| 类型 | 内容 |
|---|---|
| 标题 | 8 |
| 时间 | 2017 |
| 会议 | SIGCOMM |
| DOI | 10.1145/3098593.3098596 |
@inproceedings{gonzalez2017net2vec,
title={Net2Vec: Deep learning for the network},
author={Gonzalez, Roberto and Manco, Filipe and Garcia-Duran, Alberto and Mendes, Jose and Huici, Felipe and Niccolini, Saverio and Niepert, Mathias},
booktitle={Proceedings of the Workshop on Big Data Analytics and Machine Learning for Data Communication Networks},
pages={13--18},
year={2017}
}
- 处理的问题
- 主要贡献\提出的解决方案
- 对文章的理解
摘要
Net2Vec,一个高性能平台,以超过60Gbps的速度从网络中捕获数据,转换为tuple并实时进行预测.用于流量分类和网络性能分析.
介绍
网络分析优化平台:用于CDNs/内容流行度预测,异常检测(DoS攻击,端口扫描),在线广告,高级流量分类,故障预测等.
设计和实现
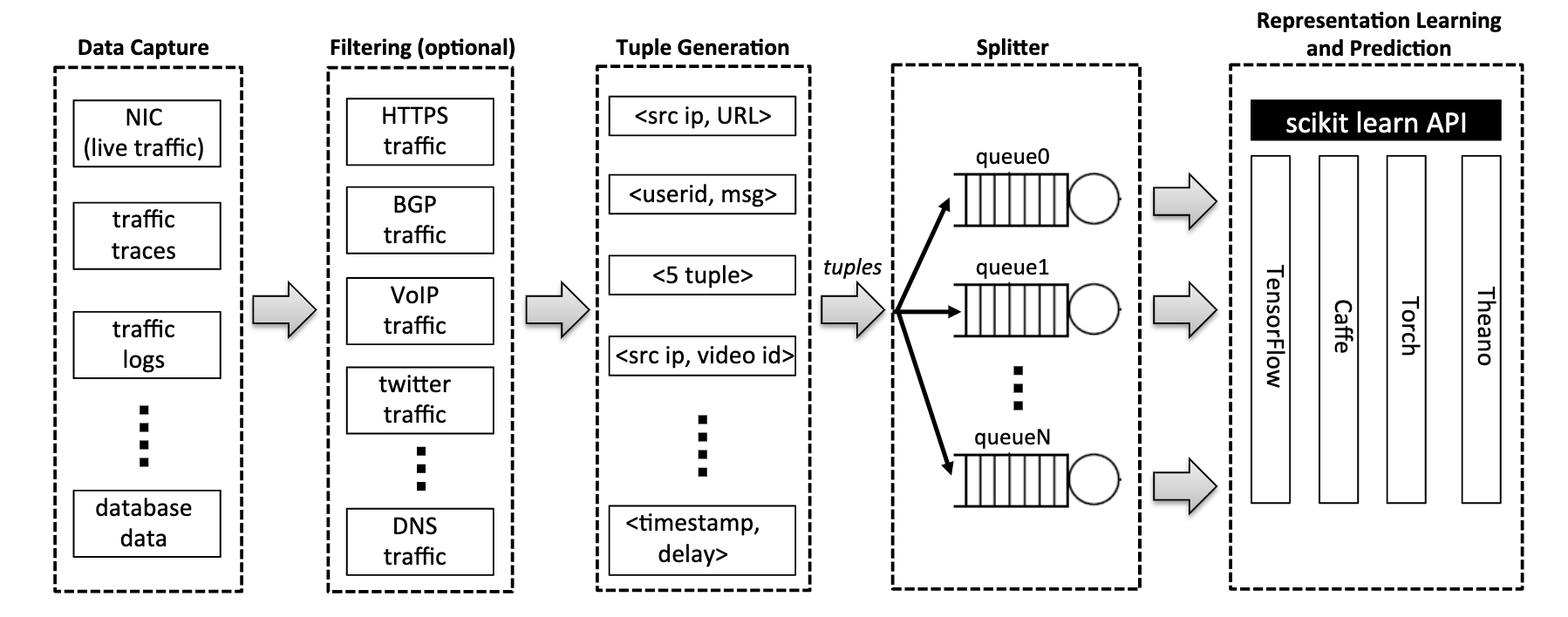
Net2Vec负责捕获数据包,过滤数据包,从中构造tuple,并将这些元组反馈给负责分析的机器学习算法.
