最新日志
-
【精读】通过用户的流量行为预测暴露在恶意网页的程度
类型 内容 标题 Predicting Impending Exposure to Malicious Content from User Behavior 时间 2018 会议 CCS 引用 Sharif M, Urakawa J, Christin N, et al. Predicting impending exposure to malicious content from user behavior[C]//Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security. 2018: 1487-1501. 感想
感觉这是一篇水文,但对这种研究方法还是值得学习的,拿到一个数据集,用各种方法分析并得出各种奇怪的结论。
摘要
许多计算机安全防御是被动的,它们只在安全事件发生时或之后运行。最近有努力试图在安全事件发生之前预测,以使防御者能够主动保护其设备和网络。这些努力主要集中在长期预测上。
我们提出了一个系统,它可以在单个浏览会话的级别上实现主动防御。通过观察用户行为,它可以提前几秒发现用户是否是会暴露在恶意内容中,从而为主动防御找到了机会。
我们使用一家大型蜂窝运营商的20645名用户在2017年生成的三个月的HTTP流量对我们的系统进行评估,结果表明它是非常有用的。
我们还通过调查直接与用户接触,询问他们与人口统计和安全相关的问题,以评估自我报告数据在预测恶意内容暴露方面的效用。我们发现,自我报告的数据有助于长期预测暴露风险。然而,即使是长期的自我报告的数据也不如行为测量对准确预测暴露的重要性。介绍
一个用户用手机浏览了恶意网站,可能导致手机中毒,最后丢失个人信息和财产,这样即暴露在恶意内容中。
文章主题是通过分析用户的行为(例如大量浏览可疑的网页)判断在接下来的一段时间(例如30秒左右)是否会暴露在恶意的内容中。
系统利用 用户自己报告的安全行为和对过去行为的观察,用户浏览会话的上下文特征,来预测用户是否会暴露在恶意内容之下。
贡献:
- 利用大型移动服务提供商的超过20,600名用户的三个月历史数据,记录了移动用户在线遭受恶意攻击(例如恶意软件)的程度,表明至少有11%的用户在受到过攻击。
- 其次,我们以Google安全浏览为例说明了黑名单的局限性,我们发现恶意网页在被加入黑名单之前就经常被访问:大量访问发生在黑名单的前几天甚至更早(最多87天)。
- 第三,我们的测量还显示了暴露于恶意页面的用户与未暴露于恶意页面的用户在浏览模式(例如浏览会话的长度)上的明显差异。
- 第四,通过问卷调查这些用户,我们建立了逻辑回归以估计自我报告的数据可以在多大程度上提供风险暴露的有意义的指标。
第五,我们设计了一个长期的预测分类器,它可以根据过去的行为特征来确定用户在一个月内暴露于恶意网站的风险。
第六,也是最重要的一点是,我们结合从所有这些实验中获得的知识,设计出一种短期分类器,该分类器由易于实时计算的特征构建而成,可以在30秒左右的时间内准确预测出用户的暴露风险( 第7节)。相关工作
我们的研究发处于四个不同的工作领域的交汇处:进行测量研究以确定移动恶意软件在多大程度上构成实际威胁;对保护终端用户(不仅仅使用黑名单)的系统研究;安全事件的预测;人为因素及其对安全性的影响的研究。
移动恶意软件的流行. 研究人员从早期就研究了移动恶意软件的生态系统。 Zhou和Jiang发现,他们研究的1200个恶意软件样本中,有80%以上是对合法软件的重新打包版本,而超过90%将主机变成了bots。
对恶意软件感染流行率的估计相差很大。一项研究通过美国一家大型移动提供商收集的DNS流量估计了恶意软件的流行率,并断言每百万台设备中只有不到九台被感染。另一个团队收集有关在用户设备上运行进程的信息,得出截然不同的结论——他们估计每千台设备中约有三台受到感染。
每个估计都有其自身的局限性:在前一项工作中,可能无法检测到使用硬编码IP地址的恶意软件(因为它不执行DNS查找),而在后一项工作中,总体样本可能有偏差。保护系统和网络 有很多黑名单机制和反病毒来帮助保护网络系统。 例如Gu提出了检测网络内僵尸程序的技术。 另一个例子是,Nazca通过检查网络上设备产生的总体流量来检测下载驱动攻击(drive-by-download attacks)。 早先的方案只能在暴露后进行干预,而本论文是提前预测可能导致感染和数据泄露的事件。
预测安全事件 Soska和Christin表明,使用公开可用的指标,他们可以预测网站是否会在一年内遭到入侵。 Hao可以预测恶意域名的注册。 Liu等证明了人们可以使用外部观察到的指标(例如DNS错误配置)来预测企业将来是否会遭受安全事故(例如服务器违规)。 Sabottke重点集中在使用从Twitter提要中收集的信息来预测哪些漏洞将被利用,而Kang等人提出方法来预测一个国家内有多少百分比的主机可能被特定恶意软件感染。
影响安全的人为因素 计算机安全中的人为因素已得到广泛研究。Christin等人发现运行防病毒软件的用户更有可能将其设备置于危险之中。 我们的结果重现了这一发现。
一些研究人员试图通过安装在其机器上的软件监视用户的行为,从而提高用户研究的生态有效性。 令人惊讶的是,他们发现专家的行为不一定比非专家更安全。 某些类型的网站(例如流媒体和色情网站)比其他网站具有更高的感染风险,并且访问那些被列入黑名单的网站和这些类网站的行为高度相关。
Egelman和Peer制定了“安全行为意图量表”(SeBIS),以此作为评估安全行为的简单手段。 他们发现,SeBIS的不同子量表与某些计算机安全行为密切相关(例如,在所谓的“主动意识”子量表上得分较高的用户不太可能受到网络钓鱼攻击)。 其他人则质疑像SeBIS这样的量表是否真正预测了该领域的实际行为。 我们使用修订的SeBIS(RSeBIS)的主动意识子量表来探讨这个问题,该量表对语言翻译更健壮。数据收集
KDDI,日本一家大型移动互联网服务提供商提供用户数据
加入这个数据收集的用户,会允许服务提供商记录HTTP访问。 2017年6月,20895名不同的用户。HTTP流量收集
2017年4月1日至2017年6月30日期间收集的日志,20645个手机用户出现在日志中。
每个日志条目都包含HTTP请求的时间戳、访问的URL、HTTP Referer字段的内容、上载和下载的字节数、用户代理字符串以及与客户对应的(唯一的)用户ID。
限制 数据集不包括HTTP内容(例如,通过HTTP POST发送的数据)或HTTPS请求,只包括内容类型为text/html的HTTP请求。换言之,我们无法看到图像、脚本或多媒体内容访问;同样地,由于收集只会覆盖蜂窝网络,因此我们无法访问任何Wi-Fi流量。
先前的研究发现,网络上大多数恶意流量都是基于HTTP的12While the democra-tization of HTTPS using services such as Let’s Encrypt [2] might increase the popularity of serving malicious content over HTTPS, ourproposedmethodscanbeadaptedbyusingdomaininformationonly, instead of the entire URL. Further, corporate networks can perform HTTPS collection using “man-in-the-middle” proxies [19].
数据存在的问题:同意被收集数据的用户,可能更不在意隐私。但是隐私行为和安全行为是独立的3。
HTTP日志处理
同一个用户发出的连续http请求作为一个会话 ,当user-agent更改或者超过20分钟没有请求时,认为会话终止。 数据集中的一小部分HTTP请求(<2.2%)来自传统操作系统(如Windows、Mac OS等)
根据谷歌安全浏览v3(GSB)数据库,将HTTP请求标记为恶意或非恶意。 GSB每天更新,所以下载了每天的快照进行查询。将HTTP请求的URL分为几类,如新闻,体育等。
