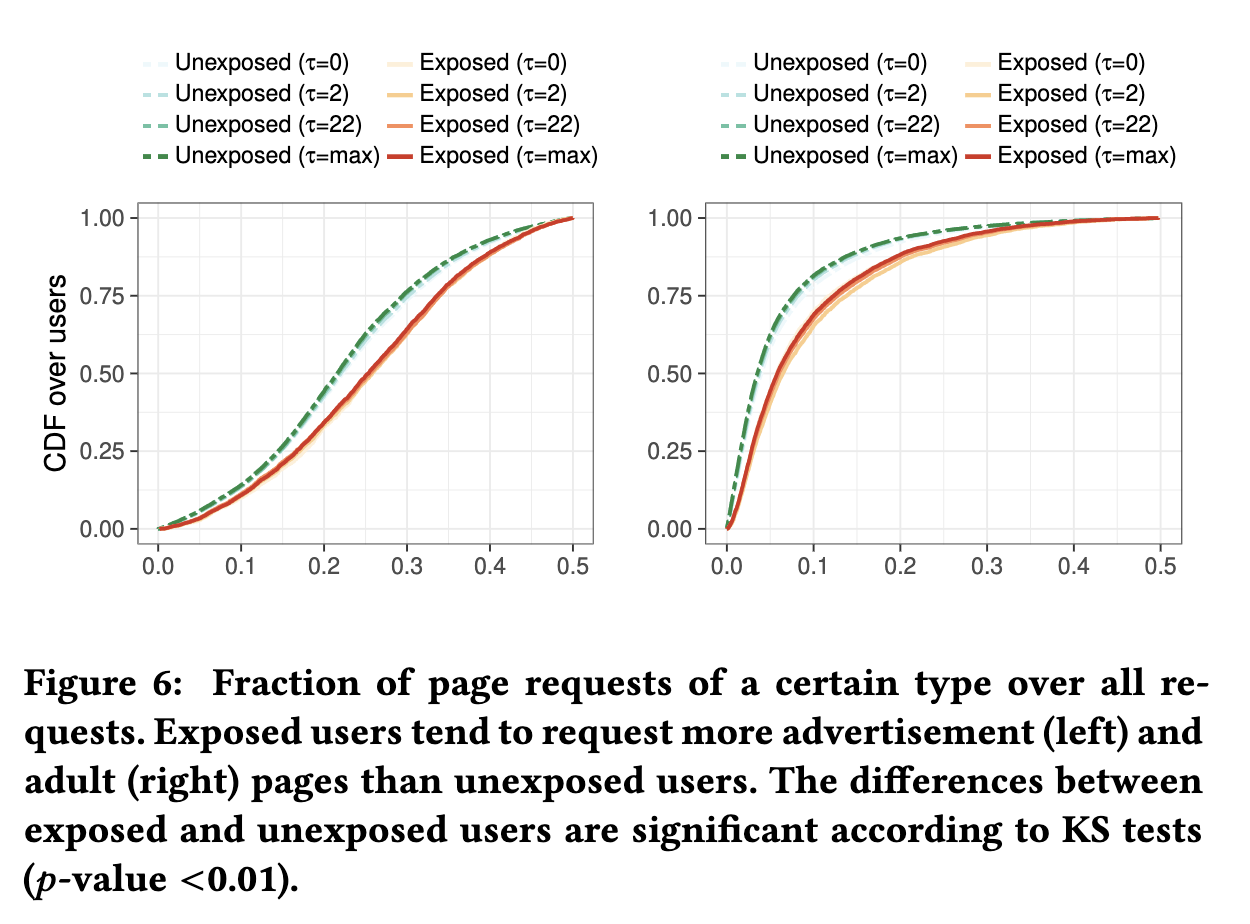
暴露的用户更可能访问19个类别的网页(如成人、广告和视频搜索网页),而未暴露的用户更可能访问46个类别的网页(如教育、金融和新闻网页)
结论6.某些类别的内容可能有较高的暴露风险
测量结果表明,τ=2似乎是一个合理的折衷方案:较大的τ可能包含在浏览时并没有恶意的页面,但较小的τ可能会丢失危险页面。
调查响应和暴露风险
实验设计
logistics回归, τ=2 自变量是根据调查响应构建的。 具体来说,我们计算以下变量:
- 性别
- 用户设备上是否存在防病毒软件
- 用户是否从非官方市场下载应用程序
- 用户是否忽视浏览器警告
- 用户是否遭受过损害
- RSeBIS主动意识得分(标准化为[0,1]范围
使用Python的statsmodels包来构建回归模型
实验结果
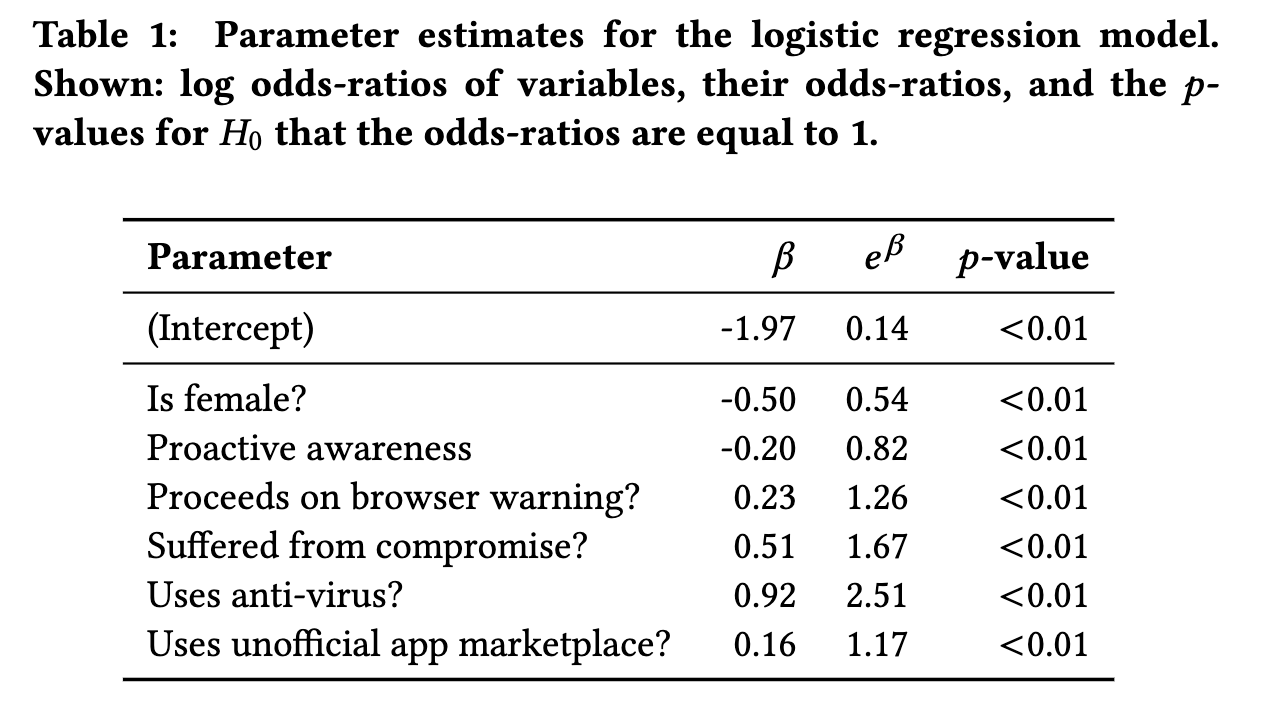 表1中报告了最佳拟合模型的参数估计值。在交互作用幸存的模型选择中,发现模型中的所有主要因素均在显着性水平p <0.01上对暴露有显着影响。女性访问恶意网址的可能性是男性的0.54倍。这一发现表明,女性在第一时间遇到此类网页的可能性较小。遭受过损害的参与者接触恶意内容的几率增加了1.67倍。参数估计显示,一些风险行为例如忽略浏览器警告,以及使用非官方市场下载的APP,平均将暴露于恶意内容的几率增加至少1.17倍。
表1中报告了最佳拟合模型的参数估计值。在交互作用幸存的模型选择中,发现模型中的所有主要因素均在显着性水平p <0.01上对暴露有显着影响。女性访问恶意网址的可能性是男性的0.54倍。这一发现表明,女性在第一时间遇到此类网页的可能性较小。遭受过损害的参与者接触恶意内容的几率增加了1.67倍。参数估计显示,一些风险行为例如忽略浏览器警告,以及使用非官方市场下载的APP,平均将暴露于恶意内容的几率增加至少1.17倍。
