最新日志
-
【精读】Net2Vec
类型 内容 标题 8 时间 2017 会议 SIGCOMM DOI 10.1145/3098593.3098596
-
【机器学习】sklearn的SVM
参考:https://www.cnblogs.com/Yanjy-OnlyOne/p/11368253.html
from sklearn.svm import LinearSVC model = LinearSVC() model.fit(x_train,y_train)参数: 名称 | 介绍 – | – C | 默认为1,错误项的惩罚系数,C越大,对分错样本的惩罚越大,训练样本的准确率越高。但是泛化能力减低,对测试数据的准确率下降。如果减小C的话,容许训练样本中分类错误样本,泛化能力强。一般选择后者 kernel | 默认为rbf,采用核函数的类型可选的有:linear–线性核函数 ;poly–多项式核函数;rbf–径向核函数/高斯函数;sigmod:sigmod核函数;precomputed:矩阵函数 max_iter : int, optional (default=-1) | 最大迭代次数,默认-1表示不限制 loss | 字符串。表示损失函数。可取值为’hinge’:合页损失函数:’squared_hinge’:合页损失函数的平方
-
【精读】检测不响应探测器的代理
类型 内容 标题 Detecting Probe-resistant Proxies 时间 2020 会议 NDSS DOI 10.14722/ndss.2020.23087 摘要
代理服务器要规避一些探测请求,因为审查者可能使用已知的代理协议连接代理服务器。如果服务器响应了它确实是一个代理的话,审查者可以屏蔽它。GFW就是一个审查机构,会去查找和屏蔽代理服务器。作为回应,规避者创造出一些新的规避探测的代理协议,包括obfs4,shadowsocks,Lampshade。这些代理需要知道密钥的顺序,服务器在被审查者使用探测探测时会保持沉默,这让审查者难以检测他们。
此论文中发现,审查者仍然可以区分probe-resistant的代理和其他无害的代理。我们发现在五个probe-resistant协议中发现了独有的TCP行为,可以让审查者在误报率最小的情况下确认可疑的代理。从10Gbps带宽的国家级ISP上收集了几天的数据,并且使用ZMap扫描,来评估和分析。可以有效的识别代理服务器,误报可以忽视。并且给出防御者一些建议来规避审查。
介绍
近年来,审查人员已经学会了使用DPI来识别和阻止常见的代理协议,这促使审查人员创建新的协议,如obfsproxy和scramblesit,这些协议将加密通信量与随机通信量区分开来。这些协议没有可识别的指纹或头字段,使得审查人员很难被动地检测。 然而,GFW等审查机构已经开始通过连接可疑代理并尝试使用它们的自定义协议进行通信来主动探测这些代理。 如果可疑服务器响应已知的规避协议,审查员可以将其作为已确认的代理进行阻止。主动探测在检测代理时尤其有效,因为审查员可以在使用新服务器时发现它们。先前的工作表明,中国采用了广泛的主动探测体系结构,该体系结构成功地阻止了诸如Vanilla Tor,obfs2和obfs3等较旧的规避协议。
为了响应这项技术,研究人员已经开发了抗探测代理协议,如obfs4、Shadowsocks和Lampshade,它们试图阻止审查人员使用主动探测来发现代理。这些协议通常要求客户机在服务器响应之前证明对密钥的了解,审查人员如果没有这个密钥,则无法让服务器响应他们自己的活动探测,这使得审查员很难确认服务器所使用的协议。
作者发现了新的攻击,允许审查员仅使用少数探测就可以确定代理服务器。在数据集中假阳性可以忽略。
作者分析了五种常用的代理协议:Tor使用的obfs4、Lantern使用的Lampshade、Shadowsocks、Telegram使用的MTProto和Psiphon使用的模糊SSH。
攻击集中在一个观察点上,那就是从不响应数据是互联网上不寻常的行为。 通过发送由流行协议和随机数据组成的探测,我们可以从超过400k IP/端口的Tap数据集中的几乎所有端点(94%)获取响应。
对于不响应的端点,代理所特有的TCP行为(如超时和数据阈值)与其他服务器相比存在不同。作者与几个代理开发人员合作,包括Psiphon、Lantern、obfs4和Outline Shadowsocks,告知如何改进并部署。
背景
规避协议通过尝试与其他协议融合,或通过创建没有指纹的随机协议来避免被动识别。
在obfs4中,客户端用一个密钥来连接到服务器。如果没有此密钥,探测审查程序将无法完成初始握手,并且obfs4服务器将在短暂超时后关闭连接。