使用DigitalArts开发的分类算法,i-Filter过滤系统。 使用DigitalArts手工标注的域名,训练了一个卷积神经网络将域名分为99个主题
暴露的用户至少访问过一次恶意页面,未暴露的用户没有访问过恶意页面在线调查
要求参与的用户参加一个在线调查。
收到23419个用户响应,3.9%的回复率。有效回答有20895个。
受众特征 男性用户占61.5%,女性用户占38.5%。 (被征集用户的人数为男性55.6%,女性42.8%,未知1.6%。)受访者的平均年龄为43岁,标准差为11.8岁。受访者不包括18岁以下的未成年人。
问题:
- 是否遇到过安全事件(密码被盗)。遭遇过安全事件可能会影响用户的行为
- 用户设备上是否安装了防病毒软件。该类用户可能更容易存在风险行为
- 使用的应用市场类型。非官方应用市场有大量的恶意APP,此类用户更容易暴露
- 浏览器弹出警告时,用户的行为。忽略警告的用户更容易暴露
- 参与者对RSeBIS的主动意识量表的反应。积极主动意识得分高的参与者比其他人更不容易受到网络钓鱼的影响。得分高的参与者访问恶意网站的风险也较低。
- 参与者对计算机安全知识的自信。期望自信的参与者表现出更安全的行为。
暴露在恶意环境下
分析有三个目标 (1)确定移动用户在多大程度上暴露于恶意内容。 (2)证明在页面被列入黑名单之前,不法分子有入侵设备的机会。 (3)探索暴露和未暴露用户在多个维度上的行为差异。
用户暴露的总体比率
20,645个用户中,2172(11%)个用户至少访问了一次恶意页面。这些用户中的大多数(1,995)暴露于GSB分类为“网络钓鱼”的页面,153个用户暴露于“恶意软件”页面,而24个用户暴露于“恶意软件”和“网络钓鱼”页面。 总体而言,暴露的用户访问了201个域中的3,491个恶意页面。
至少有0.81%的用户暴露于已确认的恶意软件。但是,我们无法估计实际感染的比例,这些用户可能已被防病毒或其他内容过滤器保护。 11%的用户会暴露于可疑内容
暴露的窗口
观察那些在被加入到GSB数据库之前的URL访问日志。负x轴代表被加入之前,正x轴代表被加入之后。
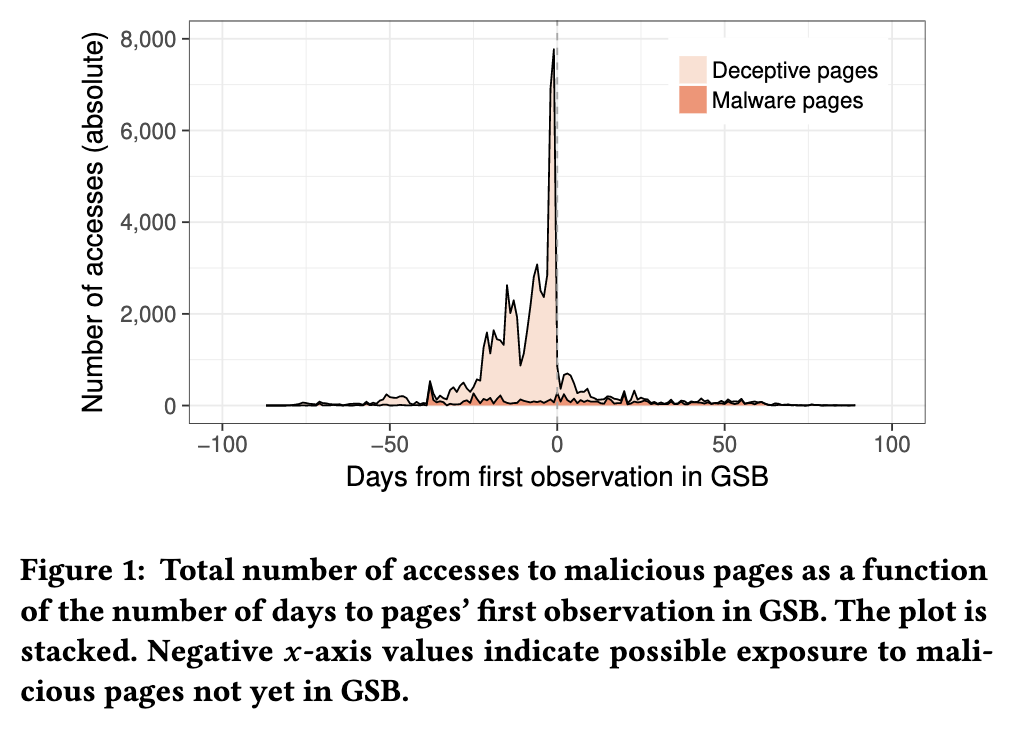 某些页面被GSB标记为恶意页面,可能存在几天或几周的延迟
某些页面被GSB标记为恶意页面,可能存在几天或几周的延迟用户间行为的差异
知道GSB何时将页面标记为恶意,但不清楚页面何时真正变成恶意网页。
定义1 τ-恶意页面:考虑用户在时间t向URL u发出HTTP请求。如果URL u在任何时间t′出现在GSB数据库中,使得t≤t′< t+τ,则将其视为τ-恶意。
τ-恶意页面是当前被标记为良性的网页,但将被标记为恶意的网页。τ越小,危险就越大,已经是恶意页面的概率随着τ→0而增加。
τ=22天 该页面的访问次数开始显著增加 τ=2天 访问峰值最高
暴露事件 图2显示针对恶意页面的各种定义的每个暴露用户的请求访问性页面的数量,范围从τ=0到可能的最大值(91天)。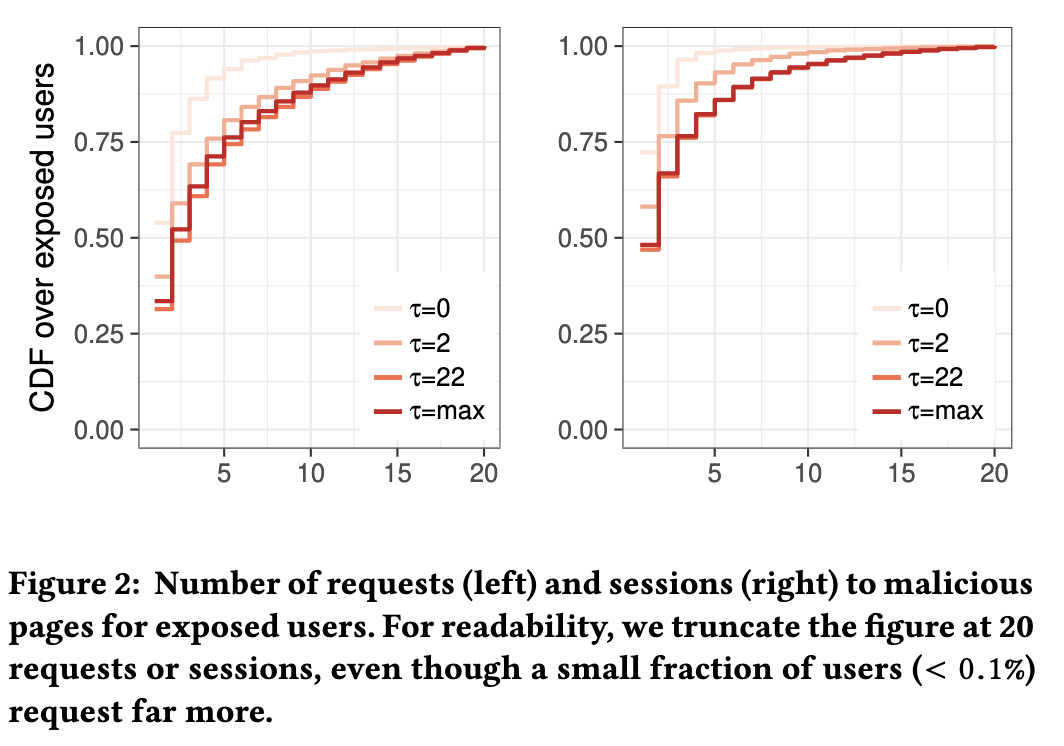
1/3 - 1/2的用户只访问了一个恶意页面,超过1/4的用户对恶意页面发出了超过3个请求。
结论2 预测分类器不能完全依赖于先前的暴露,因为我们的用户语料库中有相当一部分显示缺乏“重复”暴露
接下来,我们在图3中计算至少访问过x次恶意页面的暴露用户将来将访问恶意页面的概率。 图3报告了Pr[A(x+1)|A(x)]的经验估计,其中A(x)表示用户访问了至少x个恶意页面的事件。 我们发现:
结论3 用户暴露的次数越多,再次暴露的概率就越高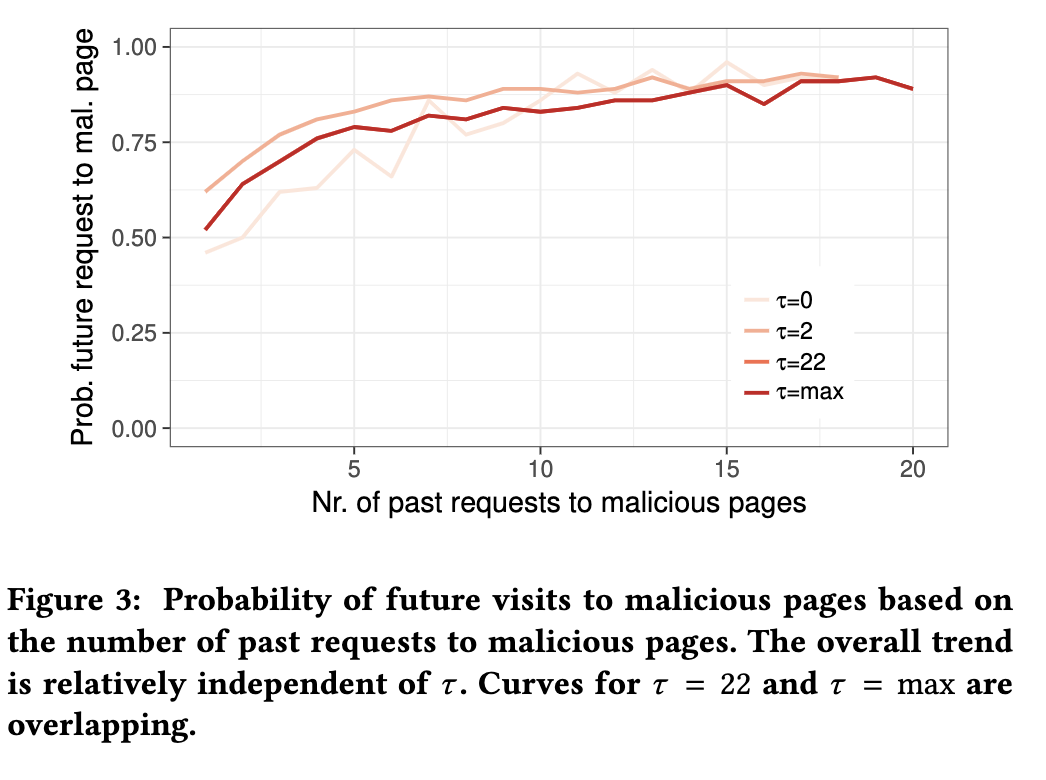
会话级度量 接下来我们将研究暴露用户和未暴露用户之间活动水平的差异。图4(a)未暴露的用户通常比暴露的用户每天请求的页面要少得多。图4(b)显示了会话长度的明显差异:未暴露的用户参与的会话通常比暴露的用户短。
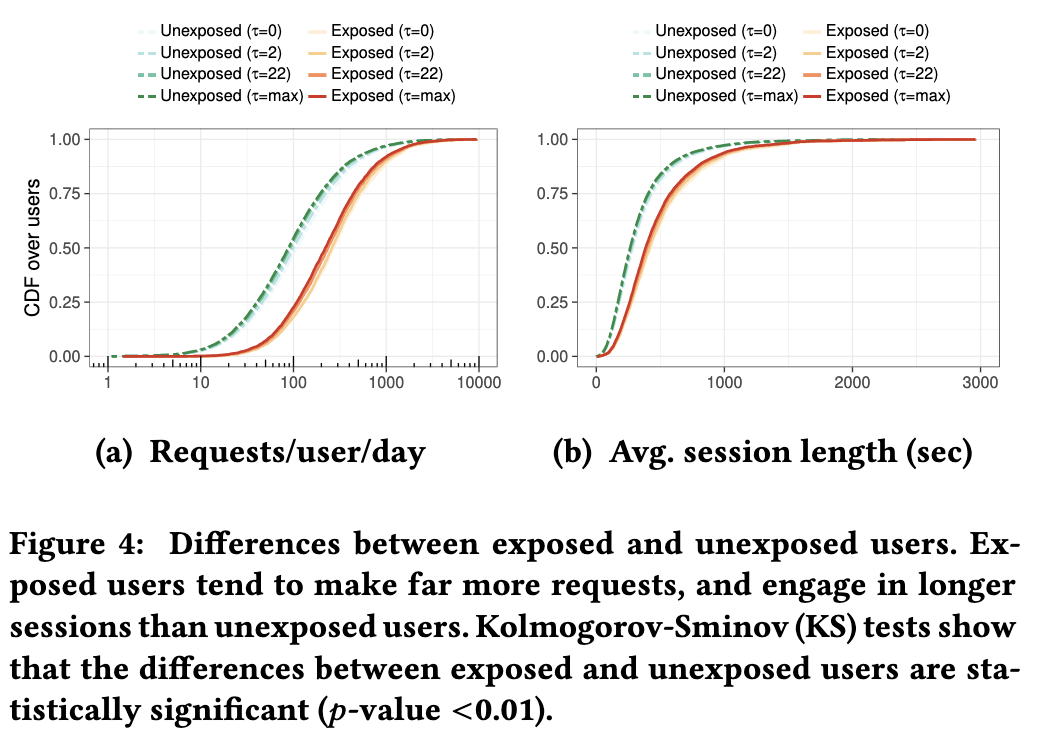
结论4 暴露的用户比未暴露的用户更活跃-他们发会出更多的HTTP请求,并参与更多更长的浏览会话每日和每周影响 接下来,我们按小时查看每天暴露和未暴露的用户的请求量,如图5所示。为了有意义地比较不同的类,我们将每个值归一化为[0,1]范围,其中0代表每天来自给定类型的用户的最小请求数,而1是最大请求数。
人们在午餐时间浏览互联网最多,清晨(午夜至凌晨4点)是一天中最安静的时间。然而,似乎暴露的用户倾向于在一天中更均匀地请求数据;特别是,与未暴露的用户的差距在晚上最为明显。暴露的用户比未暴露的用户更经常地浏览互联网,晚上比工作时浏览风险更大的网站。
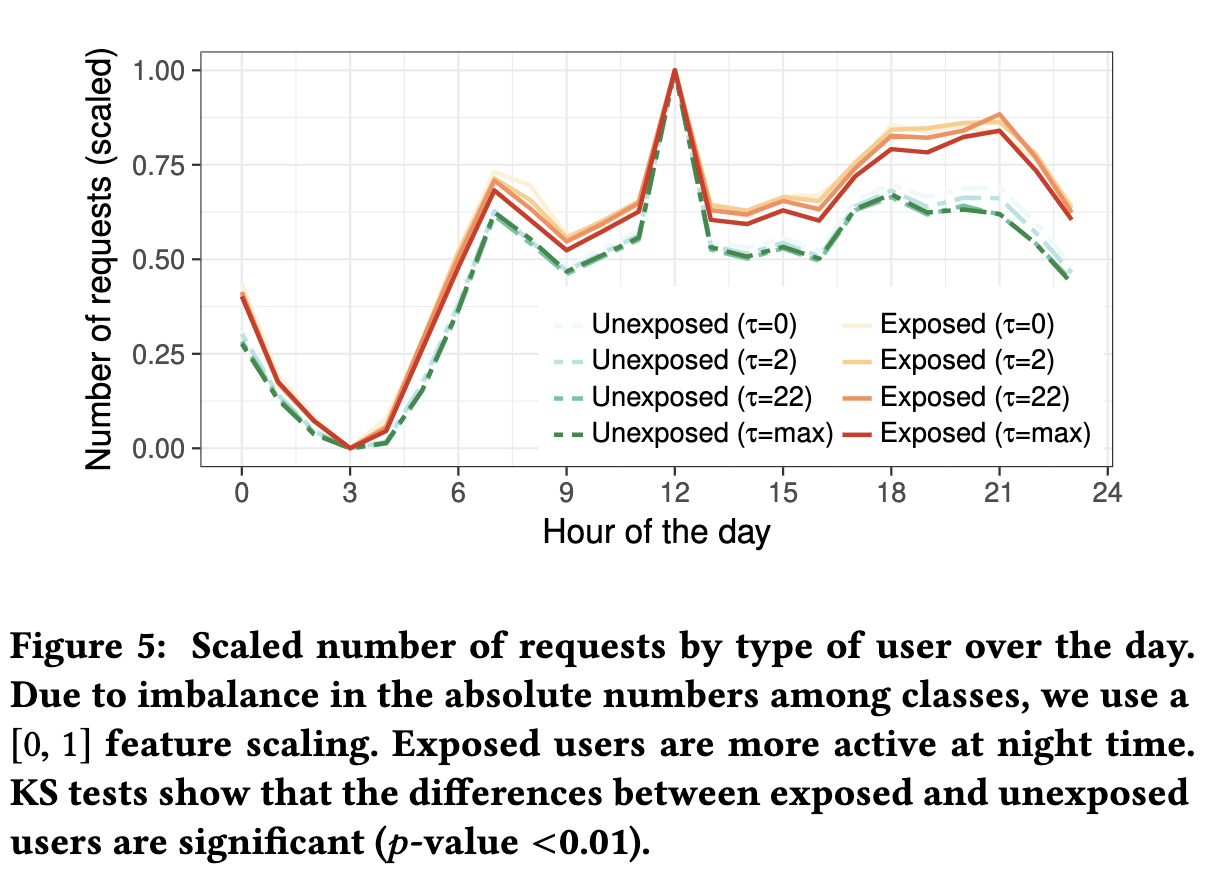
结论5 暴露的用户倾向于在晚上和工作时间之外更频繁地浏览互联网
暴露的用户在周末往往比未暴露的用户更活跃图6展示了未暴露和暴露用户的广告和成人网页的比例。尽管我们可能会忽略一些对广告页面的请求(JavaScript)。暴露的用户相比未暴露的用户以更高的频率访问广告页面、成人内容。
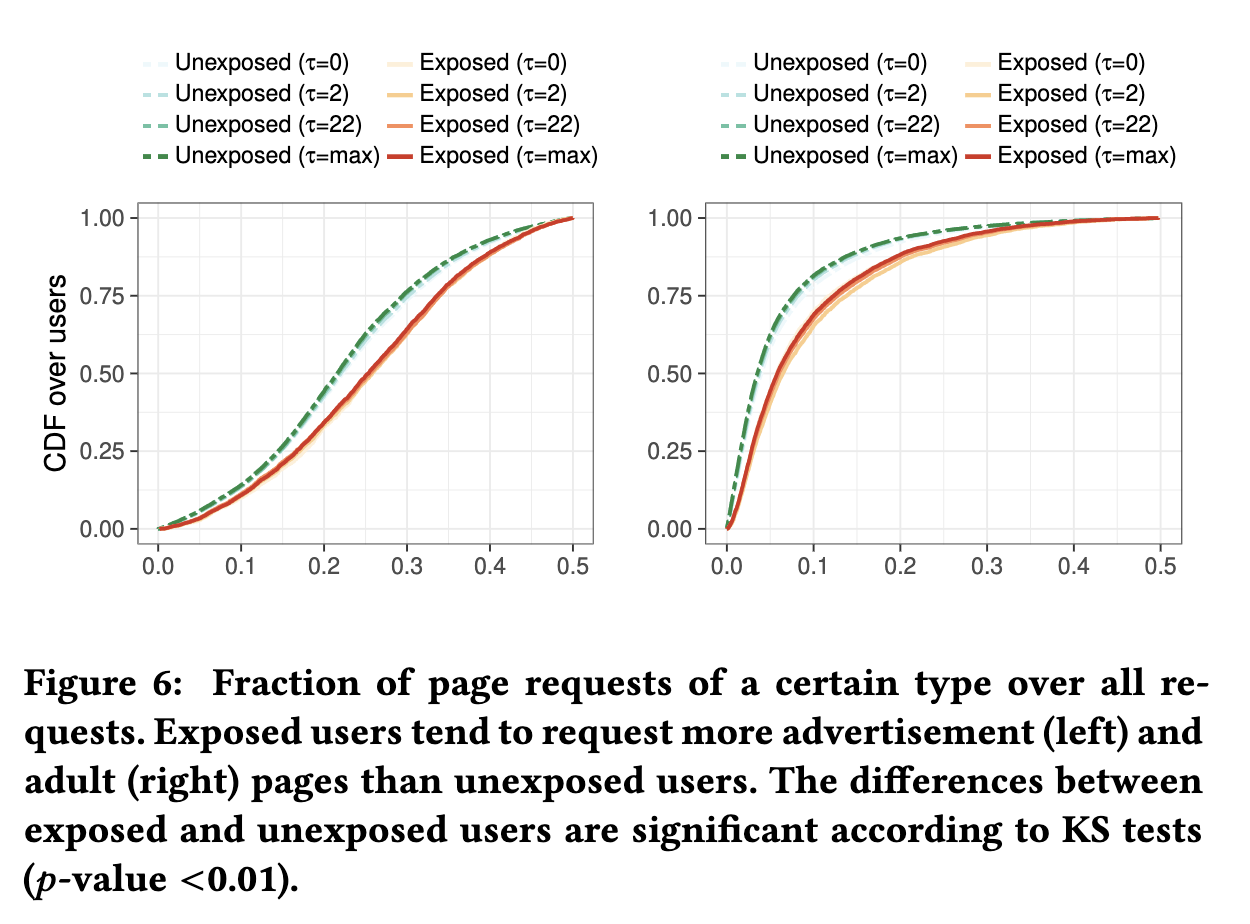
暴露的用户更可能访问19个类别的网页(如成人、广告和视频搜索网页),而未暴露的用户更可能访问46个类别的网页(如教育、金融和新闻网页)结论6.某些类别的内容可能有较高的暴露风险
测量结果表明,τ=2似乎是一个合理的折衷方案:较大的τ可能包含在浏览时并没有恶意的页面,但较小的τ可能会丢失危险页面。
调查响应和暴露风险
实验设计
logistics回归, τ=2 自变量是根据调查响应构建的。 具体来说,我们计算以下变量:
- 性别
- 用户设备上是否存在防病毒软件
- 用户是否从非官方市场下载应用程序
- 用户是否忽视浏览器警告
- 用户是否遭受过损害
- RSeBIS主动意识得分(标准化为[0,1]范围
使用Python的statsmodels包来构建回归模型
实验结果
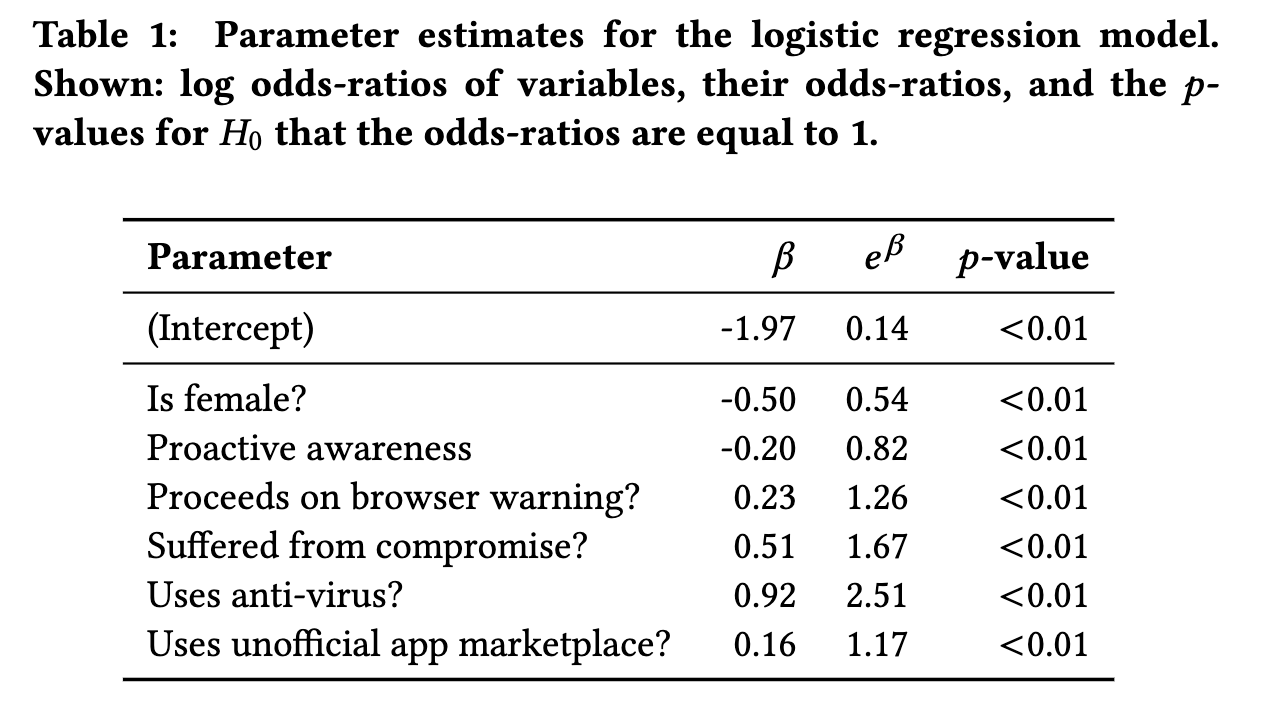 表1中报告了最佳拟合模型的参数估计值。在交互作用幸存的模型选择中,发现模型中的所有主要因素均在显着性水平p <0.01上对暴露有显着影响。女性访问恶意网址的可能性是男性的0.54倍。这一发现表明,女性在第一时间遇到此类网页的可能性较小。遭受过损害的参与者接触恶意内容的几率增加了1.67倍。参数估计显示,一些风险行为例如忽略浏览器警告,以及使用非官方市场下载的APP,平均将暴露于恶意内容的几率增加至少1.17倍。
表1中报告了最佳拟合模型的参数估计值。在交互作用幸存的模型选择中,发现模型中的所有主要因素均在显着性水平p <0.01上对暴露有显着影响。女性访问恶意网址的可能性是男性的0.54倍。这一发现表明,女性在第一时间遇到此类网页的可能性较小。遭受过损害的参与者接触恶意内容的几率增加了1.67倍。参数估计显示,一些风险行为例如忽略浏览器警告,以及使用非官方市场下载的APP,平均将暴露于恶意内容的几率增加至少1.17倍。
拥有反病毒软件的用户,访问恶意网站的几率是其他人的2.51倍。这些用户有一种错误的安全感,导致他们从事高风险的行为。最后,在RSeBIS上获得高警惕意识得分的用户访问恶意url的可能性是得分最低的用户的0.82倍,这支持了先前的证据,即该等级与某些安全行为相关长期暴露预测
分类器设计
自我报告的特征
提取了七个特征进行预测。其中六个特性与第2.1.2节中描述的相同
第七个表示用户对其安全知识的自信(通过将对Likert量表问题的回答相加,然后标准化到[0,1]范围来计算)过去行为的特征
共132个特征
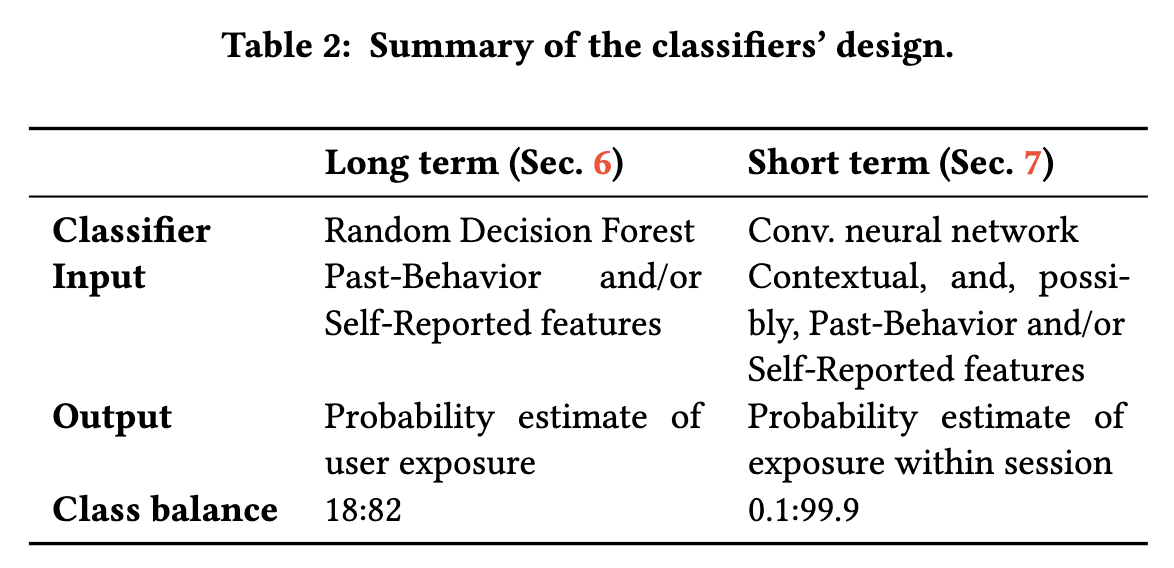