-
数据捕获:此组件负责从多个源捕获网络数据,包括网络接口、流量记录文件或日志文件。我们实现了一个基于Netmap的模块,该模块从网络接口捕获实时流量
-
过滤:一组负责过滤掉非预期流量的模块(可选).在我们的评估中,我们实现了一个过滤HTTP流量的模块
-
tuple生成:此组件将数据包/流转换为一组适合表示学习的tuple。例如,在本文进一步描述的用户评测用例中,tuple格式为
<src ip,hostname> -
Splitter:将tuple根据特征拆分为不同的tuple序列.类似于关系数据库,属性的子集称为key,个体序列成为表征学习的输入.
-
表示学习和预测 支持符合sklearn API的所有算法
捕获\筛选和tuple生成组件
Net2Vec以网络数据为目标,Net2Vec捕获来自多个接口的流量,对其进行过滤以提取与特定用例相关的流量,并将结果转换为表示学习算法所需的tuple
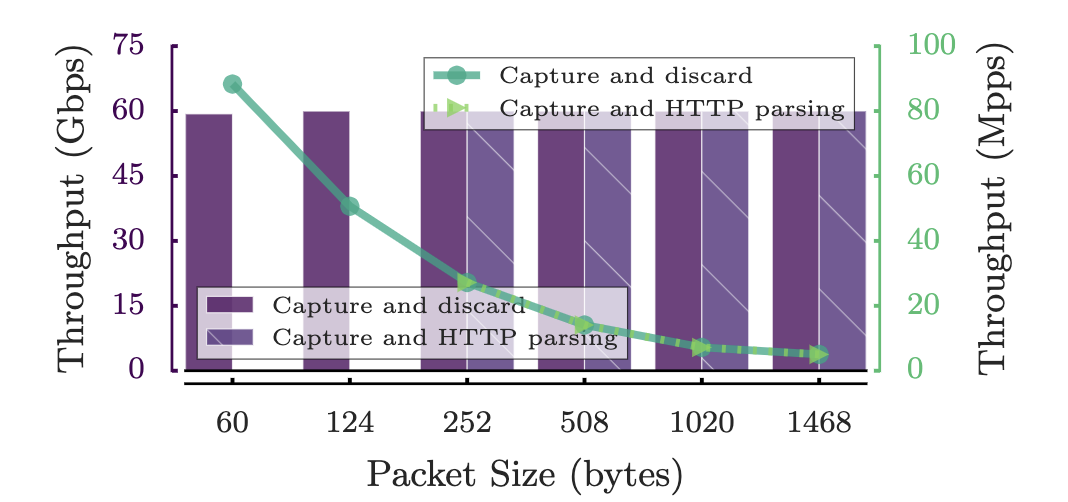
性能:x86服务器,E5-1650 v2 3.5Ghz CPU(6核),16G RAM,三个Intel X520-T2 10Gb/s 双端口网卡(总共60Gb/s).
Splitter组件
根据用户指定的key,将tuple流分割成与key指定的流.每个流都与大小为n的队列相关联。一旦队列被填满,队列的内容(即tuple序列)将被发送到ML组件以更新其参数和执行预测。队列中最早的tuple将被删除。在一些用例(如用户分析)中,与某个key相关的流量分割是至关重要的,并且还可以用于负载平衡目的。
表示学习与预测组件
使用标准scikit-learn API方法(例如预测,拟合等机器学习模型。Net2Vec将模型应用于传入的tuple流,以学习特定于问题的对象的表示( 镜像,主机名等),并为给定任务执行预测。 基于神经网络的框架如Torch和TensorFlow。由于必须实时处理网络流量,因此使用了cudamat等库用于GPU计算.
用例:用户分析
评估Net2Vec平台,用例是用户分析,给用户提供定向的广告.