obfs4:obfs4是通用协议混淆层,通常用作Tor桥的可插拔传输 连接到obfs4服务器后,客户端会生成自己的临时性Curve25519密钥对,并在服务器的公共密钥,节点ID和客户端公共密钥上发送包含客户端公共密钥,随机填充和HMAC的初始消息,第二个HMAC包含时间戳。 服务器仅在HMAC有效时响应。 由于计算HMAC需要了解服务器公钥和节点ID,因此审查器无法从obfs4服务器获得响应。 如果客户端发送无效的HMAC(例如,探测检查器),则服务器会在随机延迟后关闭连接。
Lampshade Lampshade是Lantern审查规避系统使用的协议,它使用RSA加密来自客户端的初始消息。由于审查程序不知道服务器的RSA公钥,因此它们将无法发送具有已知种子的有效初始消息,并且任何后续消息都将被忽略。如果服务器无法解密预期的256字节密文(基于明文中的预期幻数),它将关闭连接。
Shadowsocks: Shadowsocks是一种在中国开发和使用的流行协议,有许多不同的实现。用户在云服务提供商上启动自己的私有代理实例,并使用用户选择的密码和超时配置它。然后,用户可以使用Shadowsocks协议将流量隧道到他们的私有代理。Shadowsocks客户机从秘密密码和随机salt生成密钥,然后使用经过身份验证的(AEAD)密码将随机salt和加密的有效负载发送到服务器。没有密码的审查员将无法生成有效的经过身份验证的密文,服务器将忽略其无效的密文。
Shadowsocks协议有很多实现,作者分析其中两个:Python实现的事件驱动的Shadowsocks和Jigsaw的Outline 。 分别称为shadowsocks-python和shadowsocks-outline。 在AEAD模式下,两个服务器从客户端接收50个字节,如果AEAD标记无效则服务器关闭连接。
MTProto:MTProto是专用协议,由Telegram在封锁服务的国家/地区设计和使用。MTProto从一个随机种子和用户密钥的hash中导出一个新的密钥。然后使用AES-CTR将密钥加密成4字节的值。如果服务器没有将客户端的第一条消息解密为预期的值,它将不会响应。因为审查员不知道这个密钥,所以他们将无法构造一个正确的密文。当握手失败时,服务器将保持连接打开但不响应。
模糊SSH:模糊的SSH(OSSH)是一个简单的协议,将SSH协议包装在加密层中,模糊了其易于识别的标头。 客户端发送一个16字节的种子,使用SHA-1派生密钥将其与秘密关键字一起哈希数千次。 该密钥用于使用RC4加密4字节魔术值以及任何有效载荷数据(即SSH流量)。 服务器从seed和secret关键字重新得出密钥,然后解密以验证魔术值。 作者专门研究了Psiphon的OSSH实现,使用分配给客户端的32字节密钥。 在不知道密钥的情况下,检查者无法创建有效的密文。 如果OSSH服务器收到的第一条消息无效,它将关闭连接。
探测器设计

Protocol | Client’s first message |Server Behavior –|–|– obfs4| K=server pubkeyj|NODEID M=client pubkeyjpaddingjHMACK(client pubkey) send: MjHMACK(Mjtimestam p) | Reads 8192 bytes (max handshake padding length) If no valid HMAC is found, server reads a random 0-8192 additional bytes, then closes the connection. Lampshade | send: RSAencry pt(server pubkey;:::jseed)|Reads 256 bytes (corresponding to RSA ciphertext length) and attempts to decrypt. If it fails, the server closes the connection. Shadowsocks | K=HKDF(password;salt;“sssubkey”) send: saltjAEADK(payload len)jAEADK(payload)| Reads 50 bytes (corresponding to salt, 2-byte length, and AEAD tag) If the tag is invalid, server closes the connection. MTProto Proxy|K=sha256(seedjsecret) send: seedjIVjEK(magic) |Does not close the connection on invalid handshake. OSSH |K=SHA1 1000 (seedjsecret) send: seedjEK(magicjpayload) |Reads 24 bytes, and closes the connection if the expected magic value is not decrypted. 每一个协议都要求客户端知道一个经过加密的密钥。如果客户端不知道密钥,服务器将不会响应,并关闭连接。 这种不响应在互联网上是不常见的,特别是对于流行协议中的大量探测。例如,HTTP服务器将响应HTTP请求,而代理不会响应。