会话和HTTP请求的平均数量,上载和下载的平均字节数以及以秒为单位的平均会话长度和请求数。 一个特征指示以前的会话发生暴露的比例,另一个特征量化以前的暴露次数 24个特征总结了每个小时的活动水平,99个特征描述了先前的HTTP请求如何在DigitalArts的99个主题之间分配。 最后一个特征是报告了对不在Alexa排名前100,000个网站中的域的请求所占的比例。预测算法 我们使用随机决策森林来执行预测。 为了获得最佳性能,分类树的数量设置为50,最大树的高度设置为5,然后将否定示例的权重设置为肯定树的权重的0.1倍。 表2总结了分类器的设计。
实验设计
基于用户自我报告数据和/或浏览行为,我们可以预测下个月的曝光率吗?为了回答这个问题,我们使用我们的数据训练随机决策森林,利用4月份的观测数据预测5月份的暴露(τ=2),并通过5月份的观测评估这些模型预测6月份暴露的能力。进行了十次交叉验证,其中90%的用户用于训练,10%的用户用于测试。
实验结果
图7显示了两个参数的函数的整体分类器性能。 使用我们完整的功能集(自我报告和过去的行为),图7(a)显示了会话阈值s的影响。 s表示用户必须忍受才能被视为公开的不同公开会话的数量。 当s=1时,用户可能是偶然地登陆了暴露的网页; s=5时,用户重复的暴露。
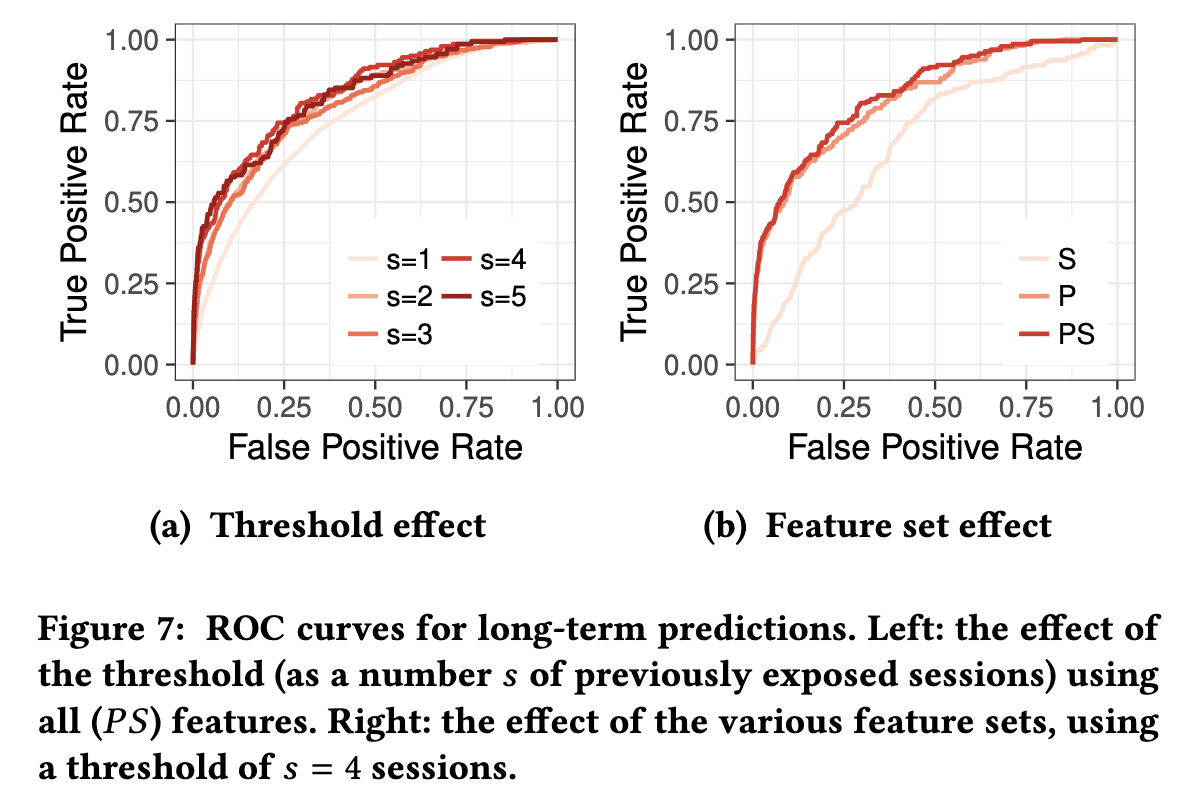
对于长期预测来说,s越高似乎效果越好。图7(b)示出了两个特征集的影响:S表示自报告特征的影响,P表示过去行为特征的影响,PS表示考虑两个特征集的影响。正如预期的那样,整个集合(PS)取得了最好的结果,但更有趣的是,自报告特性本身的影响非常小。虽然孤立地说,自报告特性可能有用(例如,如果用户监视不是一个选项),但是过去的行为特性可以自己获得更好的性能;并且将它们与自报告特性相结合不会产生很大的改进。
会话内暴露预测
接下来,我们探讨预测单个浏览会话期间用户是否会从事危险行为(即访问恶意网站)的可行性。 因此,我们旨在使用在某个阶段描述会话的上下文特征,以预测用户是否会在会话的后续阶段暴露。 每次用户发出HTTP请求时,上下文功能都会更新以描述会话的新状态,并做出另一个预测。 作为如图6和先前的工作所示,用户的行为特征(例如,访问的网站数量)可以帮助预测长期(例如三个月)的用户暴露风险。 接下来,我们将展示如何使用类似的行为特征来在更短的时间尺度上预测暴露。
分类器设计
上下文特征
共135个
由于暴露的会话往往具有较高的活动量,因此量化活动量的功能可以很好地替代我们的预测。 其中包括会话长度(以秒为单位),HTTP请求数以及会话期间传输的字节数。恶意域不太可能(直接)从顶级域链接到。 因此,我们将对非顶级域名(即Alexa顶级域名100,000之外)的HTTP请求所占比例作为另一项功能。 暴露的会话更可能发生在周末和一天的晚些时候(发现5)。因此,我们使用一个特征来指示会话是否在周末进行,使用24个特征来指示会话处于活动状态的时间。 六个二进制特征指示会话中使用的操作系统和浏览功能(从HTTP标头中的用户代理字符串中获悉):两个特征指示Android和iOS,两个特征指示使用Chrome和Safari,并且使用两个特征来指示其他操作系统和浏览器(例如Firefox OS)。 虽然我们的探索性数据分析和先前的工作[49]并未表明不同系统(例如iOS与Android)的风险状况存在明显差异,但这些特征可以帮助捕获系统之间的细微差异(例如浏览器黑名单的更新频率),这可能会影响用户的暴露率。 最后,有99个特征描述了会话中访问的域的主题。 如之前的工作所示,某些网站类别例如在线流媒体倾向于表现出比其他类别更多的恶意活动。 因此访问此类网站可能会增加暴露的可能性。 预测算法 使用卷积深神经网络(DNNs)进行预测
目标是在暴露发生之前预测对恶意内容的暴露,因此忽略了在访问恶意URL时或之后进行的会话中的HTTP请求。
我们为训练集中的每个HTTP请求创建一个特征向量。为暴露会话的HTTP请求分配一个正向标签(即1),为其余请求分配一个负向标签(即0)。 在训练过程中,我们不会使用在暴露时间前超过一分钟的会话中使用HTTP请求。我们仅对具有9个以上请求的会话执行预测。(这些会话占所有公开课程的约96%)。 使用Selenium和tPacketCapture,在Android手机上抓取了Alexa前100个仅HTTP的网站,发现平均美两个网站访问量对应于十个HTTP请求。 因此,我们提出的系统将在用户访问两个网站后开始分析用户的浏览活动。
我们使用的DNN是顺序的,并且由三个卷积层组成,每个卷积层后接一个校正线性激活层、一个全连接层和一个softmax层。 卷积使用5×128核,步长为1。 在训练中,DNN的交叉熵损失设为最小。 这是体系结构和培训策略的标准选择。 在选择卷积架构之前,我们最初测试了仅由全连接层组成的神经网络架构,发现其执行的准确性较低。
我们使用从训练数据中获得的统计数据将DNNs的输入规范化为[0,1]范围,因为规范化有助于加快训练速度和提高性能。我们将学习率设置为5×10^-5,batch size设置为128,epochs设置为50。我们通过网格搜索来设置超参数,优化DNNs的深度和卷积核的大小。我们在Keras中实现DNNs(使用TensorFlow后端[1])。表2总结了预测器的设计。
实验设计
我们选择了5个20天的不同时段(其中前15天用于训练,后5天用于测试)来评估。
-
Luca Invernizzi, Stanislav Miskovic, Ruben Torres, Christopher Kruegel, Sabyasachi Saha, Giovanni Vigna, Sung-Ju Lee, and Marco Mellia. 2014. Nazca: Detecting Malware Distribution in Large-Scale Networks. In Proc. NDSS. ↩
-
YajinZhouandXuxianJiang.2012.Dissecting android malware:Characterization and evolution. InProc. IEEE S&P. ↩
-
Serge Egelman and Eyal Peer. 2015. Predicting privacy and security attitudes. ACM SIGCAS Computers and Society 45, 1 (2015), 22–28. ↩
-
【NLP】使用vader-sentiment进行文本的情感分析
简介
VADER(Valence-Aware Dictionary and mootion Reasoner)是一个词汇和基于规则的情感分析工具。
论文
名称:VADER: A Parsimonious Rule-Based Model for Sentiment Analysis of Social Media Text
论文地址:https://www.aaai.org/ocs/index.php/ICWSM/ICWSM14/paper/viewPaper/8109
发表于AAAI 2014安装
地址:https://pypi.org/project/vaderSentiment/
Github源码:https://github.com/cjhutto/vaderSentiment
安装方法:pip install vaderSentiment使用
使用方法
from vaderSentiment.vaderSentiment import SentimentIntensityAnalyzer sentences = ["This is awful","I like it"] analyzer = SentimentIntensityAnalyzer() for sentence in sentences: vs = analyzer.polarity_scores(sentence) print("{:-<65} {}".format(sentence, str(vs)))输出
