最新日志
-
【Python】Colaboratory上传和下载文件
在colab上写的python代码很多时候都有读取文件的需求,本以为将文件直接上传到Google Drive上就可以直接读取,但后来发现两个根本不在一套系统里。colab是每次启动的时候都会随机分配一个新的虚拟机给你,所以数据都不能保存
挂载云端硬盘
from google.colab import drive drive.mount('/content/drive/') import os os.chdir("/content/drive/My Drive/[文件夹]")现用现传
Colaboratory,以下简称colab。相当于一个云端的带GPU的jupyter
上传文件
调用colab的库,运行的时候手动选择要上传的文件
from google.colab import files uploaded = files.upload() file_name = uploaded.keys() print(file_name)运行效果见下图
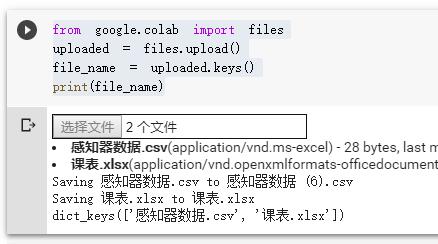
图中我选择了两个文件,upload函数返回值是一个字典,key为文件名,value是文件内容,file_name输出结果如下dict_keys([‘感知器数据.csv’, ‘课表.xlsx’])
因为在python3中返回的key值不再直接是一个list了,所以无法直接索引。解决方法是强制类型转换为list,就可以索引了(这样我才能指定读第几个文件)
file_list = list(file_name) print(file_list)输出是
[‘感知器数据.csv’, ‘课表.xlsx’]
下载文件
from google.colab import files with open('123.txt', 'w') as f: f.write('some content') files.download('123.txt')
参考:
-
【机器学习】PRML学习笔记-多类感知器算法
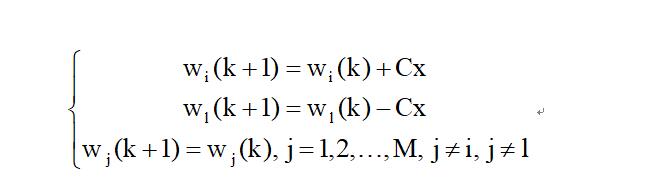 其中C是一个正常数。权向量的初始值wi(1),i = 1,2,…,M可视情况任意选择
其中C是一个正常数。权向量的初始值wi(1),i = 1,2,…,M可视情况任意选择
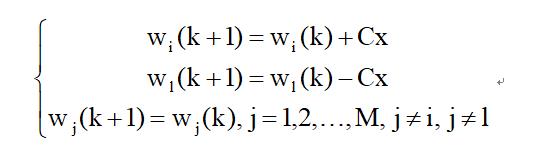
第1轮迭代,以x1=[-1 -1 1]作为训练样本:
d1[1]=w1(1)X1=0
d2[1]=w2(1)X2=0
d3[1]=w3(1)X3=0
∵d1(1)<=d2(1),∴w2(2)=w2(1)-x1=[ 1. 1. -1.]
∵d1(1)<=d3(1),∴w3(2)=w3(1)-x1=[ 1. 1. -1.]
∴w1(2)=w1(1)+x1=[-1. -1. 1.]
第2轮迭代,以x2=[0 0 1]作为训练样本:
d1[2]=w1(2)X1=1
d2[2]=w2(2)X2=-1
d3[2]=w3(2)X3=-1
∵d2(2)<=d3(2),∴w3(3)=w3(2)-x2=[ 1. 1. -2.]
∵d2(2)<=d1(2),∴w1(3)=w1(2)-x2=[-1. -1. 0.]
∴w2(3)=w2(2)+x2=[1. 1. 0.]
第3轮迭代,以x3=[1 1 1]作为训练样本:
d1[3]=w1(3)X1=-2
d2[3]=w2(3)X2=2
d3[3]=w3(3)X3=0
∵d3(3)<=d2(3),∴w2(4)=w2(3)-x3=[ 0. 0. -1.]
∴w3(4)=w3(3)+x3=[ 2. 2. -1.]
第4轮迭代,以x1=[-1 -1 1]作为训练样本:
d1[4]=w1(4)X1=2
d2[4]=w2(4)X2=-1
d3[4]=w3(4)X3=-5
第5轮迭代,以x2=[0 0 1]作为训练样本:
d1[5]=w1(5)X1=0
d2[5]=w2(5)X2=-1
d3[5]=w3(5)X3=-1
∵d2(5)<=d3(5),∴w3(6)=w3(5)-x2=[ 2. 2. -2.]
∵d2(5)<=d1(5),∴w1(6)=w1(5)-x2=[-1. -1. -1.]
∴w2(6)=w2(5)+x2=[0. 0. 0.]
第6轮迭代,以x3=[1 1 1]作为训练样本:
d1[6]=w1(6)X1=-3
d2[6]=w2(6)X2=0
d3[6]=w3(6)X3=2
第7轮迭代,以x1=[-1 -1 1]作为训练样本:
d1[7]=w1(7)X1=1
d2[7]=w2(7)X2=0
d3[7]=w3(7)X3=-6
第8轮迭代,以x2=[0 0 1]作为训练样本:
d1[8]=w1(8)X1=-1
d2[8]=w2(8)X2=0
d3[8]=w3(8)X3=-2
第9轮迭代,以x3=[1 1 1]作为训练样本:
d1[9]=w1(9)X1=-3
d2[9]=w2(9)X2=0
d3[9]=w3(9)*X3=2权向量w为: [[-1. -1. -1.]
[ 0. 0. 0.]
[ 2. 2. -2.]]