问题描述
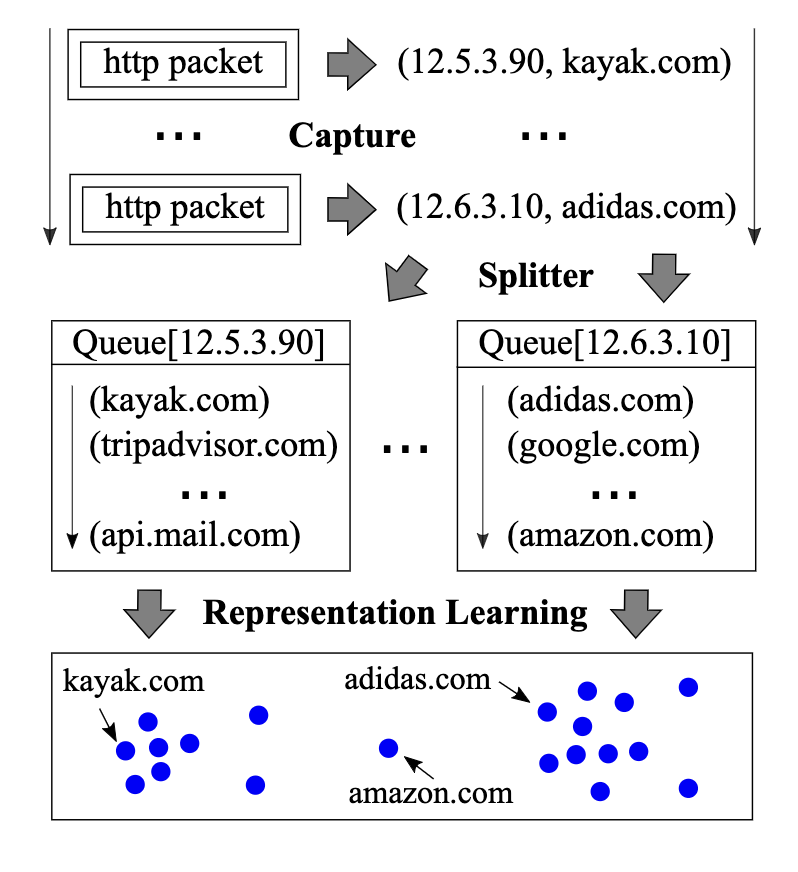
假设运营商捕获客户的HTTP(S)流量,由Net2Vec捕获并映射成tuple的形式(Src ip,hostname),即一个用户ip访问的hostname.运营商有一个集合C将hostname与类别相关联,但是有一些hostname可能是CDN.任务目标是给定一个用户的ip,通过他的URL访问序列,实时的将其与相关产品关联.
标准方法是存储用户访问的hostname,并为用户分配对应的类别,但这种做法的缺点是用户的数据会不断增长,并且存储用户的浏览记录在很多国家是非法的.
使用Net2Vec来训练一个学习用户行为的神经网络模型,给定用户的请求序列,来预测用户感兴趣的商品类别.模型被训练为对于每一个序列的hostname都构建一个one-hot encoding,类似于word2vec模型
实验&结果
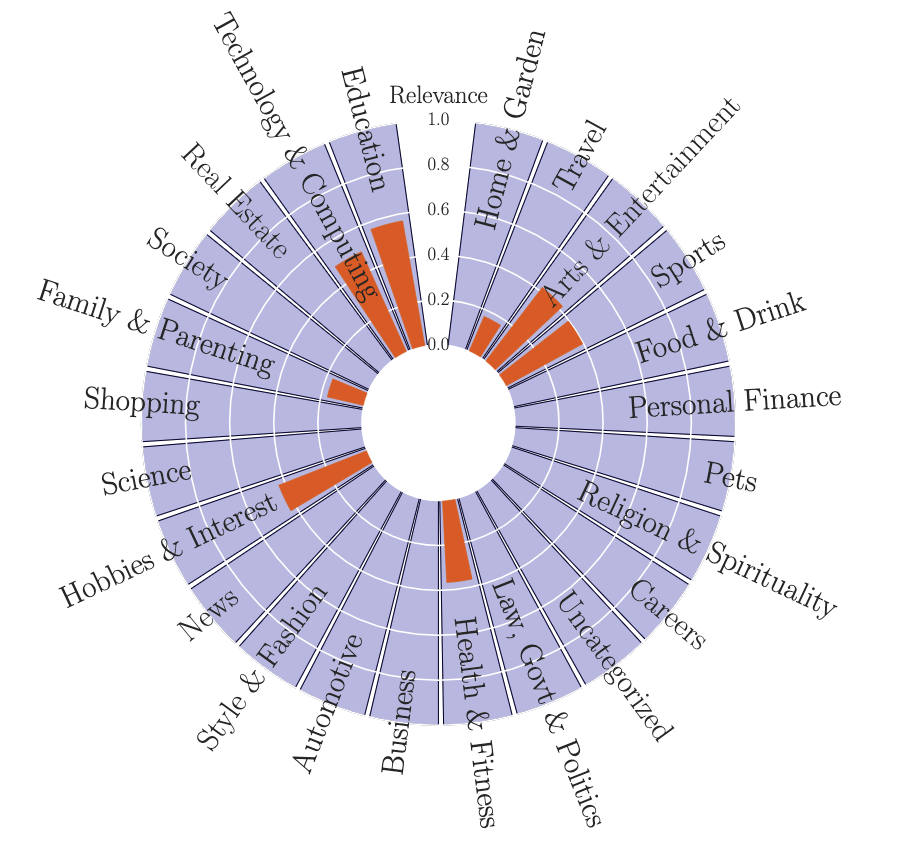
使用文本分类算法,将IAB目录分配给hostname 图4显示了一个Net2Vec返回的在视频游戏中用户的兴趣点 手动检查记录发现网络中访问过与视频游戏有关的网页的用户大多数也访问了与及教育和体育相关的网页.所以Net2Vec可以观察到用户的行为并为用户分配类别.