This is awful---------------- {'neg': 0.6, 'neu': 0.4, 'pos': 0.0, 'compound': -0.4588} I like it-------------------- {'neg': 0.0, 'neu': 0.286, 'pos': 0.714, 'compound': 0.3612}存储形式是字典,通过字典调用各个变量
解释
- neg 负面情绪
- neu 中立情绪
- pos 积极情绪
- compound 指的是将前三个指标相加,并调整为(-1,1)的一个值
-
【Python】conda环境命令
环境管理
- 查看当前的环境列表
$ conda info --envs or $ conda env list - 创建新的python环境,并指定版本
conda create --name myenv python=3.7 - 指定库的版本
$ conda create -n myenv scipy=0.15.0 - 复制环境
$ conda create --name myclone --clone myenv - 激活环境
$ source activate myenv - 退出环境
$ source deactivate - 删除环境
$ conda remove --name myenv --all - 环境导出
$ conda env export > environment.yml - 环境导入
$ conda env create -f environment.yml包管理
- 查看安装的依赖库
$ conda list - 安装某个包
$ conda install XXX - 更新包
$ conda update XXX - 删除包
$ conda remove XXX - 安装到指定环境
$ conda install -n myenv XXX
- 查看当前的环境列表
-
Sybil相关论文
- SoK: The Evolution of Sybil Defense via Social Networks
- Detecting spammers on twitter
- The Latent Community Model for Detecting Sybil Attacks in Social Networks
- Uncovering Large Groups of Active Malicious Accounts inOnline Social Networks
SoK: The Evolution of Sybil Defense via Social Networks
Alvisi L, Clement A, Epasto A, et al. Sok: The evolution of sybil defense via social networks[C]//2013 ieee symposium on security and privacy. IEEE, 2013: 38\96
本文综述了Sybil防御协议,利用社会图结构识别Sybil。(基于人人网进行研究)
Detecting spammers on twitter
Fabrıcio Benevenuto, Gabriel Magno, Tiago Rodrigues, and Virgılio Almeida. 2010. Detecting spammers on twitter. In CEAS.
关于检测Twitter上的垃圾邮件发送者,该类垃圾邮件包含热门话题,导致用户访问与话题完全无关的网站。
爬虫收集了Twitter上54981152个用户,通过1963263821条链接来连接,并收集了1755925520条推文。 推文上的内容特征:标签数量的占比,URL数量的占比,字数,标签数,URL数,出现的数字字符数量,提到的用户数量,被转发的次数等。 用户的行为特征:粉丝数量,关注者数量,粉丝/关注人数的比例,发布的tweet数量,年龄,被提及的次数,被回复的次数,回复别人的次数,用户粉丝中关注自己的数量,从关注者那里接受的tweet数量,用户的screename上是否存在spam词汇,每天、每周发布的tweet数量的最小值、最大值、平均值、中位数。The Latent Community Model for Detecting Sybil Attacks in Social Networks
Zhuhua Cai and Christopher Jermaine. 2012. The Latent Community Model for Detecting Sybils in Social Networks. In NDSS.
提出一个LC模型(Latent Community)来检测Sybil攻击
Uncovering Large Groups of Active Malicious Accounts inOnline Social Networks
Qiang Cao, Xiaowei Yang, Jieqi Yu, and Christopher Palow. 2014. Uncovering large groups of active malicious accounts in online social networks. In CCS. 477–488.
作者实现一个恶意账户检测系统SynchroTrap,根据恶意账户的行为,可以在一段时间内发现很多行为相似的恶意账户,目前已经在Facebook和Instagram上部署。
-
各种视频编码&封装格式
目前遇到的各种视频格式实在是太多了,而且除了用后缀名作区分的封装格式以外,还有各种不同的编码格式,不同的编码格式有不同的压缩率,也对硬件有不同的要求。所以干脆一口气调研清楚,并记录下来。
各种标准
ISO - MPEG标准
国际电联 ITU-T标准ISO ITU-T 描述 MPEG1 - VCD MPEG2 - DVD MPEG4(DivX) - MPEG4(Xvid) - MPEG4(AVC) H.264 MPEG4(HEVC) H.265 ITU-T
ITU-T的中文名称是国际电信联盟远程通信标准化组织(ITU-T for ITU Telecommunication Standardization Sector), 它是国际电信联盟管理下的专门制定远程通信相关国际标准的组织。由ITU-T指定的国际标准通常被称为建议(Recommendations)。 它制定的标准有H.261、H.263、H.263+等,目前流行最广的,影响也是最大的H.264也有他的一份功劳。
H - 视频音频以及多媒体系统复合方法
H.223 低码率多媒体通信复合协议
H.225.0 也被称为实时传输协议
H.261 视频压缩标准, 约1991年
H.262 视频压缩标准(和MPEG-2第二部分内容相同), 约1994年
H.263 视频压缩标准, 约1995年
H.263v2 (也就是 H.263+) 视频压缩标准, 约1998年
H.264 视频压缩标准(和MPEG-4第十部分内容相同), 约2003年
H.323 基于包传输的多媒体通信系统
ISO
国际标准化组织(ISO)是由各国标准化团体(ISO成员团体)组成的世界性的联合会。负责各种标准的制定,当然也少不了关于视频编码方面的。
由ISO下属的MPEG运动图象专家组开发视频编码方面主要是Mpeg1(vcd用的就是它)、Mpeg2(DVD使用)、Mpeg4(现在的DVDRIP使用的都是它的变种,如:divx,xvid等)、Mpeg4 AVC(H.264)
H.263可以2~4Mbps的传输速度实现标准清晰度广播级数字电视(符合CCIR601、CCIR656标准要求的720*576);而H.264由于算法优化,可以低于2Mbps的速度实现标清数字图像传送;H.265 High Profile可实现低于1.5Mbps的传输带宽下,实现1080p全高清视频传输。
编码格式
H.264/AVC