拥有反病毒软件的用户,访问恶意网站的几率是其他人的2.51倍。这些用户有一种错误的安全感,导致他们从事高风险的行为。最后,在RSeBIS上获得高警惕意识得分的用户访问恶意url的可能性是得分最低的用户的0.82倍,这支持了先前的证据,即该等级与某些安全行为相关
长期暴露预测
分类器设计
自我报告的特征
提取了七个特征进行预测。其中六个特性与第2.1.2节中描述的相同
第七个表示用户对其安全知识的自信(通过将对Likert量表问题的回答相加,然后标准化到[0,1]范围来计算)
过去行为的特征
共132个特征
会话和HTTP请求的平均数量,上载和下载的平均字节数以及以秒为单位的平均会话长度和请求数。
一个特征指示以前的会话发生暴露的比例,另一个特征量化以前的暴露次数
24个特征总结了每个小时的活动水平,99个特征描述了先前的HTTP请求如何在DigitalArts的99个主题之间分配。
最后一个特征是报告了对不在Alexa排名前100,000个网站中的域的请求所占的比例。
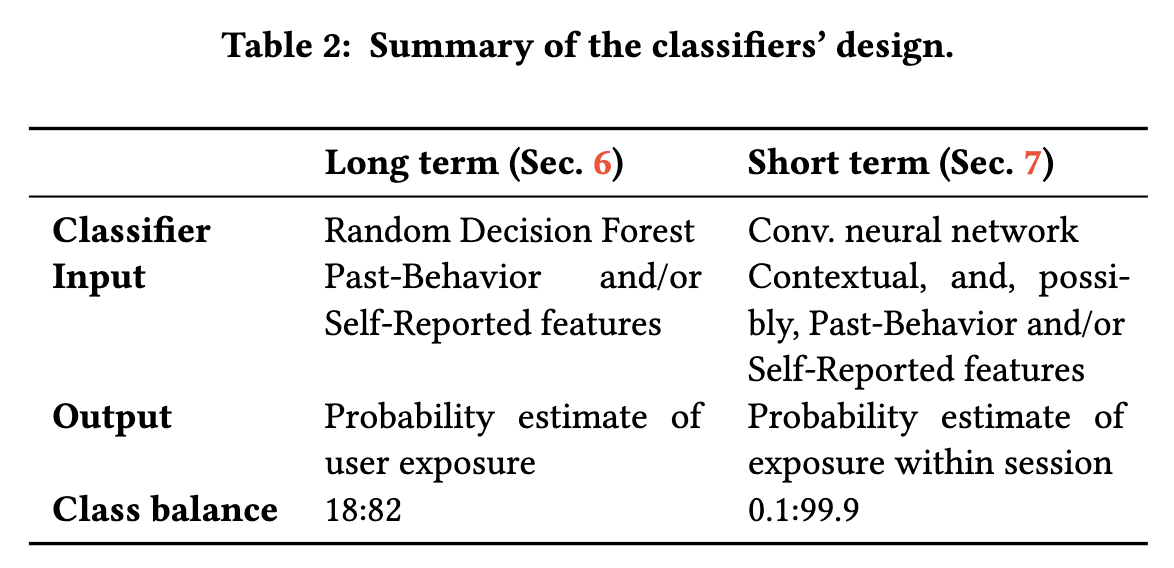
预测算法 我们使用随机决策森林来执行预测。 为了获得最佳性能,分类树的数量设置为50,最大树的高度设置为5,然后将否定示例的权重设置为肯定树的权重的0.1倍。 表2总结了分类器的设计。
实验设计
基于用户自我报告数据和/或浏览行为,我们可以预测下个月的曝光率吗?为了回答这个问题,我们使用我们的数据训练随机决策森林,利用4月份的观测数据预测5月份的暴露(τ=2),并通过5月份的观测评估这些模型预测6月份暴露的能力。进行了十次交叉验证,其中90%的用户用于训练,10%的用户用于测试。
实验结果
图7显示了两个参数的函数的整体分类器性能。 使用我们完整的功能集(自我报告和过去的行为),图7(a)显示了会话阈值s的影响。 s表示用户必须忍受才能被视为公开的不同公开会话的数量。 当s=1时,用户可能是偶然地登陆了暴露的网页; s=5时,用户重复的暴露。