-
【机器学习】PRML学习笔记-感知器
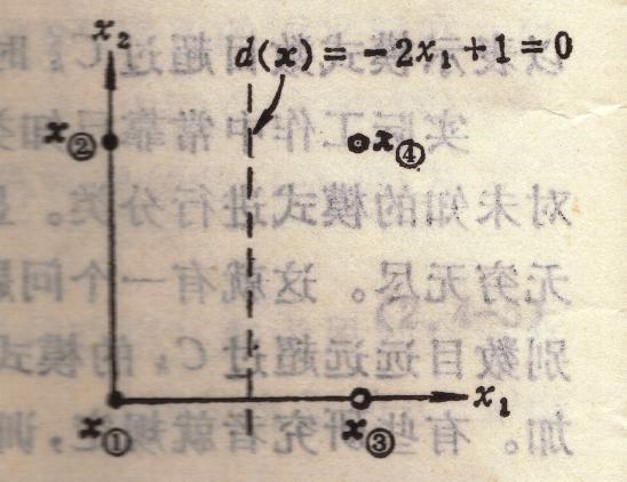
作业如下

代码如下
# -*- coding: utf-8 -*- """感知器算法.ipynb Automatically generated by Colaboratory. Original file is located at https://colab.research.google.com/drive/1uMcSUjFe0Sz3yInk2ir5xoBnFwmlsIpp """ # -*- coding:utf-8 import numpy as np a = [[0,0,0],[1,0,0],[1,0,1],[1,1,0]] b = [[0,0,1],[0,1,1],[0,1,0],[1,1,1]] dim=3 #数据定义 a_num = len(a) b_num = len(b) a_array=[] for i in range(a_num): a[i].append(1) tmp_narry = np.array(a[i]) print(tmp_narr) a_array.append(tmp_narry) # 对属于b的样本,先增广,再乘以-1 b_array=[] for i in range(b_num): b[i].append(1) b[i] = np.dot(b[i],-1) tmp_narry = np.array(b[i]) print(tmp_narr) b_array.append(tmp_narry) array = a_array+b_array # 设定初始的w为(0,0,0,0)T w = np.zeros(dim+1).T # 取矫正向量为1 C = 1 # 分别为参数的序号和迭代的次数 w_num = 0 iter_num = 1 while True: #flag默认为false,如果本轮迭代中出现了分类错误的情况 #则变更为True flag = False print("第%d轮迭代:"%iter_num) for arr in array: res = np.dot(arr,w) print(arr,"*",w,end='') if res<=0: print("="+str(res)+"<=0",end=' ') print("故w("+str(w_num+1)+")=w("+str(w_num)+")+",arr) w = w + np.dot(arr,C) flag=True else: print("="+str(res)+">0",end=' ') print("故w("+str(w_num+1)+")=w("+str(w_num)+")") w_num = w_num + 1 iter_num = iter_num + 1 #迭代次数超过999次先结束运行 if flag==False or iter_num>999: break print("w:",w) print("d(x)="+str(w[0])+"*X1+"+str(w[1])+"*X2+"+str(w[2])+"*X3+"+str(w[3]))点此下载ipynb文件(可以直接在jupyter或colab中运行)
运行结果为:
第1轮迭代:
[0 0 0 1] * [0. 0. 0. 0.]=0.0<=0 故w(1)=w(0)+ [0 0 0 1]
[1 0 0 1] * [0. 0. 0. 0.5]=0.5>0 故w(2)=w(1)
[1 0 1 1] * [0. 0. 0. 0.5]=0.5>0 故w(3)=w(2)
[1 1 0 1] * [0. 0. 0. 0.5]=0.5>0 故w(4)=w(3)
[ 0 0 -1 -1] * [0. 0. 0. 0.5]=-0.5<=0 故w(5)=w(4)+ [ 0 0 -1 -1]
[ 0 -1 -1 -1] * [ 0. 0. -0.5 0. ]=0.5>0 故w(6)=w(5)
[ 0 -1 0 -1] * [ 0. 0. -0.5 0. ]=0.0<=0 故w(7)=w(6)+ [ 0 -1 0 -1]
[-1 -1 -1 -1] * [ 0. -0.5 -0.5 -0.5]=1.5>0 故w(8)=w(7)
第2轮迭代:
[0 0 0 1] * [ 0. -0.5 -0.5 -0.5]=-0.5<=0 故w(9)=w(8)+ [0 0 0 1]
[1 0 0 1] * [ 0. -0.5 -0.5 0. ]=0.0<=0 故w(10)=w(9)+ [1 0 0 1]
[1 0 1 1] * [ 0.5 -0.5 -0.5 0.5]=0.5>0 故w(11)=w(10)
[1 1 0 1] * [ 0.5 -0.5 -0.5 0.5]=0.5>0 故w(12)=w(11)
[ 0 0 -1 -1] * [ 0.5 -0.5 -0.5 0.5]=0.0<=0 故w(13)=w(12)+ [ 0 0 -1 -1]
[ 0 -1 -1 -1] * [ 0.5 -0.5 -1. 0. ]=1.5>0 故w(14)=w(13)
[ 0 -1 0 -1] * [ 0.5 -0.5 -1. 0. ]=0.5>0 故w(15)=w(14)
[-1 -1 -1 -1] * [ 0.5 -0.5 -1. 0. ]=1.0>0 故w(16)=w(15)
第3轮迭代:
[0 0 0 1] * [ 0.5 -0.5 -1. 0. ]=0.0<=0 故w(17)=w(16)+ [0 0 0 1]
[1 0 0 1] * [ 0.5 -0.5 -1. 0.5]=1.0>0 故w(18)=w(17)
[1 0 1 1] * [ 0.5 -0.5 -1. 0.5]=0.0<=0 故w(19)=w(18)+ [1 0 1 1]
[1 1 0 1] * [ 1. -0.5 -0.5 1. ]=1.5>0 故w(20)=w(19)
[ 0 0 -1 -1] * [ 1. -0.5 -0.5 1. ]=-0.5<=0 故w(21)=w(20)+ [ 0 0 -1 -1]
[ 0 -1 -1 -1] * [ 1. -0.5 -1. 0.5]=1.0>0 故w(22)=w(21)
[ 0 -1 0 -1] * [ 1. -0.5 -1. 0.5]=0.0<=0 故w(23)=w(22)+ [ 0 -1 0 -1]
[-1 -1 -1 -1] * [ 1. -1. -1. 0.]=1.0>0 故w(24)=w(23)
第4轮迭代:
[0 0 0 1] * [ 1. -1. -1. 0.]=0.0<=0 故w(25)=w(24)+ [0 0 0 1]
[1 0 0 1] * [ 1. -1. -1. 0.5]=1.5>0 故w(26)=w(25)
[1 0 1 1] * [ 1. -1. -1. 0.5]=0.5>0 故w(27)=w(26)
[1 1 0 1] * [ 1. -1. -1. 0.5]=0.5>0 故w(28)=w(27)
[ 0 0 -1 -1] * [ 1. -1. -1. 0.5]=0.5>0 故w(29)=w(28)
[ 0 -1 -1 -1] * [ 1. -1. -1. 0.5]=1.5>0 故w(30)=w(29)
[ 0 -1 0 -1] * [ 1. -1. -1. 0.5]=0.5>0 故w(31)=w(30)
[-1 -1 -1 -1] * [ 1. -1. -1. 0.5]=0.5>0 故w(32)=w(31)
第5轮迭代:
[0 0 0 1] * [ 1. -1. -1. 0.5]=0.5>0 故w(33)=w(32)
[1 0 0 1] * [ 1. -1. -1. 0.5]=1.5>0 故w(34)=w(33)
[1 0 1 1] * [ 1. -1. -1. 0.5]=0.5>0 故w(35)=w(34)
[1 1 0 1] * [ 1. -1. -1. 0.5]=0.5>0 故w(36)=w(35)
[ 0 0 -1 -1] * [ 1. -1. -1. 0.5]=0.5>0 故w(37)=w(36)
[ 0 -1 -1 -1] * [ 1. -1. -1. 0.5]=1.5>0 故w(38)=w(37)
[ 0 -1 0 -1] * [ 1. -1. -1. 0.5]=0.5>0 故w(39)=w(38)
[-1 -1 -1 -1] * [ 1. -1. -1. 0.5]=0.5>0 故w(40)=w(39)
w: [ 1. -1. -1. 0.5]
d(x)=1.0X1+-1.0X2+-1.0*X3+0.5
-
【会议粗读】28th USENIX Security Symposium
- Phishing and Scams
- Web Attacks
- All Your Clicks Belong to Me: Investigating Click Interception on the Web
- Iframes/Popups Are Dangerous in MobileWebView:Studying and Mitigating Differential Context Vulnerabilities
- Leaky Images: Targeted Privacy Attacks in the Web