介绍:H.264/AVC标准是由ITU-T和ISO/IEC联合开发的,定位于覆盖整个视频应用领域,包括:低码率的无线应用、标准清晰度和高清晰度的电视广播应用、Internet上的视频流应用,传输高清晰度的DVD视频以及应用于数码相机的高质量视频应用等等。 AVC-Advanced Video Coding 特点:同H.263等标准的特率效率相比,能够平均节省大于50%的码率。
推荐码率设置
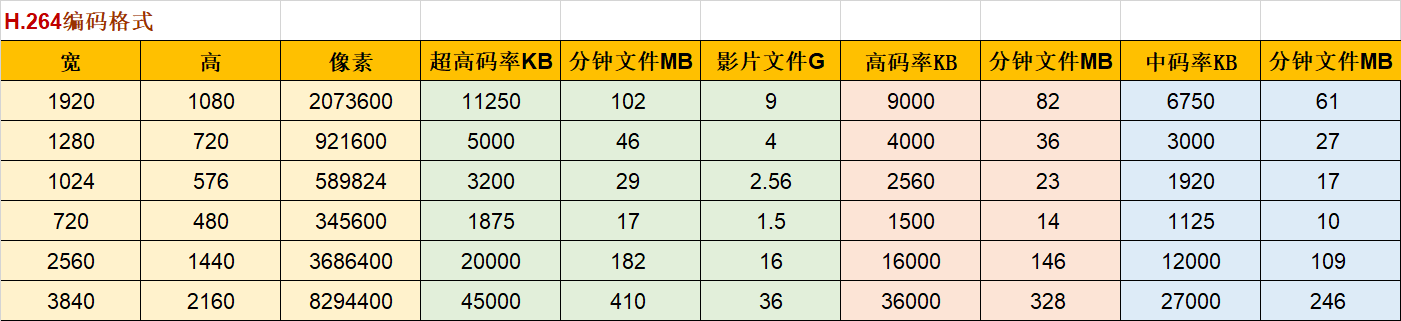
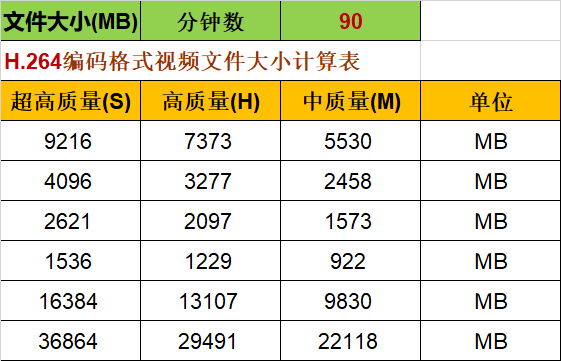
-
【精读】在注册时检测微信上的恶意账户
类型 内容 标题 Detecting Fake Accounts in Online Social Networks at the Time of Registrations 时间 2019 会议 CCS DOI 10.1145/3319535.3363198 引用 Yuan D, Miao Y, Gong N Z, et al. Detecting Fake Accounts in Online Social Networks at the Time of Registrations[C]://Proceedings of the 2019 ACM SIGSAC Conference on Computer and Communications Security. 2019: 1423-1438. 论文信息
https://zhuanlan.zhihu.com/p/33066384
作者信息
Dong Yuan,Yuanli Miao,Neil Zhenqiang Gong,Zheng Yang,Qi Li,Dawn Song,Qian Wang,Xiao Liang 清华大学网络科学与网络空间研究院 北京国家信息科学技术研究中心(BNRist) 杜克大学电气与计算机工程系 加州大学伯克利分校计算机科学系 武汉大学网络科学与工程学院 腾讯公司
摘要
社交网络上存在的虚假账户(Sybils),散布垃圾邮件、恶意软件和虚假信息。
目前Sybils的检测存在延迟,在被检测到的时候已经执行了很多恶意活动。
本论文提出名为Ianus的方法,利用账户注册信息来检测Sybil。
Ianus的目标是在它们注册后立即捕获它们。首先,利用中国最大的在线社交网络微信(WeChat)上带有Sybils标签的真实注册数据集,对Sybils和良性用户的注册模式进行了测量研究。我们发现Sybils倾向于synchronized和abnormal注册模式。
第二,根据测量结果,我们将Sybil检测建模为一个图推理问题,这使得我们能够集成异构特征。我们为每对帐户提取基于synchronized和异常的特征,使用这些特征构建一个图,其中Sybils彼此紧密连接,而良性用户与其他良性用户和Sybils隔离或解析连接,最后通过分析图的结构来检测Sybils。
我们使用微信的真实注册数据集评估用户。此外,微信部署Ianus为每日运行,即微信每天都会使用Ianus分析新注册的账户,我们发现Ianus每天可以对40万个新注册的账户进行检测,通过微信安全团队的手动验证,平均精度超过96%。介绍
如今,在线社交网络(例如Facebook和微信)特别受欢迎,这对我们的日常生活产生了巨大影响。 同时,它们也是攻击者的重要目标。 例如,在Sybil攻击中,攻击者注册并维护着大量的假帐户,以执行各种恶意活动,例如传播垃圾邮件,网络钓鱼URL,恶意软件和虚假信息以及窃取私人用户数据。
目前已经开发了很多检测在线社交网络中的Sybils的方法。 这些方法利用了由Sybils生成的内容(例如URL in tweets),行为(例如,点击流,喜欢,照片上传)和/或社交图。 它们面临一个局限性:在检测Sybils时会产生大量延迟。
即要求Sybils在检测到它们之前先生成丰富的内容,行为和/或社交图。 因此,Sybils在被发现之前可能已经进行了各种恶意活动。本文的目标是在注册时检测到Sybils。
首先,我们利用微信的一个匿名的注册数据集,对Sybils和良性用户的注册模式进行了系统的测量研究。数据集收集于2017年11月,其中良性用户有77万,Sybils用户有64.7万。每个注册都有一个属性列表,如IP地址、电话号码(可在微信中用作用户ID)、设备ID(如IMEI)、昵称等等。我们发现Sybils有相同的关于这些属性的synchronized注册模式。 例如,许多Sybils用24位相同前缀的IP地址进行注册,这意味着它们可能使用在同一局域网中的设备进行注册。 但是,synchronized不足以区分Sybils和良性用户。 尤其是某些良性用户还共享synchronized的注册属性,例如他们使用相同前缀的IP进行注册。其次,我们设计了Ianus来通过注册信息检测Sybils,一个关键的挑战是如何集成同步和异常的注册模式,Ianus用图推理技术来解决这个挑战。我们构建图的方式为:每个节点都是一个帐户,Sybils相互紧密连接,而良性帐户之间稀疏连接,也与Sybils稀疏连接。 Ianus具有三个组成部分,即特征提取,图形构建和Sybil检测。 在特征提取中,对于一对帐户,我们提取基于二进制同步的特征(例如,两个帐户使用同一设备进行注册)和基于异常的特征(例如,共享设备异常)。
在图构建中,我们使用基于同步的特征和基于异常的特征在帐户之间构建加权图。 具体来说,我们根据其特征为一对帐户分配sync-anomaly分数。 sync-anomaly评分可表征两个帐户之间的同步和异常模式,如果一对帐户具有更多同步和异常注册特征,则它们具有较高的同步异常评分。为一对帐户分配sync-anomaly分数的一种方法是对它们的二进制特征求和。 但是这种基于特征和的方法不会考虑特征的权重。 因此,我们使用机器学习(尤其是逻辑回归)来学习自动加权不同特征的sync-anomaly分数。接下来我们使用sync-anomaly分数在帐户之间创建边。 我们要构建一个Sybil之间紧密连接的图,仅当两个帐户都根据其sync-anomaly分数被预测为Sybil时,才在两个帐户之间创建边。将sync-anomaly分数视为边的权重。
在Sybil检测组件中,社区检测是检测Sybil的自然选择,因为Sybil是紧密连接在我们的图中的。 此外,我们设计了一种基于加权节点度的简单方法来检测Sybils。 具体而言,如果图中的节点通过具有较大权重的边连接到更多Sybil,这表明该节点更有可能是Sybil。 因此,如果节点的加权度足够大,则Ianus可以将其预测为Sybil。
第三,我们使用微信的注册数据集对Ianus进行评估,Ianus能够检测出大部分的Sybils(召回率为80.2%),准确率高达92.4%。此外,我们对Ianus的每个组件的不同设计都进行了广泛评估了。 具体来说,在特征提取中,我们的结果表明,基于同步的特征和基于异常的特征是互补的,将它们结合起来确实可以提高检测精度。 在图的构建中,我们发现使用逻辑回归学习的sync-anomaly分数要优于基于特征和的sync-anomaly分数。
在Sybil检测组件中,我们评估了流行的Louvain方法作为一种社区检测方法。实验结果表明,Louvain方法和基于加权节点度的方法具有很高的检测精度。然而,基于加权节点度的方法比基于Louvain的方法效率更高,例如,Louvain方法分析图需要40分钟,而基于加权节点度的方法只需要10分钟。微信每天都会部署Ianus,即用Ianus在每天注册的账户中检测Sybils。微信安全团队确认Ianus每天可以在百万个账户中检测到40万个Sybils,准确度超过96%。贡献:
- 我们进行了大规模的测量研究,以表征Sybils和良性用户的注册模式。我们发现Sybils有同步和异常注册模式
- 我们提出了利用注册数据检测Sybils的方法,基于同步模式和异常模式建立帐户的加权图,然后通过分析图的结构来检测Sybils。
- 我们使用来自微信的注册数据集评估Ianus。此外微信已部署Ianus,展示了Ianus的工业影响力。
相关工作