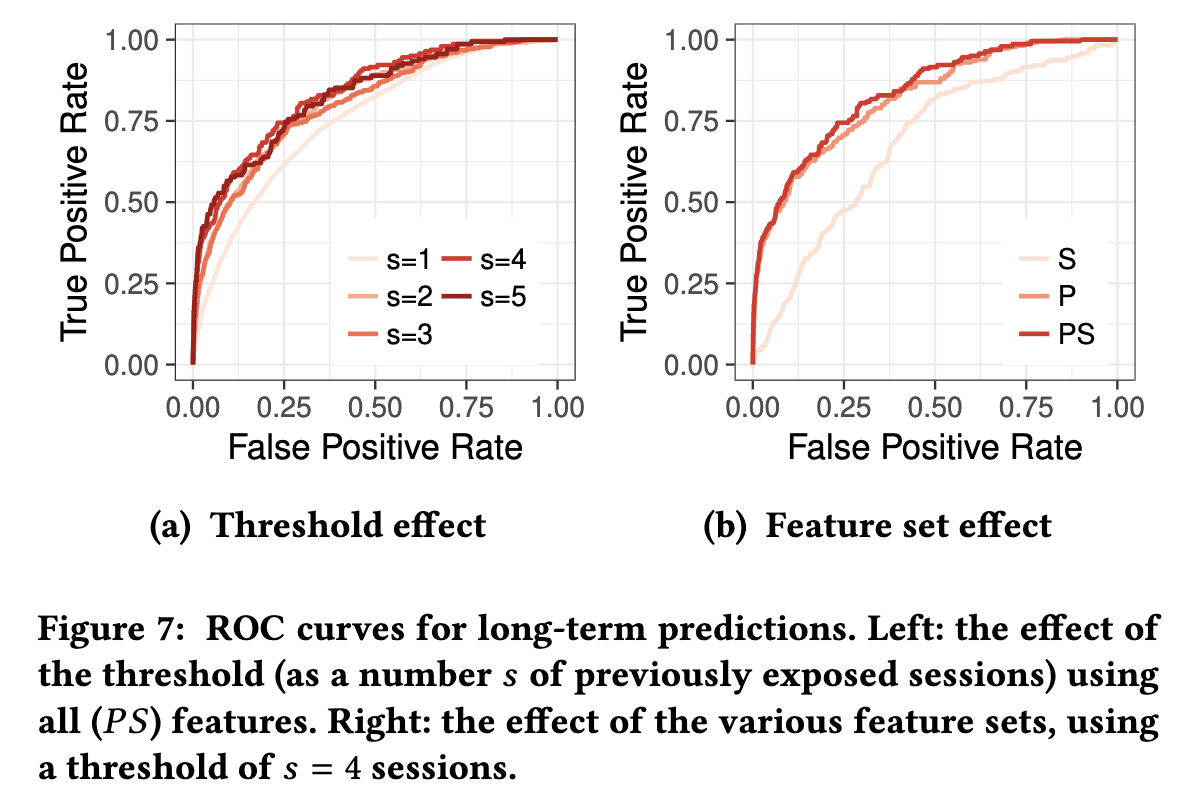
对于长期预测来说,s越高似乎效果越好。图7(b)示出了两个特征集的影响:S表示自报告特征的影响,P表示过去行为特征的影响,PS表示考虑两个特征集的影响。正如预期的那样,整个集合(PS)取得了最好的结果,但更有趣的是,自报告特性本身的影响非常小。虽然孤立地说,自报告特性可能有用(例如,如果用户监视不是一个选项),但是过去的行为特性可以自己获得更好的性能;并且将它们与自报告特性相结合不会产生很大的改进。
会话内暴露预测
接下来,我们探讨预测单个浏览会话期间用户是否会从事危险行为(即访问恶意网站)的可行性。 因此,我们旨在使用在某个阶段描述会话的上下文特征,以预测用户是否会在会话的后续阶段暴露。 每次用户发出HTTP请求时,上下文功能都会更新以描述会话的新状态,并做出另一个预测。 作为如图6和先前的工作所示,用户的行为特征(例如,访问的网站数量)可以帮助预测长期(例如三个月)的用户暴露风险。 接下来,我们将展示如何使用类似的行为特征来在更短的时间尺度上预测暴露。
分类器设计
上下文特征
共135个
由于暴露的会话往往具有较高的活动量,因此量化活动量的功能可以很好地替代我们的预测。 其中包括会话长度(以秒为单位),HTTP请求数以及会话期间传输的字节数。
恶意域不太可能(直接)从顶级域链接到。 因此,我们将对非顶级域名(即Alexa顶级域名100,000之外)的HTTP请求所占比例作为另一项功能。 暴露的会话更可能发生在周末和一天的晚些时候(发现5)。因此,我们使用一个特征来指示会话是否在周末进行,使用24个特征来指示会话处于活动状态的时间。 六个二进制特征指示会话中使用的操作系统和浏览功能(从HTTP标头中的用户代理字符串中获悉):两个特征指示Android和iOS,两个特征指示使用Chrome和Safari,并且使用两个特征来指示其他操作系统和浏览器(例如Firefox OS)。 