- SmallWorld with High Risks:A Study of Security Threats in the npm Ecosystem
- What Are You Searching For?A Remote Keylogging Attack on Search Engine Autocomplete
- Web Defences
- Everyone is Different: Client-side Diversification for Defending Against Extension Fingerprinting
- Less isMore: Quantifying the Security Benefits of Debloating Web Applications
- Rendered Private: Making GLSL Execution Uniform to Prevent WebGL-based Browser Fingerprinting
- Site Isolation: Process Separation for Web Sites within the Browser
- The Web’s Identity Crisis:Understanding the Effectiveness of Website Identity Indicators
- Wireless Security
- A Billion Open Interfaces for Eve and Mallory: MitM, DoS, and Tracking Attacks on iOS and macOS Through AppleWireless Direct Link
- A Study of the Feasibility of Co-located App Attacks against BLE and a Large-Scale Analysis of the Current Application-Layer Security Landscape
- Hiding in Plain Signal: Physical Signal Overshadowing Attack on LTE
- The CrossPath Attack: Disrupting the SDN Control Channel via Shared Links
- UWB-ED: Distance Enlargement Attack Detection in Ultra-Wideband
- Machine learning Applications
- ALOHA: Auxiliary Loss Optimization for Hypothesis Augmentation
- Improving Robustness of ML Classifiers against Realizable Evasion Attacks Using Conserved Features
- Stack Overflow Considered Helpful! Deep Learning Security Nudges Towards Stronger Cryptography
- The Secret Sharer: Evaluating and Testing Unintended Memorization in Neural Networks
- Why Do Adversarial Attacks Transfer? Explaining Transferability of Evasion and Poisoning Attacks
- Passwords
- Hardware Security
- Planes,Cars and Robots
- CANvas: Fast and Inexpensive AutomotiveNetwork Mapping
- Losing the Car Keys: Wireless PHY-Layer Insecurity in EV Charging
- Please Pay Inside: Evaluating Bluetooth-based Detection of Gas Pump Skimmers
- RVFUZZER: Finding Input Validation Bugs in Robotic Vehicles Through Control-Guided Testing
- Wireless Attacks on Aircraft Instrument Landing Systems
- Protecting Users Everywhere
- Clinical Computer Security for Victims of Intimate Partner Violence
- Computer Security and Privacy in the Interactions Between Victim Service Providers and Human Trafficking Survivors
- Evaluating the Contextual Integrity of Privacy Regulation: Parents’ IoT Toy Privacy Norms Versus COPPA
- Secure Multi-User Content Sharing for Augmented Reality Applications
- Understanding and Improving Security and Privacy in Multi-User Smart Homes: A Design Exploration and In-Home User Study
- Machine Learning, Adversarial and Otherwise
- CSI NN: Reverse Engineering of Neural Network Architectures Through Electromagnetic Side Channel
- CT-GAN: Malicious Tampering of 3D Medical Imagery using Deep Learning
- Misleading Authorship Attribution of Source Code using Adversarial Learning
- Seeing is Not Believing: Camouflage Attacks on Image Scaling Algorithms
- Terminal Brain Damage: Exposing the Graceless Degradation in Deep Neural Networks Under Hardware Fault Attacks
- Mobile Security
- 50 Ways to Leak Your Data: An Exploration of Apps’ Circumvention of the Android Permissions System
- Devils in the Guidance: Predicting Logic Vulnerabilities in Payment Syndication Services through Automated Documentation Analysis
- EnTrust: Regulating Sensor Access by Cooperating Programs via Delegation Graphs
- HideMyApp : Hiding the Presence of Sensitive Apps on Android
- PolicyLint: Investigating Internal Privacy Policy Contradictions on Google Play
- simTPM: User-centric TPM for Mobile Devices
- TESSERACT: Eliminating Experimental Bias in Malware Classification across Space and Time
- The Betrayal At Cloud City: An Empirical Analysis Of Cloud-Based Mobile Backends
- Software Security
- Back to the Whiteboard: a Principled Approach for the Assessment and Design of Memory Forensic Techniques
- CONFIRM: Evaluating Compatibility and Relevance of Control-flow Integrity Protections for Modern Software