现有的在线社交网络Sybil检测方法123456789101112131415161718192021222324252627282930主要利用Sybils生成的内容、行为和/或社交图。基于内容和行为的方法6810151619213123通常将Sybil检测建模为二进制分类问题,并利用机器学习技术。具体来说,他们首先从用户的内容中提取特征(例如,帖子,推特)或行为(发推,喜欢,照片上传和点击流的频率)。然后,他们通过有监督的机器学习技术(如logistic回归)或无监督的机器学习技术(如社区检测、聚类)分析特征来检测Sybils。例如,SynchroTrap6利用集群技术检测基于同步用户行为的Sybils,例如照片上传。
EvilCohort 17利用用户的IP地址来检测Sybil。具体地说,给定用户的登录名,EvilCohort会构建一个用户IP双向图,其中用户与IP之间的边缘表示该用户曾经从IP登录。 然后,EvilCohort使用Louvain方法在用户IP图中检测Sybil。 EvilCohort可能需要多个用户登录,以便Sybils在用户IP双向图中形成社区。 在多次登录期间,Sybils可能已经执行了恶意活动。 除了注册,我们的方法不需要用户登录。
基于社交图的方法1345791112131820242526272930利用基于图的机器学习技术(例如随机游走357321324252627,信念传播3311343536和社区发现420)来分析社会结构 用户之间的图表。 这些方法的主要局限性在于它们依赖于Sybils生成的丰富的内容,行为和/或社交图谱,从而导致检测Sybils的时间大大延迟。
Hao等人37提出了PREDATOR在注册时检测恶意域名。 检测恶意域和检测Sybil需要不同的特征,例如Ianus利用了来自移动设备,操作系统,用户位置和昵称的特征。 Xie等人38使用Souche尽早识别合法用户。 与Ianus不同,Souche依赖于用户之间的活动,例如互相发送消息。 Leontjeva等人39提出了一种在Skype中检测Sybils的方法。Sybils不仅使用注册功能,还利用了多种功能,这些功能要求帐户生成足够的内容和社交数据。
Thomas等人的工作19也许是与我们最相关的。 他们利用注册数据来检测Twitter中的Sybil。但是,他们利用了特定于Twitter的注册数据(例如注册流程,用户代理,表单提交时间),而Ianus利用了不同的注册数据,例如IP,电话号码,设备等等
###注册模式
微信和数据集
该数据集于2017年11月收集,共140万个注册帐户,包括大约77万个良性帐户和65万个Sybil帐户。
标签是从微信现有的基于行为的Sybil检测系统(该系统会几个月后为账户打标签,因为它需要足够的帐户行为)获取标签和用户报告(用户可以在微信中报告其他人为Sybil)。 微信安全团队随机采样并手动检查了一些帐户,发现准确率超过95%。我们认为这种偏差很小,并且我们的测量结果具有代表性。注册属性:每个注册都有一个属性列表,如表1所示。
Attribute Example IP ... Phone Number +86-157-7944-xxxx Timestamp 1499270558 Nickname *** WeChat Version 6.6.7 OS Version iOS 10.3.2 Hashed WiFi MAC a9d0cf034aa4e113e8ca27e9110928c7 Hashed Device ID d5c027d91d1df579d6ad1bffbb638cee WiFi-MAC是用于注册帐户的电话的接入点的MAC地址,而设备ID是用于注册帐户的电话的IMEI/Adsource。
伦理和隐私考虑:收集的数据已经在微信隐私政策中明确规定,用户在使用微信前同意。此外,为了保护用户隐私,微信对这些属性进行了匿名化处理,使其足以用于我们的分析。具体地说,一个IP地址有四个段,每个段都是单独散列的。电话号码的最后四位数字(即客户代码)将被删除。所有数据都存储在微信的服务器上,我们通过一个实习项目访问它们。
Synchronization
我们发现,Sybil帐户显示出常见的注册模式,例如,它们可能使用相同的IP、来自相同区域的电话号码、相同的设备(由其设备ID标识)以及具有相同模式的昵称。我们认为原因是攻击者只拥有有限的资源(即IP、电话号码和设备),并使用某些脚本自动注册Sybil帐户。稍微滥用一下术语,我们就称之为Synchronization注册模式。接下来描述我们的测量结果。
IP:微信目前只支持IPv4注册。IPv4地址有四个段。我们将前三个段(即前24位)视为本地网络标识符。在某些情况下(例如使用CIDR)前三段可能不代表本地网络,然而我们发现使用前三个段来表示IP对于Sybil检测是有用的。因此,如果两个IP具有相同的24位前缀,则我们将它们视为在相同网络下。我们的数据集中总共有264830个24位IP前缀。对于每个24位IP前缀,我们将使用IP前缀注册的良性(或Sybil)帐户组合在一起。因此,组的大小指示从相应的24位IP前缀注册的良性(或Sybil)帐户数。图1(a)显示了注册给定数量良性(或Sybil)帐户的IP前缀的数量。我们观察到大多数IP前缀注册了少量帐户,而少量IP前缀注册了大量帐户。例如,34.5%和15.5%的IP前缀分别注册了80%的良性和Sybil帐户。
此外,Sybil帐户更可能使用相同的IP前缀进行注册。 注册大量Sybil帐户的IP前缀要比注册大量良性帐户的IP前缀多得多。 图1(b)进一步显示了在注册了给定数量帐户的IP前缀中注册的帐户中Sybils的比例。 例如,当x轴是0-1时,我们找到注册了0-500个帐户的所有IP前缀,而y轴是这些帐户中Sybils的比例。一个IP前缀仅注册了少量的帐户(例如0-500),则很难仅仅根据这些帐户共享IP前缀的事实来判断它们是否是Sybils。然而当从同一IP前缀注册了大量(>2500)帐户时,这些帐户更可能是Sybils。

电话号码: 图2(b)显示了从注册了给定数量帐户的电话号码前缀注册的帐户中Sybils的分数。和IP前缀一样,我们观察到电话号码前缀的类似同步模式。特别是大量的电话号码前缀注册了少量的账号,而少量的电话号码前缀注册了大量的账号;Sybil更可能用同样前缀的电话号码注册账号,如果同一个前缀注册了超过30个账户,那么这些账户很可能是Sybils。
 设备:与IP前缀和电话号码前缀类似,图3(a)显示注册给定数量帐户的设备(由IMEI或Adsource标识)的数量,而图3(b)显示注册给定数量帐户的设备注册的帐户中Sybils的比例。我们观察到类似的同步模式:Sybil很可能是从相同的设备注册的。
设备:与IP前缀和电话号码前缀类似,图3(a)显示注册给定数量帐户的设备(由IMEI或Adsource标识)的数量,而图3(b)显示注册给定数量帐户的设备注册的帐户中Sybils的比例。我们观察到类似的同步模式:Sybil很可能是从相同的设备注册的。虽然攻击者可以伪造设备ID,例如修改Android应用程序框架。我们的结果表明,攻击者没有对Sybil帐户的注册执行这种设备欺骗。

昵称:在这里,我们对昵称模式分析显示了一些定性结果。在第4.2节中,我们将使用自然语言处理工具从昵称中提取模式和特征。 表2显示了三个昵称模式,每个模式的一个示例,以及昵称遵循特定模式的帐户中Sybils的比例。数据集中的昵称被微信匿名化处理了,所以我们不能理解昵称的语义模式。表2中的结果是在微信安全工程师的帮助下得到的。我们观察到,一些昵称模式(例如,中文+数字)更有可能被良性账户使用,而一些昵称模式(如小写+数字、数字+小写+数字)更有可能被Sybils使用。我们认为Sybils共享昵称模式的原因是,它们是由脚本根据特定模式生成的昵称。
模式 举例 比例 中文+数字 李四2416 32.2% 英文小写+数字 cii2133,vqu7868 94.4% 数字+英文小写+数字 07740922a179 95.0% 含义:一方面,我们的测量结果表明同步模式可用于检测Sybil。例如,我们可以设计一种简单的方法(我们将在第5节的实验中显示更多详细信息)来根据IP,电话号码或设备的普及程度来检测Sybil帐户。 给定其中一天中的所有账户注册信息,我们可以认为从同一IP注册数量超过一定阈值的账户都是Sybil。这种简单的检测器在我们的数据集中可以达到几乎100%的精度。