基本探测
从6个基本探测开始:HTTP、TLS、MODBUS、S7、随机字节,以及连接后不发送数据的空探测。对于每个探测记录服务器如何响应、关闭连接的时间(如果有)以及如何关闭连接(TCP FIN或RST)。 HTTP:发送一个简单的GET请求,HOST是
example.com,大部分服务器会响应重定向或错误页 TLS:发送一个TLS的Client Hello消息,即使TLS不支持服务器也将响应一个TLS警报 Modbus:Modbus通常被可编程逻辑控制器(PLC)和其他嵌入式设备用于监控和数据采集(SCADA)环境。我们使用了ZGrab中定义的探测,它发送一个3字节的命令,该命令从远程主机请求设备信息描述符。 S7:S7是西门子PLC设备使用的专有协议。再次使用了ZGrab中定义的探测,它通过COTP/S7协议发送对设备标识符的请求。随机字节:用不同数量的随机字节发送探测,服务器将解析失败,以错误消息响应或区别于代理服务器的方式关闭连接。
空探测器:连接后不发送数据。有些协议(如SSH)让服务器首先(或同时)与客户端通信。对于其他协议,与不发送数据相比,客户端发送一些初始数据时的实现可能有不同的超时。
DNS AXFR:根据DNS规范构建了一个DNS AXFR(区域传输)查询探测。
STUN:实现了一个基于ZGrab-Golang库的STUN探测,用于探测Cisco WebEx设备
数据集
代理节点:从Tor的BridgeDB收集了20多个obfs4代理端点,并从Lantern开发者收集了3个Lantern代理。从Psiphon开发人员那里获得了3个OSSH代理端点,并使用Telegram应用程序发现了MTProto的3个节点。由于Shadowsocks是为用户运行自己的代理而设计的,因此作者设置了自己的Shadowsocks python实例(使用
chachacha20-ietf-poly1305密码进行配置),并从开发人员那里收到了Shadowsocks outline的地址。普通节点:使用ZMap的主动网络扫描和被动收集netflow数据:
使用ZMap将SYN包随机发送到20000个主机的每个TCP端口(0-65535)上,总共有13亿次探测。我们发现了150万个使用SYN-ACKs响应的端点,将其标记为ZMap数据集。
从科罗拉多大学的10 Gbps网关采样Netflow数据来收集端点。其在一个不审查互联网的国家的,绝大多数流量将不包含代理。这个ISP的用户很少有动机使用审查规避代理,所以这里收集的端点可能主要是其他服务。在3天的时间跨度内,从ISP收集了超过550000个服务器IP/端口 的节点。其中,433286(79%)个主机接受了连接(使用一个TCP SYN-ACK响应),其余的大多数在尝试连接时只是超时。
首先,后续扫描是在观察到连接后的几天内进行的,一些服务器可能在这段时间内移动了IP或离线。其次,服务器可能配置了防火墙,只允许从某些IP进行访问,可能会阻塞ZMap扫描主机。最终在这个数据集中捕获超过40万个发送数据的服务器。识别代理
三个关键点:响应数据、连接超时和关闭阈值
响应数据
HTTP服务器将响应HTTP探测,但许多其他协议在接收到他们不理解的应用层数据时,将用错误消息或信息来响应。由于代理策略保持沉默,所以没有一个代理服务器响应任何探测。 所以可以将有响应的服务器标记为非代理服务器。
超时
超时的时间,和超时后关闭连接的方式不同(FIN/RST)
缓冲区阈值
一个服务器从客户端读取N个字节,并尝试将其解析为协议标头。 如果解析失败(例如,无效字段,校验和或MAC),则服务器可以简单地关闭连接。 如果客户端仅发送N-1个字节,则服务器可能会保持连接打开状态来等待剩余的数据。
不是每个服务器实现都有一个关闭阈值。有些可能在遇到错误后一直从连接中读取数据
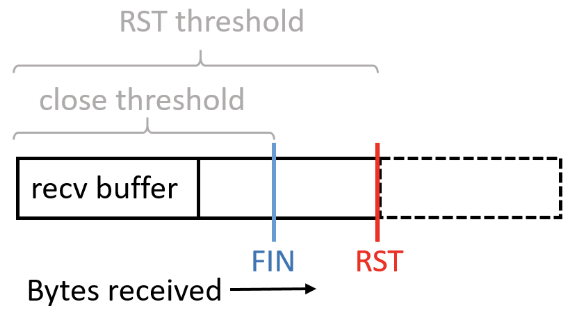 如图1,服务器在接收到一定数量的字节后将使用FIN关闭,在接收到更多字节后可能使用RST关闭。
如图1,服务器在接收到一定数量的字节后将使用FIN关闭,在接收到更多字节后可能使用RST关闭。obfs4的随机关闭阈值在8192到16384字节之间。由于obfs4握手的最大长度为8192个字节,服务器在确定客户端无效后进入closeAfterDelay。 此函数在随机延迟(30-90秒)之后关闭,或者在服务器读取另外的N个字节后关闭连接(N在0到8192之间)。 表II显示了研究的抗探测代理的超时和阈值.