- DEEPVSA: Facilitating Value-set Analysis with Deep Learning for Postmortem Program Analysis
- Detecting Missing-Check Bugs via Semantic- and Context-Aware Criticalness and Constraints Inferences
- RAZOR: A Framework for Post-deployment Software Debloating
- Privacy
- Evaluating Differentially Private Machine Learning in Practice
- No Right to Remain Silent: Isolating Malicious Mixes
- On (The Lack Of) Location Privacy in Crowdsourcing Applications
- Point Break: A Study of Bandwidth Denial-of-Service Attacks against Tor
- Utility-Optimized Local Differential Privacy Mechanisms for Distribution Estimation
- Iot Security
- All Things Considered: An Analysis of IoT Devices on Home Networks
- Discovering and Understanding the Security Hazards in the Interactions between IoT Devices, Mobile Apps, and Clouds on Smart Home Platforms
- FIRM-AFL: High-Throughput Greybox Fuzzing of IoT Firmware via Augmented Process Emulation
- Looking from the Mirror: Evaluating IoT Device Security through Mobile Companion Apps
- Not Everything is Dark and Gloomy: Power Grid Protections Against IoT Demand Attacks
- Crypto Means Cryptocurrencies
- Cryptocurrency Scams
- Intelligence and Vulnerabilities
- ATTACK2VEC: Leveraging TemporalWord Embeddings to Understand the Evolution of Cyberattacks
- Reading the Tea leaves: A Comparative Analysis of Threat Intelligence
- Towards the Detection of Inconsistencies in Public Security Vulnerability Reports
- Understanding and Securing Device Vulnerabilities through Automated Bug Report Analysis
目前读了“Phising and Scams”,“Web Attacks”,“Web Defences”,“Wireless Security”,“Machine learning Applications”,“Passwords”,“Hardware Security”,“Planes,Cars and Robots”,“Protecting Users Everywhere”,“Machine Learning, Adversarial and Otherwise”,“Mobile Security”,“Software Security”,“Privacy”,“Iot Security”,“Crypto Means Cryptocurrencies”,“Cryptocurrency Scams”,“ Intelligence and Vulnerabilities”共17个部分,83篇文章
Phishing and Scams
Cognitive Triaging of Phishing Atccaks
这一篇论文的主题是利用认知心理学和计量经济学以及自然语言处理,对钓鱼邮件的攻击成功的可能性进行预测,并对钓鱼邮件进行分类。
他们的方法是对一家反钓鱼机构收到的8万封钓鱼邮件进行分析,利用认知心理学对邮件中的“认知脆弱性因素”进行量化,并与邮件的点击次数相联系建立了一个分类模型。 感觉这篇文章的内容比较抽象,大致是用到了一些心理学的方法来分析钓鱼邮件中的认知漏洞,最终证明这些认知漏洞和收件人受骗是有相关性的。Detecting and Characterizing Lateral Phishing at Scale
在刚开始读这篇论文的时候,接触到了一个之前不知道的词,叫Lateral Phising Attacks,翻译成中文是横向钓鱼攻击。于是我在Google上搜到了一篇文章讲的横向钓鱼攻击 Lateral Phishing Attacks: A Growing Threat to the Enterprise,了解到横向钓鱼攻击的主要形式是攻击者黑入一个企业内部的账户,然后通过这个账户向组织内部的其他人发送钓鱼邮件。
他们在论文上说明他们主要有两个贡献:第一个是开发了一个分类器,可以在现实世界中检测到横向钓鱼邮件。根据测试,在一个涵盖了93个企业的1.14亿封邮件中,该分类器可以成功检测到87.3%的攻击,并且每100万封邮件中只有不到4封产生误报。
第二个贡献是首次详细并且大规模的描述了横向网络钓鱼的现状以及他们的常见策略。
后面粗略的了解了一下这个分类器的原理,主要是通过检测邮件中是否包含可疑的并且诱惑人去点击的URL,并且分析这个发件人历史发件情况进行分析,来判断这是否是一封横向钓鱼邮件。High Precision Detection of Business Email Compromise
这篇文章的关键词是“business email compromise”,即商业电子邮件入侵,而且主要面向的对象是公司或者组织,一开始我还有一些疑惑这个和上一篇论文中的横向钓鱼的区别,然后我在google搜了一下关键词,找到一篇来自自fbi.gov的文章Business email compromise,里面讲到攻击者的做法一般是使用一个地址非常接近的邮箱来冒充成一个可信的人,然后发邮件来诈骗。
所以在这里我理解的两者的区别就像是,前者是盗取qq号来向好友诈骗,后者是新建一个qq号冒充成一个现实存在的人来诈骗。
这篇的文章主要内容是介绍一个来自Barracuda Networks的检测器,可以实时的阻止BEC攻击,评估后显示该检测器的准确率高达98.2%,误报率不到五万分之一。Platforms in Everything:Analyzing Ground-Truth Data on the Anatomy and Economics of Bullet-Proof Hosting
题目中又提到了一个我从未听过的新词“Bullet-Proof Hosting”(BPH),翻译成中文是防弹托管。于是先搜了一下关键词,What is bulletproof hosting?这篇来自诺顿的文章详细讲了什么是防弹托管,即很多网站因为当地的法律原因不方便存储一些内容,所以防弹托管的服务商为这些非法的内容提供托管服务。
这篇文章的内容讲的是对一家被查封的BPH提供商的服务器数据进行了研究,从而进一步分析BPH的业务。Users Really Do Answer Telephone Scams
电话诈骗是这篇文章的研究的主题,与计算机网络关系不大。最后的结论大致是伪造号码的电话诈骗成功率较高,比较好的应对方法是提高用户的安全意识。
Web Attacks
All Your Clicks Belong to Me: Investigating Click Interception on the Web
这篇文章研究了普遍存在的点击拦截,点击拦截会引导用户进入其他的网站。
作者们开发了一款名为OBSERVER的框架,可以自动检测网站上的点击拦截情况,最后一共在617个网站上检测到了437个点击拦截的第三方脚本,这些网站的总访问量为4300万次/天,最后对这些点击拦截的方法和意图进行了分析。Iframes/Popups Are Dangerous in MobileWebView:Studying and Mitigating Differential Context Vulnerabilities
这篇文章讲到了一个安卓手机上存在的webview漏洞,简称DCVs,危害性很大。作者的贡献是开发了一个名为DVC-Hunter的工具,可以自动审查安卓app中漏洞存在的情况,结果发现很多知名的应用程序都受到了这个漏洞的影响,最后设计了一个解决方案,可以增强webview的安全性。