另一方面,单个属性(例如IP,电话号码或设备)的同步不足以检测Sybil。 例如基于电话号码的检测器仅实现59%的召回率。 因此我们将结合多个属性的同步模式和异常模式一起进行检测。
异常模式
注册时间:图4显示了从同一IP前缀注册的帐户相对于时间的分布。 每个图显示20个示例IP前缀的结果。 我们将一天24小时划分为96个15分钟的间隔。 图表中的每条垂直线显示在这96个时间间隔中从某个IP前缀注册的帐户,其中点的大小与在相应时间间隔中注册的帐户数量成比例。 我们观察到,当使用相同的IP前缀注册良性帐户时,它们在白天被均匀注册,而少数在午夜注册。 但是当Sybil通过相同的IP前缀注册时,它们是在深夜集中注册的。

地理位置不一致:IP地址可以映射到地理位置,电话号码也可以使用其区号映射到地理位置。 我们发现,有65%的Sybils在注册时基于IP的位置和基于电话号码的位置不同。 此外,用户可以在注册帐户时指定其位置(例如国家/地区)作为其帐户资料的一部分,我们发现96%的Sybils指定的国家与基于IP的国家不一致。
稀有和过时的微信和操作系统版本:我们观察到从稀有和过时的微信和操作系统版本注册的帐户更有可能是Sybils。 例如某个Android版本仅在我们的数据集中注册了2K帐户,其中96.5%是Sybils。 同样,从iOS 8注册的帐户中有99%是Sybils。 可能的原因包括:攻击者使用微信和操作系统版本已过时的旧设备来注册Sybil,并且攻击者使用脚本自动注册了Sybil,而未在脚本中更新其微信和操作系统版本。
IANUS的设计
概览
Ianus的目标是利用注册数据来检测Sybils。Ianus由三个关键部分组成,即特征提取、图形生成和Sybil检测。图5显示了这三个组件。在特征提取中,我们提取基于同步的特征和基于异常的特征。基于同步的特征描述一对注册是否具有相同的注册属性,而基于异常的特征进一步描述这些属性是否异常。

图构建组件旨在构建一个加权图来集成同步模式和异常模式。我们称之为注册图。图中的每个节点是一次注册,我们的目标是使得Sybils通过权重较大的边紧密地连接在一起,而良性帐户则稀疏地连接在一起。为了构建这样一个图,我们首先使用logistic回归学习每对注册的sync-anomaly分数。我们使用同步异常评分来量化两个注册之间的同步和异常模式。较高的sync-anomaly分数意味着这两个注册更可能是Sybils。如果两个注册间的sync-anomaly分数足够大,我们在两个注册之间创建一个边。
在我们的注册图中,具有更高加权度的节点更有可能是Sybil。因此,如果一个节点的加权度大于阈值,我们就预测该节点为Sybil节点,而阈值是使用机器学习技术学习的。
特征提取
同步特征
如果两个注册的属性具有相同的值,则对应的特征为1,否则该特征为0。
特征 Description (Both registrations…) S-IP24 use the same 24-bit IP prefix S-IP32 use the same IP address S-PN use the same phone number prefix S-OS use the same OS version S-WeChat use the same WeChat version S-MAC use the same WiFi MAC address S-Device use the same device S-NP1 have the same syntactic nickname pattern S-NP2 have the same semantic nickname pattern 基于昵称的特征:S-NP1和S-NP2特征分别基于句法和语义模式。我们从词汇V={C,L,U,D,···}中定义一个字符串作为句法模式,其中C表示中文字符,L和U分别表示小写和大写英文字母,D表示数字,而每个标点和特殊字符(例如,;,+)仍然是词汇中的一个字符。例如,昵称abAB12++的语法模式是CCLLUUDD++。如果两个注册的昵称具有相同的语法模式,则特征S-NP1为1。
句法模式考虑昵称的结构,但忽略其语义。例如,一个随机的中文字符串和一个中文名称可以有相同的语法模式,但语义不同。如果两个帐户的昵称都是随机的中文字符串,则会更同步,因为攻击者的脚本可能会自动生成随机的中文字符串。因此,我们进一步从昵称中提取语义模式。具体来说,我们定义了几种语义模式,包括汉语短语、随机汉语串、英语短语、汉语拼音和随机英语串。我们将这些语义模式中的汉语短语和随机汉语串提取出来,作为只使用汉语的昵称,并提取出了英语短语、汉语拼音和汉语拼音的语义模式,以及仅使用英文字母的昵称的随机英文字符串。汉语拼音是用英文字母表示汉字的一种方法。
为了提取这些语义模式,我们收集了一个由微信订阅的数十万篇文章组成的大型汉语语料库和一个包含数十万个英语单词和数百万个汉语拼音的大型英语语料库。然后,我们使用srilm40和Jieba[^1]分别训练了汉语句子、英语句子和汉语拼音的n-gram模型。 最后,我们使用n-gram模型提取昵称的语义模式。如果昵称是中文字符串,则可能性很大,如果两个注册的昵称具有相同的语义模式,则其特征S-NP2为1。
基于异常的特征
我们还为一对注册提取基于异常的特征。这描述了一对注册是否都具有异常属性。首先为每个注册提取异常的特征,然后将一对注册的特征串联在一起。我们可以提取基于异常的特征FA用于注册A,连接特征(FA,FB)作为两个注册的统一特征。然而这受到两者的顺序即(FA,FB)与(FB,FA)的影响。因此在提取基于异常的特征时,我们共同考虑这两对注册的属性,这不依赖于两个注册的顺序。 表4显示了基于异常的二进制特性。如果两个注册的对应属性都异常,则特征为1
Feature Description(Both registrations…) A-Location have different user-specified and IP-based countries A-OS use rare or old OS versions A-WeChat use rare or old WeChat versions A-Time were registered at late night, i.e., 2am–5am A-NP have the same nickname pattern that is abnormal -
地理位置不一致(A-Location):用户可以在个人资料中任意指定自己的位置。此位置信息将显示给朋友。有些sybil将它们的位置指定为一个特定的位置,目标是将用户定位在该位置,而不管sybil是从何处注册的。如果两个注册都有地理位置和IP位置不一致的现象,则为1.
- 稀有和过时的OS和微信版本(A-OS和A-WeChat):略
- 注册时间(A-Time): 都在深夜注册时为1(凌晨2点-5点)
- 昵称模式(A-NP):如如果两个注册共享一个昵称模式,并且昵称模式异常,则A-NP为1。
建立注册图
目标:构造一个加权图来表示帐户之间的关系,节点是一个帐户,Sybils通过具有较大权重的边彼此连接,良性帐户稀疏连接。 利用机器学习技术来使用它们的特征向量为每对注册学习一个分数。 较大的分数意味着这对注册共享更多的属性,更有可能是Sybils。 我们将该分数称为sync-anomaly分数。
学习sync-anomaly分数
有监督的机器学习:logistics回归 一对注册:标签为正表示都是都是Sybils,为负表示都是良性。
为注册对分配标签:假设有一个特征向量fa,S(fa)为Sybils对的集合, T(fa)是所有注册对的集合。如果有一个特征fb,当fa等于1的时候,fb也是1,则拓展它。即S(fa)=S(fa)∪S(fb),T(fa)=T(fa)∪T(fb).