作者开发了一个工具来确定服务器的阈值,并且使用三种不同的随机数据,如果结果一样测标记为确定的阈值,如果不一致则标记为不稳定。
验证
我们向190万个节点发送13个探测(第III-A节中的7个探测和6个随机数据范围为4KB-40KB的探测),并记录服务器是否和何时响应数据或关闭连接。如果服务器关闭,我们将记录它是否使用FIN或RST。如果服务器没有响应或关闭连接,我们将在300秒后超时,并将结果标记为超时。记录他们的关闭阈值。
表三显示了每个非随机探测的结果、由于抗探测代理从不响应数据,因此可以将响应的端点丢弃。在被动Tap数据集中,这排除了94%的主机,只留下26021个潜在代理。在ZMap数据集中,绝大多数主机对任何探测都没有数据响应,仅丢弃1.16%的端点
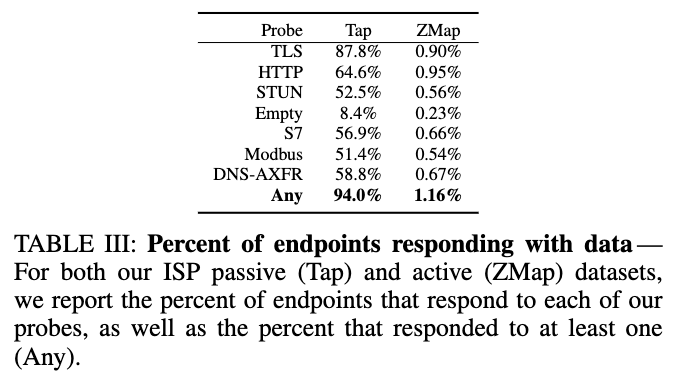
原因是ZMap识别的节点中,防火墙使用了chaff策略,仅在特定的子网上对SYN做出响应。42%的节点行为相同,不发送数据也不关闭与探测器的连接。将响应数据聚类(响应类型、响应字节数、连接关闭时间或超时时间) 在Tap数据集中,最流行的响应组包含3%的端点,似乎是Cloudflare网络中的TLS服务器(99.9%在具有端口443的端点上)。图2显示了ZMap和Tap数据集的不同响应集(按流行程度排序)的CDF,说明Tap数据集中有更大的多样性。前10个响应集占ZMap数据集中超过80%的端点,但只有13%的端点是在Tap中收集的
创建一个决策树
目标:区分没有响应的节点与代理服务器 作者将重点放在手动创建一个决策树,该树可以区分代理和普通节点,因为该树比自动生成的树更易于解释,并且同样有效。
作者使用自动生成的决策树进行评估,但没有发现更高的准确性,并且发现它们比手动构建的决策树需要更多的操作。第一层是有响应的服务器均为正常节点。 第二层是根据协议进行区分。 例如区分obfs4协议如图三,
rand-17k表示17KB大小的随机探测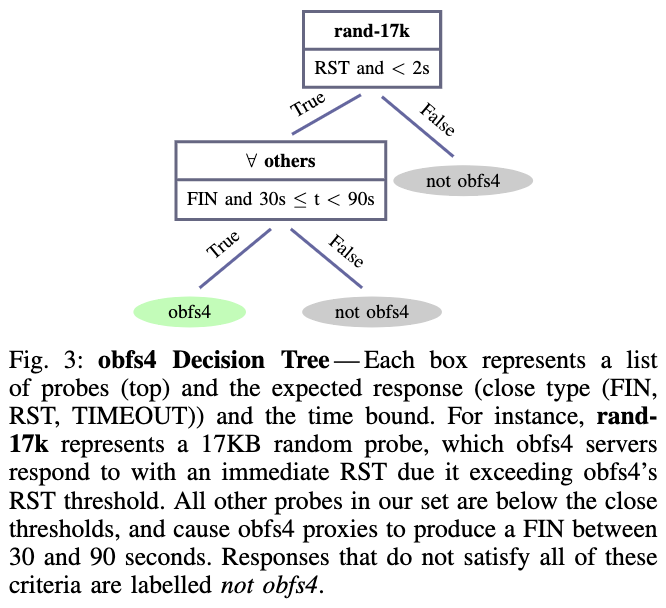
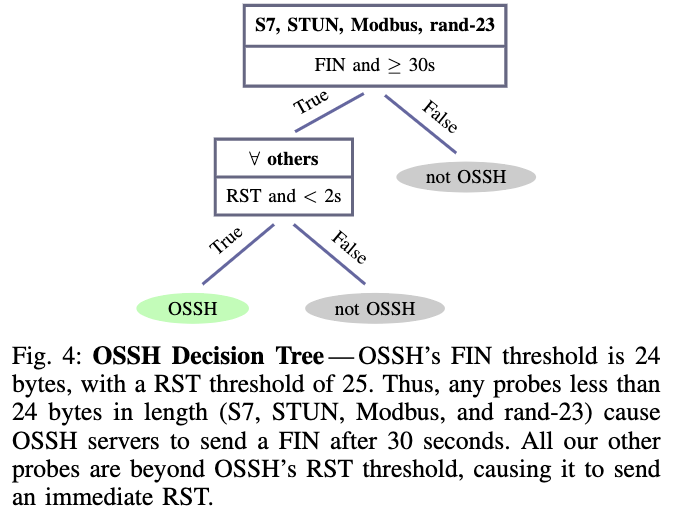
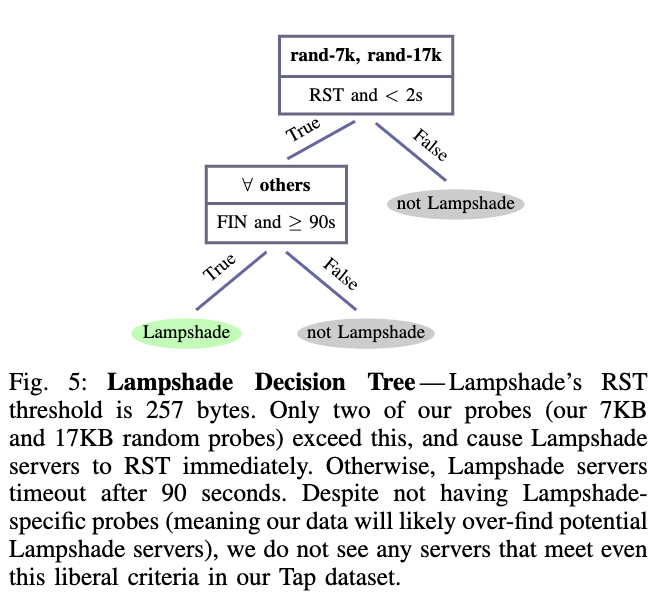
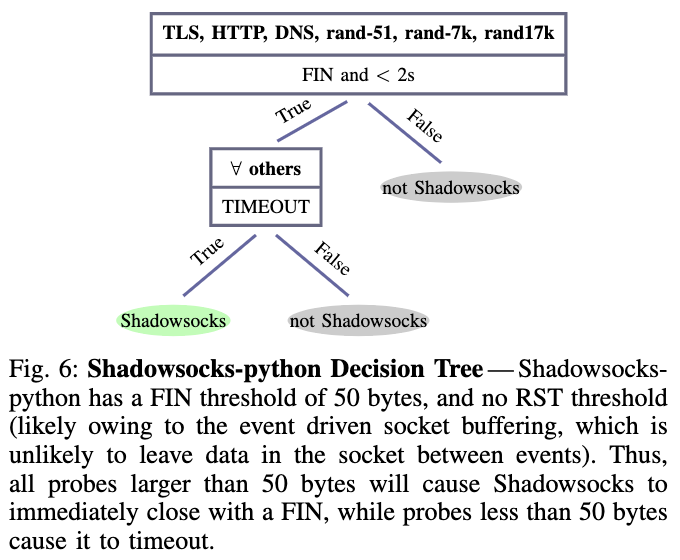
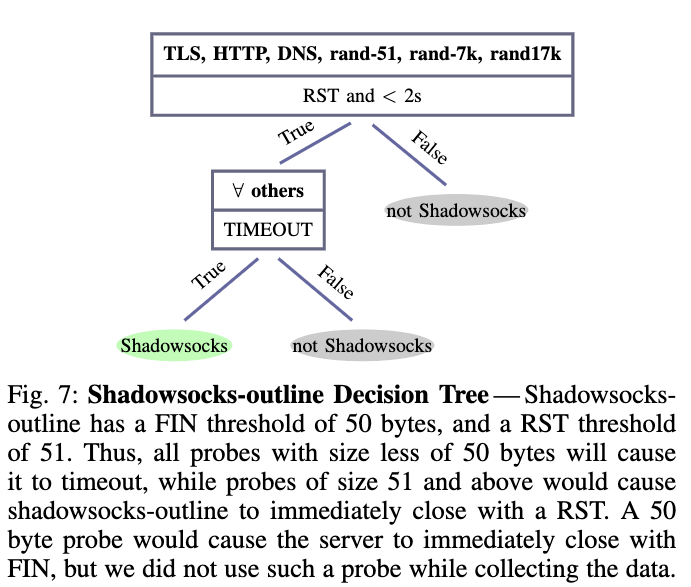
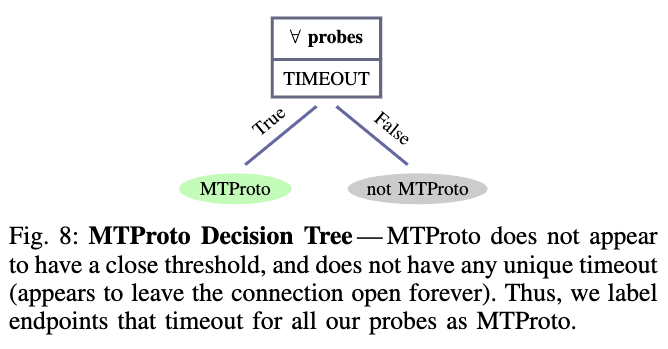 所有代理协议都有互斥的决策树,因此可以按任意顺序检查每个代理,并将不匹配的样本分类为非代理来组成一个多类分类器
所有代理协议都有互斥的决策树,因此可以按任意顺序检查每个代理,并将不匹配的样本分类为非代理来组成一个多类分类器超时