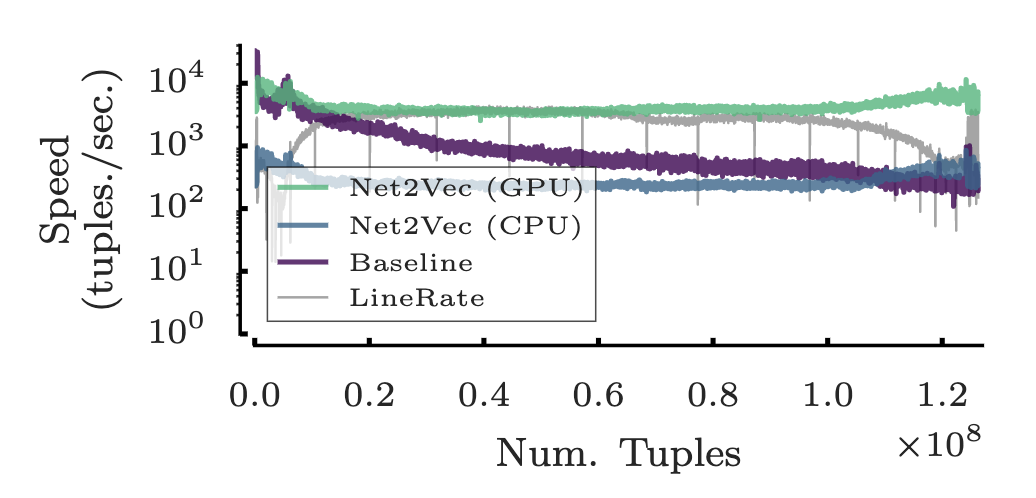
性能:x86服务器,CPU:E5-2637 v4 3.5Ghz,内存:128RAM,6Tflops的GTX Titan X(900系列).使用文本分类算法将200k个 hostname分配给相关的产品,根据一天的流量请求序列训练Net2Vec,预测第二天用户活动的类别.第二天的流量记录了超过40k个,用户的125M个HTTP请求.
图5描述了Net2Vec每秒能处理的tuple.baseline的预测效率会逐渐下降,因为要维护每个用户的类别,而Net2Vec的效率可以基本保持不变,神经网络的优势
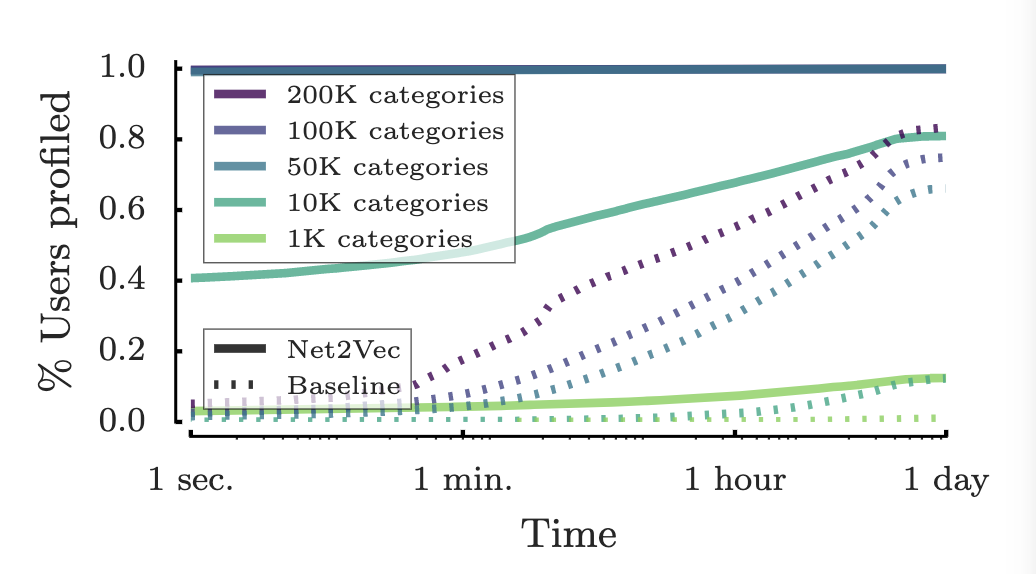
即使用户访问的hostname没有分配类别们也可以为用户生成一个profile文件.在图6中,当至少有50k个hostname的类别时,Net2Vec可以从第一个http请求开始为所有的用户生成profile文件,即使只有10K个hostname,系统需要不到1h的流量来生成70%的profile.而baseline的性能要差得多,必须处理超过1h的流量才能为大多数用户生成profile文件,并且即使获取了全天的流量,也有超过20%的用户没有profile