Leaky Images: Targeted Privacy Attacks in the Web
这篇文章提出了一个新概念叫Leaky Images,这是一个可以判断指定用户是否正在访问指定网站的漏洞,因为我自己很少用到里面提到的图片共享服务,所以来回读了好几遍才大致懂这个漏洞的原理。
比如A是攻击者,B是受害者,A想知道B是否访问过网站C。步骤如下:A首先通过某个图片共享网站D给B分享了一张图片P,并且指定只有B才有权限看这个照片。接下来A需要控制这个网站C,并且当有用户访问这个网站C时,这个网站都要通过浏览器来向向网站D请求访问图片P,当这个请求成功的时候,则证明是B访问过了网站C。
这里面提到隐私泄漏的原因是图像不受同源策略的约束,图片共享服务是通过cookies来验证用户的身份,
SmallWorld with High Risks:A Study of Security Threats in the npm Ecosystem
随着javascript的流行,npm作为一个大型的第三方js包的平台,从2010年成立到2019年2月已经有超过80万个包。npm系统是开放的,允许用户自由的共享和重用代码,并且可以不受限制的共享一个包到社区中,这就导致如果一个包被破坏或者被恶意修改,可能会影响到很多依赖此包的其他包或者应用程序。
这篇文章系统的分析了npm生态系统中的安全风险,并给出了降低风险的建议。What Are You Searching For?A Remote Keylogging Attack on Search Engine Autocomplete
用户在搜索引擎上搜索的文字一般都是加密传给服务器的,但是现在的搜索引擎有一个自动补全的功能,即根据当前搜索框里的文字给用户提供建议。因为自动补全的功能要求客户端实时传输给服务器用户输入的文字,所以作者提出了一种攻击方法来获取用户敲入的内容。
具体实现过程看起来比较复杂,是用神经网络训练了一个模型,根据流量包中的各个数据(如包到达的时间,空格字符的比例)对内容进行预测,最后能准确的描述90%以上的单词。Web Defences
Everyone is Different: Client-side Diversification for Defending Against Extension Fingerprinting
现在用户浏览器中安装了很多拓展来实现不同的功能,但是这也可能导致隐私的泄漏,因为可以通过用户安装的拓展来推断用户的想法。文章讲到之前有一种通过war来检测浏览器拓展的方法,因为在排名前1000的浏览器拓展中有超过50%使用了war。后来又出现了名为XHOUND的系统,可以识别排名前5万中超过10%的插件.
这篇文章提出了一种解决方案CloakX,通过随机化的修改拓展插件的指纹属性,来防止被网页读取到用户使用的插件。Less isMore: Quantifying the Security Benefits of Debloating Web Applications
题目中出现的debloating单词,我用了多个翻译软件依然无法翻译出准确的意思,根据上下文的理解debloating web applications的含义是减少web应用程序中冗余的代码。这篇论文的主题比较抽象,在于去除可能有漏洞的代码,来减少攻击面。
Rendered Private: Making GLSL Execution Uniform to Prevent WebGL-based Browser Fingerprinting
因为没接触过webGL相关的东西,所以不太理解。大意是基于浏览器用webGL会被辨别出来(fingerprinting),所以作者提出了一个新的系统叫UNIGL,并且开源成为了一个浏览器插件。
Site Isolation: Process Separation for Web Sites within the Browser
翻来覆去看了好几遍introduction也没怎么读懂,就是觉得好像做了一个很厉害的技术,果然仔细一看三个作者都是来自谷歌公司的。文章讲了一个名为站点隔离的技术,可以阻止很多web攻击,目前已经应用在了chrome浏览器上。
The Web’s Identity Crisis:Understanding the Effectiveness of Website Identity Indicators
目前用户判断当前网站是否可信的方法一般是通过URL和HTTPS的标识,另外还有一种叫HTTPS Extended Validation简称EV的标识,可以标出当前访问的网站所属的组织。作者也是来自谷歌的,他做了一个大规模的实验,来判断EV对用户行为的影响,但结果证明EV几乎没有价值,所以需要建立更加有效的网站识别机制。
Wireless Security
A Billion Open Interfaces for Eve and Mallory: MitM, DoS, and Tracking Attacks on iOS and macOS Through AppleWireless Direct Link
苹果的airdrop功能是一个非常便捷的功能,原理是基于苹果自己定义的AWDL协议,这个协议结合了WiFi和BLE(低功耗蓝牙)。然而作者发现这个协议中存在漏洞,可能出现中间人攻击,或者使周边所有的设备崩溃。而且只需要20美元的成本就可以实现这种攻击。作者们希望在公布这个漏洞后,苹果可以及时的发布补丁。
A Study of the Feasibility of Co-located App Attacks against BLE and a Large-Scale Analysis of the Current Application-Layer Security Landscape
这篇文章讲了BLE的安全性。BLE设备上可能存储着很多敏感的数据,这些数据一般情况下是受到BLE自身安全机制的保护,只有经过身份验证才能访问。但是在作者们对超过18900个支持BLE的安卓应用进行分析后,发现有超过45%的APP没有保护BLE数据的措施,所以大量的BLE设备可能受到攻击。
Hiding in Plain Signal: Physical Signal Overshadowing Attack on LTE
这个文章讲的是对LTE广播消息的一个注入攻击,这个新型的攻击被称为SigOver,并且成功率相比于假基站还要高。
The CrossPath Attack: Disrupting the SDN Control Channel via Shared Links
SDN网络上的控制通道存在Dos攻击的风险,一小部分流量就可以破坏控制信道上的通信。所以作者们提出了一种破坏SDN控制信道的攻击,可以显著的降低网络的性能,并且这种攻击不容易被察觉。
UWB-ED: Distance Enlargement Attack Detection in Ultra-Wideband
这里面提到两个设备之间进行距离测量的方法是交换信号,并且根据时延来推算距离差,但是这种方法无法防止对抗性的距离增大(adversarial distance enlargement)。这个对抗性的距离增大的原理是先干扰原始的信号,然后再延迟发出之前的传输信号,这样子就会导致两个设备之间的距离测量是不准确的,目前还没有方法来处理这种攻击,但是作者们提出了一种名为UWB—ED的技术,可以检测到这种攻击。
Machine learning Applications
ALOHA: Auxiliary Loss Optimization for Hypothesis Augmentation
这篇文章的内容更多的偏向于机器学习的理论,大致讲的是已有一个分类器可以给定一个软件,来判断是否是恶意软件,然后作者优化了分类的方法和参数,让分类器的性能更好。
Improving Robustness of ML Classifiers against Realizable Evasion Attacks Using Conserved Features
目前机器学习被广泛用于分辨软件是否是恶意软件,然而有些时候攻击者可以刻意修改软件中的某些特征来跟分类器做对抗,这样分类器就可能把一个恶意软件分类成为一个良性软件。这篇文章讲的是对分类器的鲁棒性进行优化。
Stack Overflow Considered Helpful! Deep Learning Security Nudges Towards Stronger Cryptography
很多程序员都会使用stack overflow这个平台,之前我遇到某些技术上的问题时,很多也是只有这个平台才能找到类似的解决方案。最近的研究发现很多软件中不安全的加密代码都是来自于stack overflow,因为很多程序员并不是很懂加密,所以就简单的把不安全的代码复制到了应用程序中。所以这篇文章大意是给出了一个基于深度神经网络的系统,可以在应用加密代码的时候给程序员建议(不太理解这种方式,原文中说要修改Stack overflow)
The Secret Sharer: Evaluating and Testing Unintended Memorization in Neural Networks