图9显示了在发送空内容和发送1KB随机数据时,Tap数据集的超时分布(以秒为单位)。 该分布在10、15、20、30、60以及超过300秒时比较明显,许多结点根据接收到的数据量而具有不同的超时。Tap数据集中71%的端点对于空和1字节探测具有相同的超时。
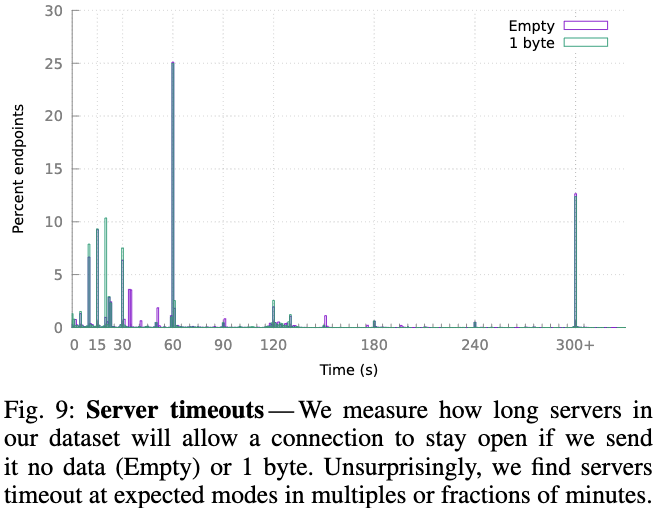
作者提到假如使用随机值超时,例如74s,则会放入0.02%的端点的组中,更容易被发现。
阈值
图11显示了关闭阈值的直方图,最流行的阈值是11和5字节。5字节对应于外部TLS记录头的大小,11字节对应于外部加内部握手头的最小大小。许多TLS实现自然地读取这些头,如果无法解析它们,则关闭连接。代理服务器的关闭阈值则都是独一无二的,仅与0.05%的普通节点相同。只有MTProto观测不到阈值,行为与9%的普通节点相似。
识别协议
验证决策树的效果
obfs4:从Tap数据集中识别的两个疑似obfs4服务器的RST阈值都为10241字节,没有FIN阈值,行为也与obfs4实现不一致,且位置在中国,所以不太可能是代理服务器。
Lampshade-对于Lampshade,ZMap数据集中只标出了一个端点。此节点没有稳定的关闭阈值,因此不是Lampshade实例。这个端点运行在一个主机上,该主机还提供Traccar登录页面,这是一个与GPS跟踪器接口的开源工具
Shadowsocks-决策树将ZMap数据集中的8个端点标识为Shadowsocks-python,所有端点都具有50字节的FIN阈值。我们执行了手动跟踪扫描,发现除了一个端点之外,所有端点都在同一个主机上运行SSH。这些主机分散在世界各地的各种主机网络,虽然没有在审查国家。我们不能肯定这些都是shadowsocks服务器,但是考虑到阈值结果,以及它们的相似性和网络位置,则认为它们很可能是。 如果从ZMap扫描推断,估计全球大约有100万个shadowsocks-python端点在运行。在对已识别的shadowsocks端点进行进一步调查后,5个位于同一宿主提供者)中,每个都有一组不同的700个顺序打开的TCP端口,这些端口都显示出与shadowsocks一致的相同行为。例如,一个IP有打开的TCP端口30000–30699,所有的行为看起来都一样。如果每8个shadowsocks-python服务器中有5个以这种方式打开了700个端口(其他的只有一个端口),那么100万个shadowsocks-python端点将代表着全球有约2285个shadowsocks服务器(唯一的ip)。
决策树还将ZMap数据集中的7个端点标识为shadowsocks-outline。其中6个端点位于韩国的Netropy IP块中,其余位于Cogent的网络中。当作者对这些终点进行手动分析时,它们已经不再开启。
MT Proto-在数据集中,超过3000个端点被归类为MTProto,其中可能很少是真正的MTProto服务器。这是由于用于对MTProto进行分类的简单决策树造成的:许多端点根本不会超时,也没有任何接近的阈值,这使得它们很难彼此区分。这些端点分别代表Tap和ZMap数据集的0.56%和0.02%。这表明MTProto的伪装策略在避免主动探测方面是有效的。
