最新日志
-
【精读】On the Effectiveness of Risk Prediction Based on Users Browsing Behavior
类型 内容 标题 OTTer: A Scalable High-Resolution Encrypted Traffic Identification Engine 时间 2018 会议 RAID DOI 10.1007/978-3-030-00470-5_15 简介
恶意网站的比例在增加,但是恶意网站并没有影响到所有人,有些人可能一直没有遇到过恶意网站。
用户的浏览习惯与访问潜在有害页面之间存在相关性使用Symantec收集的数据,在92天的时间里,对160229位用户访问的页面(仅包括浏览器访问的URL)进行了分析。用户分成两类,一类是从未访问过恶意网站的,另一类是访问过的。总共提取了74个特征用于总结用户浏览行为。
用户活动量是风险水平的最佳指标之一。 一个人每天浏览的页面越多,种类越多样化,越有可能访问恶意网站。
在周末更容易遇到恶意页面 并且处于风险级别的人在夜间更活跃。 通过查看网站类别,我们发现其中某些类别(例如成人内容和缩短的URL)与存在风险的可能性呈正相关。 最后,我们执行的实验结果表明,仅通过分析浏览数据,就可以组合所有这些信息并训练分类器来预测用户是否有风险数据集
数据来自Symantec,这些数据来自于愿意参加共享使用情况统计和遇到的威胁信息的用户。
数据集包括2013年8月1日-2013年10月31日约160,000个用户的web请求。共有202,306,687次URL访问,涵盖了37,797,151个不同的URL。 研究范围是三个月内至少访问了100个页面的用户。数据标签
风险定义:从Norton SafeWeb和Google SafeBrowsing获取恶意URL数据集,并结合
,malc0de, 将URL分为三类:良性、恶意、域名在黑名单出现过的URL 风险分类
从未访问过的恶意域名的用户是安全用户,定义一个用户
at risk通过他在三个月内访问了至少2个不同的恶意URL或者三个列入黑名单的域。否则都是属于uncertain类别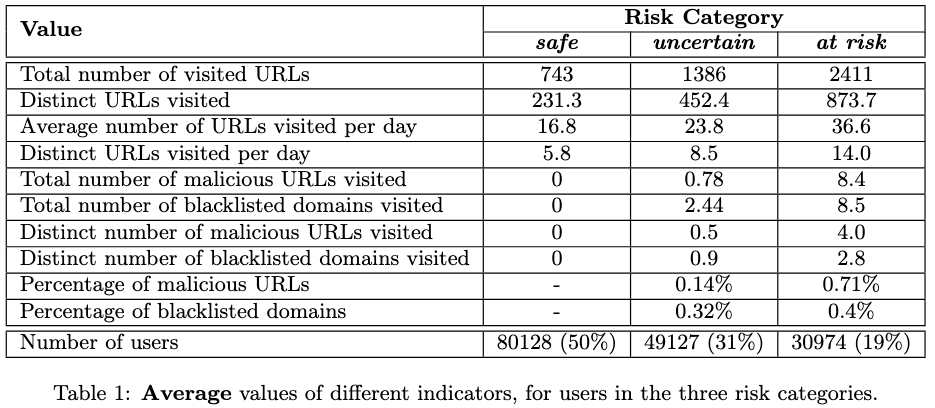
分析
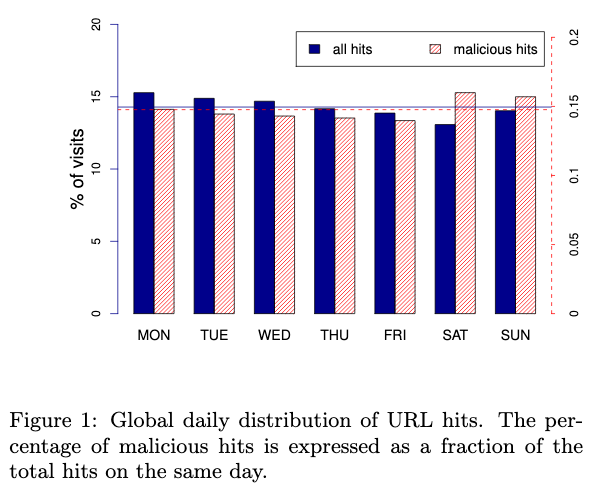 在周末,总的网页访问的次数减少,但是访问恶意网站的次数增加了。访问到恶意网站的概率增加了10%
在周末,总的网页访问的次数减少,但是访问恶意网站的次数增加了。访问到恶意网站的概率增加了10%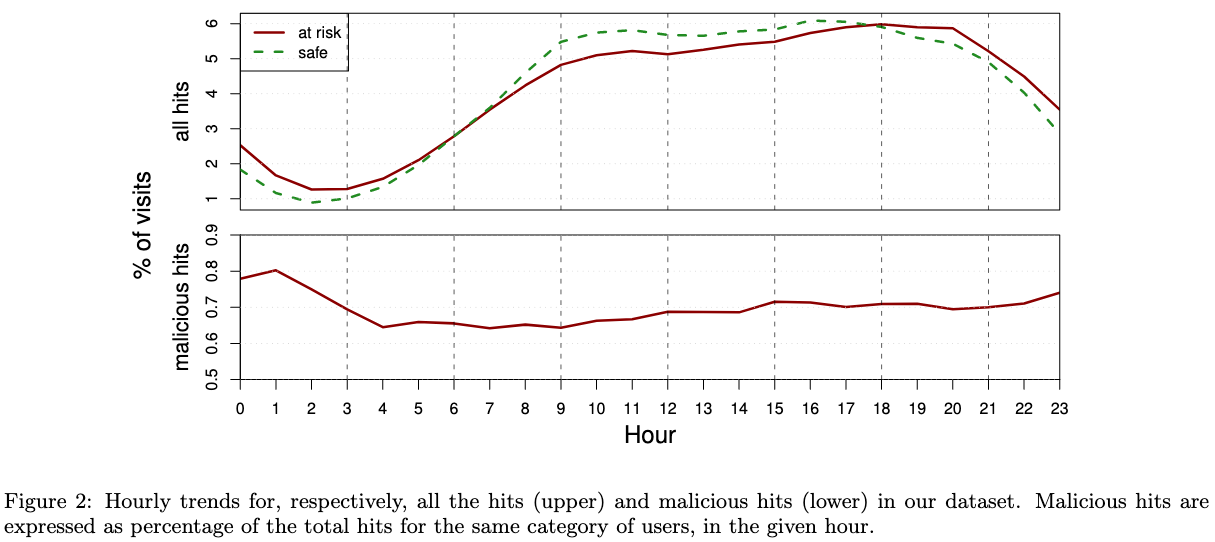 在夜间访问恶意网站的百分比有所增加。
在夜间访问恶意网站的百分比有所增加。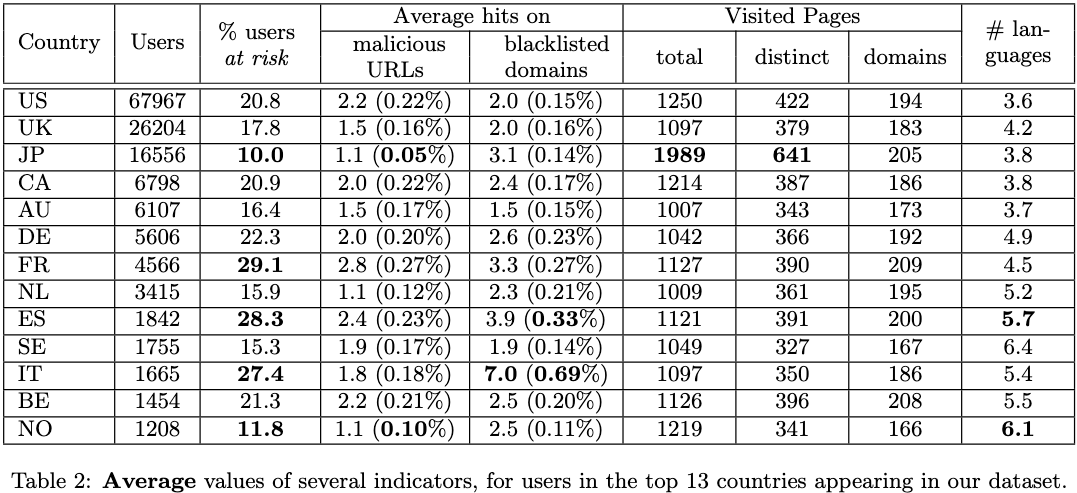 日本恶意网站访问概率最低,风险用户的比例最低。
日本恶意网站访问概率最低,风险用户的比例最低。特征提取
一个人花在浏览Web上的时间越长,遇到恶意网站的可能性就越大。
访问的不同URL数量,域名数量。网站类别:使用Symantec、Alexa、Open Directory Project提供的网站分类服务,对URL进行分类。 并使用一些第三方服务来补充,例如
http://longurl.org/services,http://www.tblop.com/,http://www.torrentresource.com,http://xboxpirate.eu/forums/topic/280-list-of-file-hosting-and-sharing-websites-137-entries/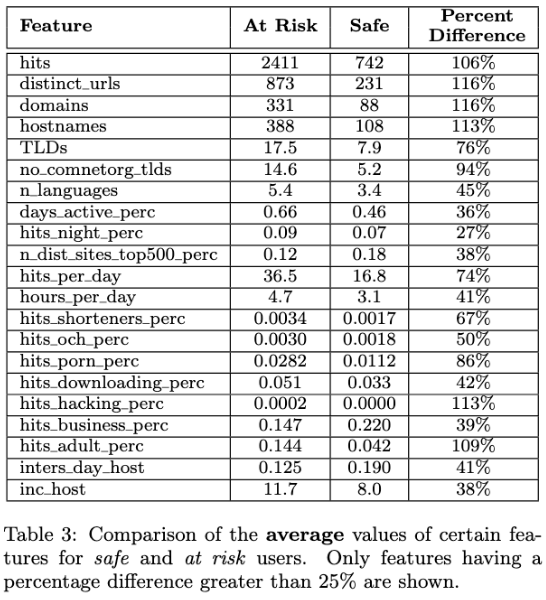
评价
-
【NLP】使用gemsim模块处理文本