这个文章讲到了一个很现实的问题,就是神经网络可能会无意识的记住一些训练数据,这样就会导致训练数据意外的泄漏。文章里举了一个例子是一个文本预测的模型,在输入“我的信用卡号是”,结果后面预测出现的文本是别人的信用卡号,这就是神经网络无意中记住了训练模型的内容。最后作者应该是给出了一个保护数据隐私的模型训练方法。
Why Do Adversarial Attacks Transfer? Explaining Transferability of Evasion and Poisoning Attacks
这篇文章的字面意思是对规避、中毒攻击的可转移性进行了评价,但是对这些名词我都不太了解。我大致理解这个作者做的是尽可能避免模型在训练的时候,被攻击者从训练的数据集上攻击。
Passwords
Birthday, Name and Bifacial-security: Understanding Passwords of Chinese Web Users
这篇文章的作者是中国人,主题是对中国人使用的密码的安全性进行了分析。并且特别指出相对于英文密码,对于在线攻击的抵抗力较弱,但对于离线攻击的抵抗力较强。
Probability Model Transforming Encoders Against Encoding Attacks Haibo
文章中讲到目前有三种密码来抵抗攻击,第一种是复杂的密码(比如第三方密码软件生成的复杂的密码,很难靠暴力猜解出来),第二种是使用服务器或者生物识别技术作为双重验证(也就是指纹验证或者验证码技术一类的,一般也难以破解)。第三种是一个新的加密方案叫Honey Encryption(HE),大意是用错误的口令误导攻击者,即使密码很简单攻击者也猜不出来。作者们对第三种方案进行了分析。
Protecting accounts from credential stuffing with password breach alerting
credential stuffing attacks翻译成中文的意思是撞库攻击。目前很多用户的密码已经在别的网站被泄漏了,但是用户很难知道自己的账户密码是否已经泄漏,所以仍在继续使用,这样子就有很大的安全隐患。这篇文章的作者大部分来自谷歌,他们提出了一个新的安全协议,可以查询当前的用户名和密码是否已经泄漏,并提示给用户,最后把这个服务做成了一个Chrome浏览器的拓展插件。
Hardware Security
HardFails: Insights into Software-Exploitable Hardware Bugs
芯片设计上如果存在漏洞,就可能遭受到基于软件的跨层攻击,而且硬件上的漏洞有可能是无法修补的。所以作者们开发了一个基于RISC-V的RTL bug测试平台,可以识别出特定类型的漏洞。
A Systematic Evaluation of Transient Execution Attacks and Defenses
文章的作者提出了一种新的瞬时攻击,并系统的评估了防御方法。
Origin-sensitive Control Flow Integrity
文章全都围绕着Control Flow Intergrity(CFI)讲的,里面介绍到CFI是一个防御control-flow劫持的方法,主要适用于C/C++。文章的贡献是为CFI提出了一个新的背景,以增强安全性。
PAC it up: Towards Pointer Integrity using ARM Pointer Authentication
这里讲到C/C++是内存不安全的编程语言,他们编写的程序可能通过指针或地址破坏计算机系统。ARM-v8A体系结构中新增了名为Pointer Authentication(PA)的指令,用来保护指针的完整性。作者的贡献是提出了一个改进的PA方案,基于PA制作了一个名为PARTS的工具框架,提供了比PA更好的保护。
uXOM: Efficient eXecute-Only Memory on ARM Cortex-M
目前有一种内存保护机制名为eXecute-Only_Memory(XOM),里面定义特殊的内存区域,只允许指令运行,但不允许数据读写。目前很多高端处理器都已经支持了XOM,但是低端处理器还不支持XOM,所以这篇文章提出了uXOM,可以在Cortex-M系列的处理器上工作。
Planes,Cars and Robots
CANvas: Fast and Inexpensive AutomotiveNetwork Mapping
这个文章关于汽车网络的安全,作者开发了一个汽车网络映射工具,帮助识别车辆的ecu及其之间的通信。
Losing the Car Keys: Wireless PHY-Layer Insecurity in EV Charging
这篇文章有关于电磁窃听。目前电动汽车充电时的电缆也会作为通信通道,传输一些敏感的数据,目前的联合充电系统(CCS)的物理层受到无限攻击的威胁,并且全球十大汽车制造商中有7家使用CCS。作者们用PLC网络实现了一个无线窃听工具,在附近的停车场截获了流量,并发现了大量的隐私和安全问题。
Please Pay Inside: Evaluating Bluetooth-based Detection of Gas Pump Skimmers
这篇文章讲的是美国常用的一个卡付款方式名叫 Gas Pump Skimmers,可能会被不法分子装上恶意的设备(撇油器)。检查是否被安装恶意设备的方式一般都是工作人员手动打开气泵,作者们发现撇油器中一般会有蓝牙连接,是用于收集车辆的支付信息的,所以也可以通过蓝牙来检测是否存在撇油器。
RVFUZZER: Finding Input Validation Bugs in Robotic Vehicles Through Control-Guided Testing
Robot Vehicles(RVs)是一种用于自动运输的系统,例如用于送货的商用无人机。所以也出现了多种多样的RVs的攻击,这篇文章针对于一种新型的漏洞,叫输入验证错误,为了防止此类攻击,作者提出了一个审查系统名为RVFUZZER。
Wireless Attacks on Aircraft Instrument Landing Systems
飞机着陆系统依赖于低成本软件无线电(SDR),但是还没有公开的文献研究过SDR对抗无线攻击的弹性,所以这篇文章研究了飞机仪表着陆系统(ILS)在无线攻击下的脆弱性。研究结果表面利用SDR欺骗ILS无线电信号是可行的。
Protecting Users Everywhere
Clinical Computer Security for Victims of Intimate Partner Violence
Itimate Partner Violence(IPV)翻译成中文是亲密伴侣暴力,维基百科上的解释的意思大致理解为伴侣之间的家庭暴力。目前有些人利用计算机技术来恐吓或骚扰受害者,所以这篇文章是再IPV的背景下,为IPV的受害者提供专业的咨询和帮助。
Computer Security and Privacy in the Interactions Between Victim Service Providers and Human Trafficking Survivors
这篇文章研究的时人口贩卖的幸存者与受害者服务提供者(VSP)之间的联系,更多的是有关如何保护受害者,受害者和VSP之间如何沟通,技术扮演了什么样的角色。
Evaluating the Contextual Integrity of Privacy Regulation: Parents’ IoT Toy Privacy Norms Versus COPPA
这篇文章的语句读起来比较拗口,没太理解,大意是有关隐私监管的,文中在判断一个名为COPPA的监管法案是否符合隐私规范以及大家的期望。
Secure Multi-User Content Sharing for Augmented Reality Applications
AR增强现实是未来的一个趋势,但是有的AR应用可能会给用户带来困扰,比如在一个共享AR的应用程序中(两个用户可以看到同样的东西),那么一个人的操作就会影响到另一个人,比如放置一个可以遮挡视觉的巨型物体。所以作者们设计了一个AR内容共享控制模块,并为HoloLens设计了一个原型。
Understanding and Improving Security and Privacy in Multi-User Smart Homes: A Design Exploration and In-Home User Study
作者为智能家居设计师和研究员构建了一个智能家居应用程序,包含基于位置的访问控制,监控访问控制和活动通知等功能。
Machine Learning, Adversarial and Otherwise
CSI NN: Reverse Engineering of Neural Network Architectures Through Electromagnetic Side Channel
侧信道攻击可以对神经网络进行反向工程。
CT-GAN: Malicious Tampering of 3D Medical Imagery using Deep Learning
作者展示了一种攻击,使用深度学习,对医院中的CT扫描图像进行修改。