OSSH-将Tap数据集中的8个端点分类为OSSH。作者跟踪了Psiphon,一个流行的规避工具,它通常使用OSSH服务器,并确定其中7个确实是OSSH端点。其余的托管在Linode的443端口上的网络中,但作者无法确认它是否运行OSSH或不相关的服务
假阳性率很低(除了MTProto之外,所有协议的假阳性率都低于0.001%)。作者观察到,MTProto展示了一种有效的行为,使得它很难与一小部分非代理端点(Tap和ZMap数据集的0.56%和0.02%)区分开来。
防御评估
如果代理的响应方式与其他端点常见的响应方式相同,审查人员则更难识别和阻止它们。
探测无关服务器(Probe-indifferent Server),无论发送什么探测,都会以同样的方式响应。 下图是分别是在Tap和Zmap数据集中,探测无关的服务器分布。最常见的行为是从不响应任何探测,即最右侧响应时间超过300ms的部分
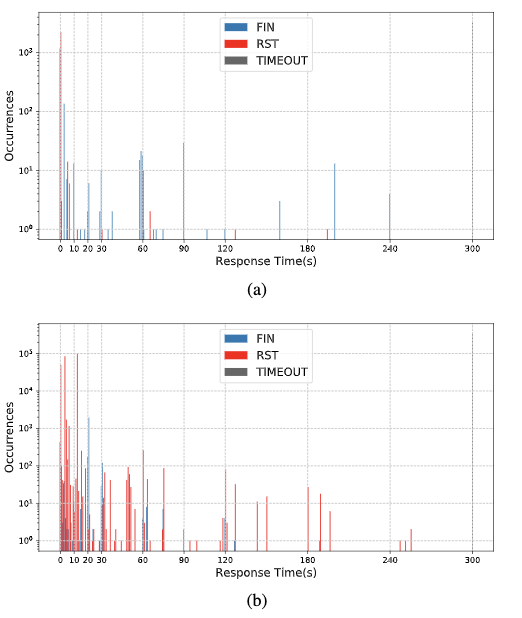
建议代理开发人员对失败的客户端握手实现无限制的超时,保持连接打开而不是关闭。这个策略已经被MTProto服务器所采用,并且已经向其他抵抗探测的代理开发人员提出了实现这个策略的建议。
作者与开发者进行了联系,其中OSSH、obfs4、Shadowsocks-outine、Lampshade通过更新删除了关闭阈值
-
【精读】用BLAST设计一个更好的Tor浏览器
-
【机器学习】sklearn笔记
特征提取
https://scikit-learn.org/stable/modules/feature_extraction.html#loading-features-from-dicts
从dict中提取特征
from sklearn.feature_extraction import DictVectorizer>>> measurements = [ ... {'city': 'Dubai', 'temperature': 33.}, ... {'city': 'London', 'temperature': 12.}, ... {'city': 'San Francisco', 'temperature': 18.}, ... ] >>> from sklearn.feature_extraction import DictVectorizer >>> vec = DictVectorizer() >>> vec.fit_transform(measurements).toarray() array([[ 1., 0., 0., 33.], [ 0., 1., 0., 12.], [ 0., 0., 1., 18.]]) >>> vec.get_feature_names() ['city=Dubai', 'city=London', 'city=San Francisco', 'temperature']数据预处理