https://radimrehurek.com/gensim/auto_examples/index.html
Text Summarization
from gensim.summarization import summarize text = "..." print(summarize(text)) print(summarize(text, ratio=0.5)) # 占原文的比例,默认是0.2 print(summarize(text, word_count=50)) # 限定摘要的单词数目获得关键词
from gensim.summarization import keywords print(keywords(text, ratio=0.01))FastText
from gensim.models.fasttext import FastText as FT_gensim from gensim.test.utils import datapath # Set file names for train and test data corpus_file = datapath('lee_background.cor') model = FT_gensim(size=100) # build the vocabulary model.build_vocab(corpus_file=corpus_file) # train the model model.train( corpus_file=corpus_file, epochs=model.epochs, total_examples=model.corpus_count, total_words=model.corpus_total_words ) print(model)
-
【Python】使用python读取pdf文件
代码来源:https://blog.csdn.net/leviopku/article/details/86443426
读取时使用try,可能存在pdf文件无法读取而报错的情况。
``` from io import StringIO from io import open from pdfminer.converter import TextConverter from pdfminer.layout import LAParams from pdfminer.pdfinterp import PDFResourceManager, process_pdf
def read_pdf(pdf_name): pdf = open(pdf_name,”rb”) # resource manager rsrcmgr = PDFResourceManager() retstr = StringIO() laparams = LAParams() # device device = TextConverter(rsrcmgr, retstr, laparams=laparams) process_pdf(rsrcmgr, device, pdf) device.close() content = retstr.getvalue() retstr.close() # 获取所有行 lines = str(content).split(“\n”) pdf.close() return lines
-
【Linux】vnc的使用
正常使用
启动:
vncserver :1 -geometry=1280x720查看已有的vnc
vncserver -list安装
Windows
序列号
77NVU-D9G5T-79ESS-V9Y6X-JMVGAUbuntu
apt-get install vnc4server解释
运行模式
- Server Mode: 仅能看