Misleading Authorship Attribution of Source Code using Adversarial Learning
最近几年出现了代码作者的身份识别技术,就是根据代码的风格来判断是谁写的,这篇文章研究的重点在于用对抗学习干扰这个身份识别技术,他们对代码进行了保持语义的转换,这样子代码就会被错误的认为是另一个人写的。
Seeing is Not Believing: Camouflage Attacks on Image Scaling Algorithms
图像缩放算法一般是只改变图像的尺寸,但保持图像的视觉特征,这篇文章讲了一种对图像缩放算法的攻击,使得缩放后的图像的视觉语义产生巨大的改变。
Terminal Brain Damage: Exposing the Graceless Degradation in Deep Neural Networks Under Hardware Fault Attacks
深度神经网络(DNNs)中的参数变化会引起分类性能的下降,并且大多数模型至少有一个参数,在其特定的位翻转后,精度损失超过90%。所以作者研究了硬件故障攻击Rowhammer对DNNs的影响,结果发现即使在不了解模型的情况下,也可以对模型造成高达99%的精度下降。
Mobile Security
50 Ways to Leak Your Data: An Exploration of Apps’ Circumvention of the Android Permissions System
安卓系统目前提供了应用权限的管理,用来限制第三方app对隐私和系统资源的访问,然而目前app可以绕过权限模型来访问数据和系统资源。主要途径是两个串通的应用程序可以通过隐蔽的通道共享隐私数据。作者向谷歌披露了这个bug,并受到了奖励。
Devils in the Guidance: Predicting Logic Vulnerabilities in Payment Syndication Services through Automated Documentation Analysis
对支付联合系统中的文档进行分析,发现其中的逻辑漏洞。
EnTrust: Regulating Sensor Access by Cooperating Programs via Delegation Graphs
现代的操作系统通过多个应用程序的交互完成用户的请求,但是不受信任的应用程序可能滥用权限,或者将请求转发给恶意程序。文章中实现了安卓系统的委托授权系统,可以跨程序跟踪用户的请求处理,以获得用户对权限的批准。
HideMyApp : Hiding the Presence of Sensitive Apps on Android
因为安卓系统的开放设计,应用程序可以很轻松的读取手机上安装的应用程序列表。在Google Play上2917个流行应用的调查发现,有57%的应用会查询安装应用的列表,这样子会导致用户隐私的泄露。于是作者设计了HideMyApp(HMA),一个可以隐藏敏感应用的解决方案。
PolicyLint: Investigating Internal Privacy Policy Contradictions on Google Play
隐私政策一般比较冗长和复杂,所以最近有一些研究开发了工具对隐私政策进行收集和总结。然后这些工具没有考虑到隐私政策中可能出现的自我矛盾,所以这篇文章提出了PolicyLint,是一个隐私政策分析工具,可以识别隐私策略中的矛盾。对Google Play中的11430个应用程序分析后,发现其中14.2%的政策可能存在误导性的矛盾。
simTPM: User-centric TPM for Mobile Devices
一个新词名叫Trusted Platforms Modules(TPM),翻译为可信平台模块。这篇文章提出了基于sim的TPM,名为simTPM。
TESSERACT: Eliminating Experimental Bias in Malware Classification across Space and Time
文章中使用一个开源评估框架TESSERACT,评估三个Android的恶意软件分类器。
The Betrayal At Cloud City: An Empirical Analysis Of Cloud-Based Mobile Backends
使用基于云计算的移动后端的app如果出现了漏洞,开发人员往往不知道从哪里找到漏洞。这篇文章介绍了一个名为SkyWalker的自动审查应用程序的程序,提取APK中后端的url,通过枚举来识别软件漏洞和责任方,并报告给软件开发人员。
Understanding iOS-based Crowdturfing Through Hidden UI Analysis
这是一个关于iOS的安全问题,出现一个新型的恶意众包客户端将内容隐藏在正常的UI背后,以绕过审查。目前对这种技术了解甚少,所以这篇文章报告了第一个带有隐藏的crowdturfing ui的iOS应用的测量研究。
Software Security
Back to the Whiteboard: a Principled Approach for the Assessment and Design of Memory Forensic Techniques
内存分析在计算机取证中扮演了一个很重要的角色,是一个很活跃的领域,但是目前这是由人类的专家制定规则来驱动的,作者认为应该由自动化的算法来驱动。
CONFIRM: Evaluating Compatibility and Relevance of Control-flow Integrity Protections for Modern Software
这篇文章也是关于控制流完整性(CFI),还是不太了解相关的内容。里面提到名为CONFIRM的评估方法和测试套件,用来评估CFI的兼容性,适用性和相关性。
DEEPVSA: Facilitating Value-set Analysis with Deep Learning for Postmortem Program Analysis
VSA是一个强大的二进制分析工具,可以验证软件属性,识别软件漏洞。但是这个工具存在一些不足,所以作者使用提出了一个名为DEEPVSA的神经网络辅助别名分析工具。
Detecting Missing-Check Bugs via Semantic- and Context-Aware Criticalness and Constraints Inferences
Missing-Check错误指的是错误的执行状态没有得到检查和验证,可能会导致很多严重的后果。所以作者提出了一个名为CRIX的系统,用于检查操作系统内核中的Missing-Check错误。利用这个系统,作者在Linux内核中发现了27
RAZOR: A Framework for Post-deployment Software Debloating
第二次碰到了debloating这个词,上一篇讲的是减少web应用程序中的多余的代码,这一篇针对的是普通的应用程序。他们提出了一个名为RAZOR的框架,能减少超过70%的代码,生成功能性程序而不引入安全性问题。
Privacy
Evaluating Differentially Private Machine Learning in Practice
这个系列是关于隐私的。这篇文章提出的是差异性隐私这个词,因为不理解这个词的意思,所以大致理解文章是想评价机器学习中模型可能泄漏的个人训练纪录。
No Right to Remain Silent: Isolating Malicious Mixes
目前很多软件提供了端到端加密的信息保护服务,但是只能隐藏消息内容,无法隐藏信息的元数据。但是在onion mixnet网络中,元数据也可以被隐藏,但是这样子网络就变得很复杂,容易遭到攻击,所以作者提出了Miranda,可以检测恶意的Mixes和消除攻击。、
On (The Lack Of) Location Privacy in Crowdsourcing Applications
这篇文章关于移动众包软件中用户位置隐私的问题。
Point Break: A Study of Bandwidth Denial-of-Service Attacks against Tor
Tor网络是一个保护隐私的在线交流工具(国内好像访问不了,所以之前从没听说过),这篇文章研究的是Dos攻击对Tor网络的威胁。
Utility-Optimized Local Differential Privacy Mechanisms for Distribution Estimation
这篇文章研究的是关于LDP(局部隐私差异),并提出了ULDP(效用优化的LDP)
Iot Security
All Things Considered: An Analysis of IoT Devices on Home Networks
这个系列的文章都是有关于物联网设备的。这篇文章是对各个地方家庭中的物联网设备进行了分析,并研究他们的安全状况。