虽然我们的探索性数据分析和先前的工作[49]并未表明不同系统(例如iOS与Android)的风险状况存在明显差异,但这些特征可以帮助捕获系统之间的细微差异(例如浏览器黑名单的更新频率),这可能会影响用户的暴露率。 最后,有99个特征描述了会话中访问的域的主题。 如之前的工作所示,某些网站类别例如在线流媒体倾向于表现出比其他类别更多的恶意活动。 因此访问此类网站可能会增加暴露的可能性。 预测算法 使用卷积深神经网络(DNNs)进行预测
目标是在暴露发生之前预测对恶意内容的暴露,因此忽略了在访问恶意URL时或之后进行的会话中的HTTP请求。
我们为训练集中的每个HTTP请求创建一个特征向量。为暴露会话的HTTP请求分配一个正向标签(即1),为其余请求分配一个负向标签(即0)。 在训练过程中,我们不会使用在暴露时间前超过一分钟的会话中使用HTTP请求。
我们仅对具有9个以上请求的会话执行预测。(这些会话占所有公开课程的约96%)。 使用Selenium和tPacketCapture,在Android手机上抓取了Alexa前100个仅HTTP的网站,发现平均美两个网站访问量对应于十个HTTP请求。 因此,我们提出的系统将在用户访问两个网站后开始分析用户的浏览活动。
我们使用的DNN是顺序的,并且由三个卷积层组成,每个卷积层后接一个校正线性激活层、一个全连接层和一个softmax层。 卷积使用5×128核,步长为1。 在训练中,DNN的交叉熵损失设为最小。 这是体系结构和培训策略的标准选择。 在选择卷积架构之前,我们最初测试了仅由全连接层组成的神经网络架构,发现其执行的准确性较低。
我们使用从训练数据中获得的统计数据将DNNs的输入规范化为[0,1]范围,因为规范化有助于加快训练速度和提高性能。我们将学习率设置为5×10^-5,batch size设置为128,epochs设置为50。我们通过网格搜索来设置超参数,优化DNNs的深度和卷积核的大小。我们在Keras中实现DNNs(使用TensorFlow后端[1])。表2总结了预测器的设计。
实验设计