from sklearn import preprocessing特征编码
参考:http://scikit-learn.org/stable/modules/preprocessing.html#encoding-categorical-features
下述的特征会自动从数据集中提取,并且可以用
catogories_查看>>> enc.categories_ [array(['female', 'male'], dtype=object), array(['from Europe', 'from US'], dtype=object), array(['uses Firefox', 'uses Safari'], dtype=object)]字符串编码成整数
例如
["from Europe", "from US", "from Asia"]被编码成[1,2,3]使用方法如下>>> enc = preprocessing.OrdinalEncoder() >>> X = [['male', 'from US', 'uses Safari'], ['female', 'from Europe', 'uses Firefox']] >>> enc.fit(X) OrdinalEncoder() >>> enc.transform([['female', 'from US', 'uses Safari']]) array([[0., 1., 1.]])One-Hot编码
>>> enc = preprocessing.OneHotEncoder() >>> X = [['male', 'from US', 'uses Safari'], ['female', 'from Europe', 'uses Firefox']] >>> enc.fit(X) OneHotEncoder() >>> enc.transform([['female', 'from US', 'uses Safari'], ... ['male', 'from Europe', 'uses Safari']]).toarray() array([[1., 0., 0., 1., 0., 1.], [0., 1., 1., 0., 0., 1.]])指定编码目录
提前指定要编码的内容,而不是根据数据集自动生成