Discovering and Understanding the Security Hazards in the Interactions between IoT Devices, Mobile Apps, and Clouds on Smart Home Platforms
作者深入分析了5个广泛使用的智能家居平台,研究了实体之间交互的细节,发现了一些漏洞和针对智能家居平台的攻击。
FIRM-AFL: High-Throughput Greybox Fuzzing of IoT Firmware via Augmented Process Emulation
这里提到了Fuzzing,翻译为模糊测试,是一种有效的漏洞发现测试技术。作者为IoT设备提出了一个模糊测试固件,名为FIRM—AFL。
Looking from the Mirror: Evaluating IoT Device Security through Mobile Companion Apps
作者提出了一个平台,通过分析物联网设备的移动应用程序,发现潜在的易受攻击的应用。最后一共发现了来自73个供应商的324个设备可能受到攻击。
Not Everything is Dark and Gloomy: Power Grid Protections Against IoT Demand Attacks
这个文章研究的是MadIoT攻击对电力传输系统的影响。
Crypto Means Cryptocurrencies
BITE: Bitcoin Lightweight Client Privacy using Trusted Execution
这个系列有关于加密货币。文章说到区块链支付的时候,需要用户下载并处理整个链,所以对移动设备来说是比较困难的,以往的做法是将计算和存储外包给完整的区块链节点,但这样做会导致用户隐私的泄漏。所以这篇文章提出了一种保护使用比特币支付的轻量级客户端的隐私的方法。
FASTKITTEN: Practical Smart Contracts on Bitcoin
智能合约(Smart Contracts)是一个在用户间实现加密货币自动支付的应用,然而比特币并不支持这个应用,所以作者提出了FASTKITTEN,可以在比特币上执行复杂的智能合约。
StrongChain: Transparent and Collaborative Proof-of-Work Consensus
作者为比特币增加了一个名为StrongChain的方案,引入了透明度的概念,鼓励参与者合作而不是竞争。
Tracing Transactions Across Cryptocurrency Ledgers
加密货币的特征是所有交易都是全球可见的,但是最近的研究表明可以追踪货币,甚至消除用户的匿名身份。文章主要是针对这个展开的讨论。
Cryptocurrency Scams
Inadvertently Making Cyber Criminals Rich:A Comprehensive Study of Cryptojacking Campaigns at Internet Scale
这篇文章讲的也是关于加密货币,目前有在浏览器中挖掘的加密货币,所以就会出现有的网站存在cryptojacking(挖矿劫持)的行为,对互联网上的4900万个域名进行随机抽样后,发现有0.011%的网站存在这种行为。
The Anatomy of a Cryptocurrency Pump-and-Dump Scheme
题目中Pump-and-Dump翻译成中文的意思是“哄抬股价,逢高卖出”,此文章研究的是比特币的Pump-and-Dump行为
The Art of The Scam:Demystifying Honeypots in Ethereum Smart Contracts
这篇文章也是提到了智能合约(Samrt Contracts),随着智能合约越来越受欢迎,所以成为了攻击者感兴趣的目标。目前存在一种包含陷阱的合约来吸引受害者落入陷阱,这个一般称成为蜜罐,作者对蜜罐进行了首次系统的分析,并构建了HONEYBADGER工具。
Intelligence and Vulnerabilities
ATTACK2VEC: Leveraging TemporalWord Embeddings to Understand the Evolution of Cyberattacks
ATTACK2VEC是一个监控网络攻击的工具,可以更好的理解网络攻击及其演变。
Reading the Tea leaves: A Comparative Analysis of Threat Intelligence
这里提到threat intelligence是目前计算机安全的一个热门词汇,即通过收集已知的威胁,来为未来的攻击做准备。但是根据这篇文章的研究结果,目前利用现有的威胁情报数据实现这个目标还是存在限制和挑战的。
Towards the Detection of Inconsistencies in Public Security Vulnerability Reports
这篇文章的作者有一部分也是来自UCAS的。文章中提出了一个自动化的系统VIEM来检测CVE数据库(一个公共漏洞数据库)和NVD(国家漏洞数据库)之间的不一致信息。研究表明不一致性非常普遍,并且随着时间的推移,不一致性也越来越多。
Understanding and Securing Device Vulnerabilities through Automated Bug Report Analysis
目前物联网的攻击依赖于已知的漏洞和通过报告发布的攻击代码。但是这种容易获得的漏洞报告也可以作为防御手段,所以作者提出了一个名为IoTSheild的框架,使用了NLP技术自动收集和分析关于物联网的安全报告的内容。
-
【Docker】批量删除docker镜像(不通过id删除原始镜像)
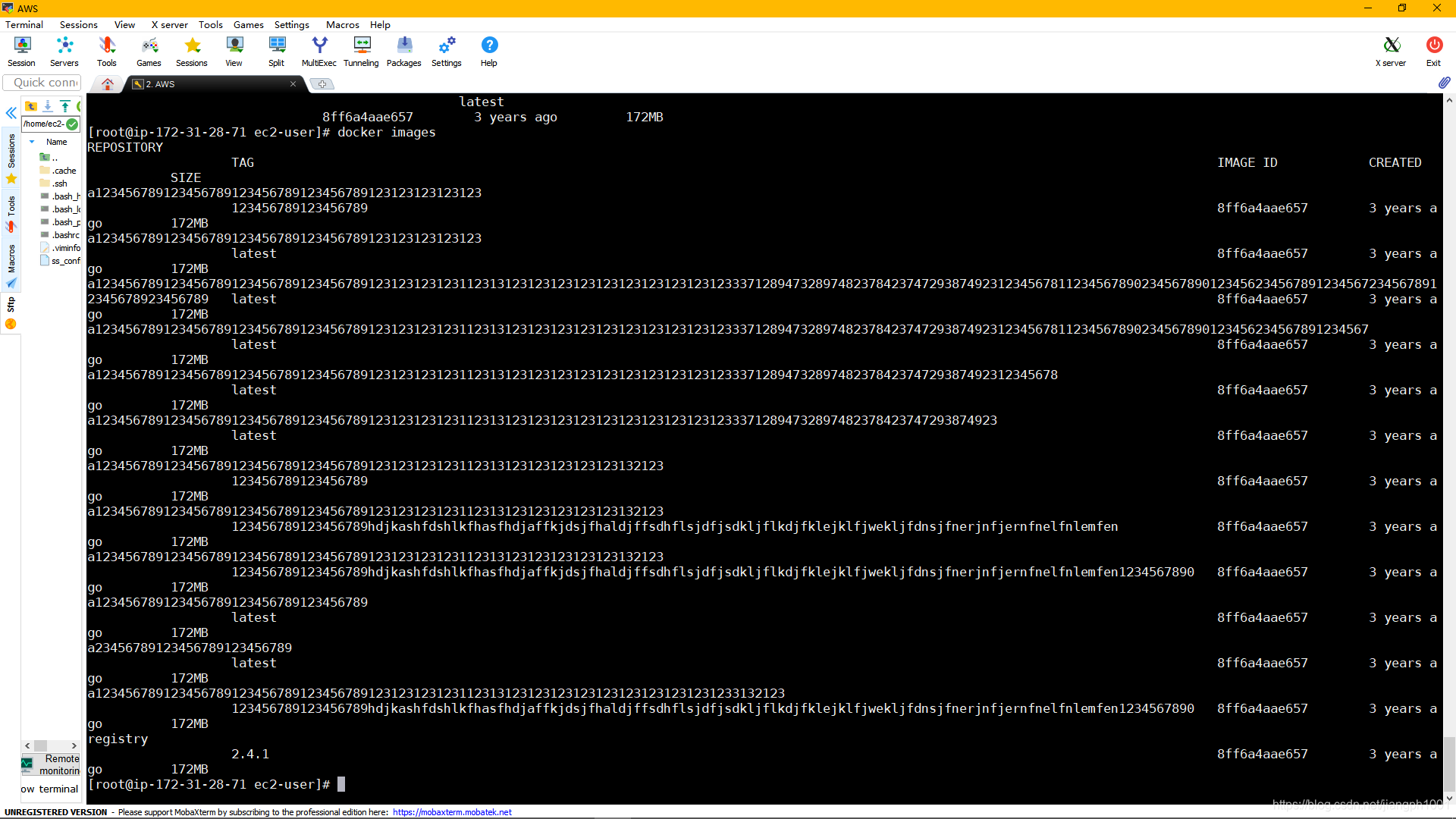 之前在公司的时候为了测试单个镜像的名字最长可以有多长,为了不破坏研发环境,在自己的亚马逊服务器上装了个docker,不停的打tag改名,结果现在已经忘了,大概是镜像名+tag不超过256个字符。
现在一用docker images命令查询本地的镜像,简直不忍直视。
看了一下,除了一个名为registry的镜像是有用的,其他的都是基于这个打的tag,实际上都是不占存储空间的
当时统一的名字都是以a123开头的,所以批量删除时,按照网上的教程用如下命令
之前在公司的时候为了测试单个镜像的名字最长可以有多长,为了不破坏研发环境,在自己的亚马逊服务器上装了个docker,不停的打tag改名,结果现在已经忘了,大概是镜像名+tag不超过256个字符。
现在一用docker images命令查询本地的镜像,简直不忍直视。
看了一下,除了一个名为registry的镜像是有用的,其他的都是基于这个打的tag,实际上都是不占存储空间的
当时统一的名字都是以a123开头的,所以批量删除时,按照网上的教程用如下命令docker rmi --force `docker images | grep a123 | awk '{print $3}'` 效果如下,把不带a123字符串的registry镜像也给删了
效果如下,把不带a123字符串的registry镜像也给删了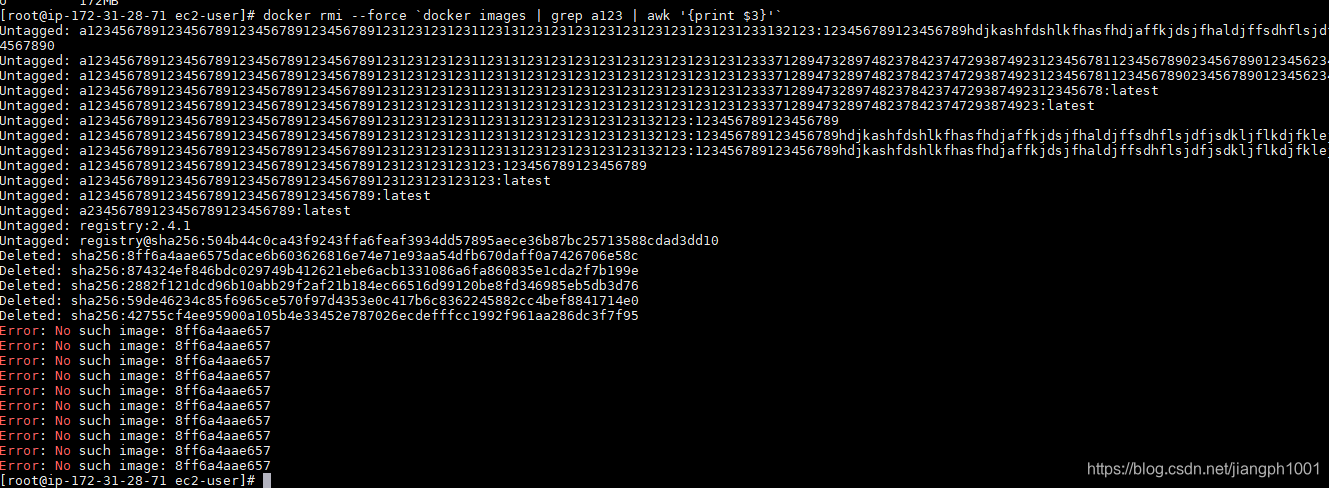 后来仔细读了一下这个命令的后半段
后来仔细读了一下这个命令的后半段docker images |grep a123|awk '{print $3}'问题出在awk ‘{print $3}’这个阶段,返回的是Image id,也就是说删除的时候并不是按照镜像的名字来删除的,而是按照id,我这里面所有的镜像id都是一样的,所以就连最原始的registry镜像,哪怕名字中不带a123也难逃厄运。 所以这里需要改成
docker images|grep a123| awk '{printf "%s:%s",$1,$2}'其中$1为镜像名,$2为tag
-
【Linux】搭建SSR服务器
迁移自我原来的博客,原文地址:https://blog.csdn.net/jiangph1001/article/details/81584006
1.首先从AWS上注册一个服务器
从控制台里找到自己实例,编辑安全组 把入站设为允许全部流量
2.安装pip和ss的服务端
yum install python-setuptools && easy_install pip pip install shadowsocks
3.创建配置文件
随便创建一个配置文件,按照如下格式写好
ss_config.json
{ "server":"0.0.0.0", "server_port":8388, "local_address": "127.0.0.1", "local_port":1080, "password":"mypassword", "timeout":300, "method":"aes-256-cfb", "fast_open": false }server_port一栏可以改成自定义端口,也可以默认使用8388 在password一栏把密码改成自己的密码
4.启动ss
ssserver -c ./ss_config.json -d start