我们选择了5个20天的不同时段(其中前15天用于训练,后5天用于测试)来评估。
讨论
短期预测可以在用户暴露之前,提醒可能存在的风险
在全国范围的蜂窝网络规模上部署防火墙或IDS可能很困难,因为增加的费用和可能影响用户体验的高延迟。
像我们这样基于会话的暴露预测系统可以帮助优先处理应该通过昂贵检查的流量。使用深度处理,还可以防止在风险环境中安装第三方应用程序。
基于会话的预测系统可用于收集潜在的恶意页面以更新黑名单。
我们注意到,在某些情况下,FPR可能太高,无法在生产中有效地部署系统。事实上,当可用性是主要关注点(例如,在通用网络中)时,某些干预,例如终止连接或警告用户,在FPR较高时可能导致烦恼或习惯化。在这种情况下,我们建议调整系统以降低FPR(从而降低TPR)。或者,可以采取更保守的干预措施,例如识别潜在的恶意页面以进行扫描或阻止安装第三方应用程序。
引用
-
Luca Invernizzi, Stanislav Miskovic, Ruben Torres, Christopher Kruegel, Sabyasachi Saha, Giovanni Vigna, Sung-Ju Lee, and Marco Mellia. 2014. Nazca: Detecting Malware Distribution in Large-Scale Networks. In Proc. NDSS. ↩
-
YajinZhouandXuxianJiang.2012.Dissecting android malware:Characterization and evolution. InProc. IEEE S&P. ↩
-
Serge Egelman and Eyal Peer. 2015. Predicting privacy and security attitudes. ACM SIGCAS Computers and Society 45, 1 (2015), 22–28. ↩