>>> genders = ['female', 'male'] >>> locations = ['from Africa', 'from Asia', 'from Europe', 'from US'] >>> browsers = ['uses Chrome', 'uses Firefox', 'uses IE', 'uses Safari'] >>> enc = preprocessing.OneHotEncoder(categories=[genders, locations, browsers]) >>> # Note that for there are missing categorical values for the 2nd and 3rd >>> # feature >>> X = [['male', 'from US', 'uses Safari'], ['female', 'from Europe', 'uses Firefox']] >>> enc.fit(X) OneHotEncoder(categories=[['female', 'male'], ['from Africa', 'from Asia', 'from Europe', 'from US'], ['uses Chrome', 'uses Firefox', 'uses IE', 'uses Safari']]) >>> enc.transform([['female', 'from Asia', 'uses Chrome']]).toarray() array([[1., 0., 0., 1., 0., 0., 1., 0., 0., 0.]])在one-hot编码下,如果数据集中出现了未指定的数据,那么可以使用
handle_unknown='ignore'来忽略报错,在这个情况下,该数据会被设置为全0>>> enc = preprocessing.OneHotEncoder(handle_unknown='ignore') >>> X = [['male', 'from US', 'uses Safari'], ['female', 'from Europe', 'uses Firefox']] >>> enc.fit(X) OneHotEncoder(handle_unknown='ignore') >>> enc.transform([['female', 'from Asia', 'uses Chrome']]).toarray() array([[1., 0., 0., 0., 0., 0.]])
-
Excel公式笔记
随用随记
字符串
字符串拼接
使用&符号即可
字符串截取
例如一个字符串的格式是A@B,要找到A,需要使用LEFT函数和FIND函数
FIND(规则,区域) LEFT(区域,从左开始截取的字符数)所以公式可以写成
=LEFT(A1,FIND("@",A!)-1)统计频次
例如统计范围在0-50和50-100,可以分别这么写
= COUNTIF(D:D,"<50") = COUNTIF(D:D,"<100") - COUNTIF(D:D,"<50")VLOOKUP
=VLOOKUP(用谁去找,匹配对象范围,返回第几列,匹配方式)- 匹配方式:FALSE代表精确匹配,TRUE是近似匹配