最后,计算特征向量fa的支持比 S(fa)/T(fa),如果大于一个阈值,则给一个正标签,否则是一个负标签。 选择的阈值:0.98学习sync-anomaly得分: 根据(特征向量,标签),学习一个logistics回归。
该分类器以特征向量为输入,输出具有正标签的概率。在使用历史训练数据集学习logistic回归分类器之后,我们可以在将来将该分类器应用于成对的注册。具体来说,对于一对注册,我们构造其特征向量,并使用分类器计算特征向量具有正标签的概率(即两个注册都是Sybils)。我们将这个概率视为这一对注册的sync-anomaly分数。从0到1不等。如果评分大于0.5,则分类器会预测它们都是Sybils。
构造注册图
只有当得分大于0.5时,我们才在两个帐户之间创建一个边,并使用sync-anomaly得分作为边的权重。 如果把每一对注册都进行构造,一周有百万次的注册行为,那么需要计算10^14次
将注册分成组,每一组内有相同的注册属性(IP前缀、电话号码前缀或设备ID),只计算组内的得分。
检测Sybils
如果一个节点在注册图中与更多的邻居连接,那么该节点更有可能是Sybil。
训练了一个基于加权节点度的二值分类器。以加权和作为输入。 因为加权和范围很宽,所以使用tanh进行规范化,使其范围在(-1,1)之间。 使用名为EasyEnsemble36的分类器。
评估
实验准备
数据集:我们从微信获取了两个注册数据集,分别于10月和2017年11月收集。 数据集I包含10月的注册,而数据集II包含11月的注册,这大约是在数据集I之后的一周。
标签由微信安全团队提供,经验证标签准确率大于95%。 数据集 |#Sybils |#Benign –|–|– Dataset I |779k |681k Dataset II |647k |770k方法比较:
-
Ianus
Ianus同时使用同步和基于异常的特征;Ianus使用logistic回归来学习同步异常分数;Ianus使用基于加权节点度的方法来检测Sybils。具体来说,我们使用Spark中实现的logistic回归和默认参数设置。 -
Ianus-Sync和Ianus-Anomaly
Ianus-Sync和Ianus-Anomaly分别使用同步和基于异常的特征。 -
Ianus-FS
Ianus FS计算一对注册的同步异常得分,如果同步异常得分大于阈值,则在两个注册之间创建边。我们将研究不同阈值对Ianus-FS的影响 -
Ianus-CD
Ianus-CD使用Louvain方法检测注册图中的社区,并将大于阈值的社区视为Sybils。我们将研究不同的阈值 -
Ianus-FS-CD
此变体结合了Ianus-FS和Ianus-CD。 具体来说,Ianus-FS-CD将二元特征作为图构建组件中的sync-anomaly相加,并在Sybil检测组件中使用社区检测。 请注意,Ianus-FS-CD是一种无监督方法,因为它不需要历史训练数据集即可学习同步异常评分和基于节点度的分类器。
-
LorenzoAlvisi,AllenClement,AlessandroEpasto,SilvioLattanzi,andAlessandroPanconesi. 2013. SoK: The Evolution of Sybil Defense via Social Networks. In IEEE S & P. ↩ ↩2
-
Fabrıcio Benevenuto, Gabriel Magno, Tiago Rodrigues, and Virgılio Almeida. 2010. Detecting spammers on twitter. In CEAS. ↩
-
YazanBoshmaf,DionysiosLogothetis,GeorgosSiganos,JorgeLería,JoseLorenzo,Matei Ripeanu, and Konstantin Beznosov. 2015. Integro: Leveraging Victim Prediction for Robust Fake Account Detection in OSNs.. In NDSS, Vol. 15. 8–11. ↩ ↩2 ↩3
-
Zhuhua Cai and Christopher Jermaine. 2012. The Latent Community Model for Detecting Sybils in Social Networks. In NDSS. ↩ ↩2 ↩3
-
Qiang Cao, Michael Sirivianos, Xiaowei Yang, and Tiago Pregueiro. 2012. Aiding the detection of fake accounts in large scale social online services. In NSDI. ↩ ↩2 ↩3
-
Qiang Cao, Xiaowei Yang, Jieqi Yu, and Christopher Palow. 2014. Uncovering large groups of active malicious accounts in online social networks. In CCS. 477–488. ↩ ↩2 ↩3
-
G. Danezis and P. Mittal. 2009. SybilInfer: Detecting Sybil Nodes using Social Networks. In NDSS. ↩ ↩2 ↩3
-
Manuel Egele, Gianluca Stringhini, Christopher Kruegel, and Giovanni Vigna. 2015. Towards Detecting Compromised Accounts on Social Networks. IEEE Transactions on Dependable and Secure Computing 12, 2 (2015), 447–460. ↩ ↩2
-
D.Freeman,M.Dürmuth,andB.Biggio.2016.Whoareyou?Astatisticalapproachto measuring user authenticity. In NDSS. ↩ ↩2
-
Hongyu Gao, Jun Hu, Christo Wilson, Zhichun Li, Yan Chen, and Ben Y Zhao. 2010. Detecting and characterizing social spam campaigns. In IMC. 35–47. ↩ ↩2
-
Neil Zhenqiang Gong, Mario Frank, and Prateek Mittal. 2014. Sybilbelief: A semi-supervised learning approach for structure-based sybil detection. IEEE Transactions on Information Forensics and Security 9, 6 (2014), 976–987. ↩ ↩2 ↩3
-
ChangchangLiu,PengGao,MatthewWright,andPrateekMittal.2015.Exploitingtemporal dynamics in Sybil defenses. In CCS. 805–816. ↩ ↩2
-
Abedelaziz Mohaisen, Nicholas Hopper, and Yongdae Kim. 2011. Keep your friends close: Incorporating trust into social network-based Sybil defenses. In IEEE INFOCOM. ↩ ↩2 ↩3
-
AbedelazizMohaisen,AaramYun,andYongdaeKim.2010.Measuringthemixing time of social graphs. In IMC. ↩
-
Jonghyuk Song, Sangho Lee, and Jong Kim. 2011. Spam filtering in Twitter using sender-receiver relationship. In RAID. ↩ ↩2
-
Gianluca Stringhini, Christopher Kruegel, and Giovanni Vigna. 2010. Detecting spammers on social networks. In ACSAC. ↩ ↩2
-
Gianluca Stringhini, Pierre Mourlanne, Gregoire Jacob, Manuel Egele, Christo-pher Kruegel, and Giovanni Vigna. 2015. Evilcohort: detecting communities of malicious accounts on online services. In USENIX Security Symposium. 563–578. ↩ ↩2
-
Kurt Thomas, Frank Li, Chris Grier, and Vern Paxson. 2014. Consequences of connectivity: Characterizing account hijacking on twitter. In CCS. 489–500. ↩ ↩2
-
Kurt Thomas, Damon Mccoy, Alek Kolcz, Alek Kolcz, and Vern Paxson. 2013. Trafficking fraudulent accounts: the role of the underground market in Twitter spam and abuse. In Usenix Security Symposium. 195–210. ↩ ↩2 ↩3
-
BimalViswanath,AnsleyPost,KrishnaP.Gummadi,andAlanMislove.2010.An Analysis of Social Network-Based Sybil Defenses. In ACM SIGCOMM. ↩ ↩2 ↩3
-
Alex Hai Wang. 2010. Don’t Follow Me - Spam Detection in Twitter. In SECRYPT 2010. ↩ ↩2
-
Zenghua Xia, Chang Liu, Neil Zhenqiang Gong, Qi Li, Yong Cui, and Dawn Song. 2019. Characterizing and Detecting Malicious Accounts in Privacy-Centric Mobile Social Networks: A Case Study. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. ACM, 2012– 2022. ↩
-
Chao Yang, Robert Harkreader, and Guofei Gu. 2011. Die Free or Live Hard? Empirical Evaluation and New Design for Fighting Evolving Twitter Spammers. In RAID. ↩ ↩2
-
Chao Yang, Robert Harkreader, Jialong Zhang, Seungwon Shin, and Guofei Gu. 2012. Analyzing Spammer’s Social Networks for Fun and Profit. In WWW. ↩ ↩2 ↩3
-
Zhi Yang, Jilong Xue, Xiaoyong Yang, Xiao Wang, and Yafei Dai. 2016. VoteTrust: Leveraging Friend Invitation Graph to Defend against Social Network Sybils. IEEE Transactions on Dependable and Secure Computing 13, 4 (2016), 488–501. ↩ ↩2 ↩3
-
H.Yu,P.B.Gibbons,M.Kaminsky,andF.Xiao.2008.SybilLimit:ANear-Optimal Social Network Defense against Sybil Attacks. In IEEE S & P. ↩ ↩2 ↩3
-
H. Yu, M. Kaminsky, P. B. Gibbons, and A. Flaxman. 2006. SybilGuard: Defending Against Sybil Attacks via Social Networks. In SIGCOMM. ↩ ↩2 ↩3
-
Yao Zhao, Yinglian Xie, Fang Yu, Qifa Ke, Yuan Yu, Yan Chen, and Eliot Gillum. 2009. BotGraph: Large Scale Spamming Botnet Detection. In NSDI. ↩
-
Haizhong Zheng, Minhui Xue, Hao Lu, Shuang Hao, Haojin Zhu, Xiaohui Liang, and Keith Ross. 2018. Smoke Screener or Straight Shooter: Detecting Elite Sybil Attacks in User-Review Social Networks. In Proceedings of the Network and Distributed System Security Symposium (NDSS). ↩ ↩2
-
Yang Zhi, Christo Wilson, Tingting Gao, Tingting Gao, Ben Y. Zhao, and Yafei Dai. 2011. Uncovering social network Sybils in the wild. Acm Transactions on Knowledge Discovery from Data 8, 1 (2011), 2. ↩ ↩2
-
Gang Wang, Tristan Konolige, Christo Wilson, Xiao Wang, Haitao Zheng, and BenYZhao.2013. Youarehowyouclick:Clickstreamanalysisforsybildetection.In USENIX Security Symposium. 241–256. ↩
-
Jinyuan Jia, Binghui Wang, and Neil Zhenqiang Gong. 2017. Random walk based fake account detection in online social networks. In 2017 47th Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN). IEEE, 273–284. ↩
-
Peng Gao, Binghui Wang, Neil Zhenqiang Gong, Sanjeev R Kulkarni, Kurt Thomas, and Prateek Mittal. 2018. Sybilfuse: Combining local attributes with global structure to perform robust sybil detection. In 2018 IEEE Conference on Communications and Network Security (CNS). IEEE, 1–9. ↩
-
Binghui Wang, Neil Zhenqiang Gong, and Hao Fu. 2017. GANG: Detecting fraudulent users in online social networks via guilt-by-association on directed graphs. In 2017 IEEE International Conference on Data Mining (ICDM). IEEE, 465–474. ↩
-
BinghuiWang,JinyuanJia,andNeilZhenqiangGong.2018.Graph-basedsecurity and privacy analytics via collective classification with joint weight learning and propagation. arXiv preprint arXiv:1812.01661 (2018). ↩
-
Binghui Wang, Le Zhang, and Neil Zhenqiang Gong. 2017. SybilSCAR: Sybil detection in online social networks via local rule based propagation. In IEEE INFOCOM 2017-IEEE Conference on Computer Communications. IEEE, 1–9. ↩ ↩2
-
Shuang Hao, Alex Kantchelian, Brad Miller, Vern Paxson, and Nick Feamster. 2016. PREDATOR: Proactive Recognition and Elimination of Domain Abuse at Time-Of-Registration. In CCS. ↩
-
Yinglian Xie, Fang Yu, Qifa Ke, Martín Abadi, Eliot Gillum, Krish Vitaldevaria, Jason Walter, Junxian Huang, and Z. Morley Mao. 2012. Innocent by Association: Early Recognition of Legitimate Users. In CCS. ↩
-
Anna Leontjeva, Moises Goldszmidt, Yinglian Xie, Fang Yu, and Martín Abadi. 2013. Early security classification of skype users via machine learning. In AISec. ↩
-
AndreasStolcke.2002.SRILM-anextensiblelanguagemodelingtoolkit.InSeventhinternational conference on spoken language processing. ↩