- User Mode: 可以控制(企业版)
- Virtual Mode :每次新建一个虚拟桌面来控制
-
【ML】使用sklearn库进行机器学习二分类任务
-
【整理】Hateful Speech论文
- Detect All Abuse!Toward Universal Abusive Language Detection Models
- Classification Methods for Hate Speech Diffusion: Detecting the Spread of HateSpeech on Twitter
Detect All Abuse!Toward Universal Abusive Language Detection Models
介绍
ALD - abusive language detection
许多ALD的研究,数据有主观性,不能通用。
构建四种不同类型的辱骂性语言方面嵌入:directed target, generalised target, explicit content, and implicit content。使用异质图来分析每个作者的语言行为,并利用图卷积网络(GCNs)学习单词和文档嵌入
贡献:
- 发现大多数ALD算法都无法在不同的在线社区中接受不同类型的辱骂性语言方面
- 提出了一种新的ALD算法,该算法能够将多个方面的辱骂语言进行显式整合,并能检测出不同方面和不同领域的通用性辱骂语言行为
数据集
Dataset Source Size Composition Waseem Twitter 16.2k Racism(11.97%), Sexism(19.43%), None(68.60%) HatEval Twitter 13k Hateful(42.08%), Non-hateful(57.92%) OffEval Twitter 13.2k Offensive(33.23%), Not-offensive(66.77%) Davids Twitter 24.8k Hate(5.77%), Offensive(77.43%), Neither(16.80%) Founta Twitter 99k Abusive(27.15%), Hateful(4.97%), Normal(53.85%), Spam(4.97%) FNUC Fox News Discussion Threads 1.5k Hateful(28.50%), Non-hateful(71.50%) StormW Stormfront(forum) 10.7k Hate(10.93%), NoHate(89.07%) MACAS ALD模型
Multi-Aspect Cross Attention Super Joint 模型
ALD模型
TIS
TF-IDF + SVM,使用三个特征:
- TF-IDF的权重
- 代词和辱骂词汇的TF-IDF权重
- 与相邻帖子的相似性
RBF核来处理非线性超平面分离问题。min_df设置为2
OTH
One-Two Steps Hybrid CNN
使用Chars2vec作为character嵌入,Glove作为word嵌入
MFR
Multi-Features with RNN
TWL
Two-step Word-level LSTM
LTC
Latent Topic Clustering with Bi-GRU
CBT
Character-based Transformer
引用
Classification Methods for Hate Speech Diffusion: Detecting the Spread of HateSpeech on Twitter
基于网络图中的扩散来检测Twitter中hate speech的传播