最新日志
-
【调研】态势感知
概念
态势感知是一种基于环境的、动态、整体地洞悉安全风险的能力,是以安全大数据为基础,从全局视角提升对安全威胁的发现识别、理解分析、响应处置能力的一种方式。
态势感知的概念最早在军事领域被提出,覆盖感知、理解和预测三个层次。Bass 于 1999 年首次提出网络态势感知(Cyberspace Situational Awareness,简称 CSA)的概念,并且指出,“基于融合的网络态势感知”必将成为网络管理的发展方向。所谓网络态势是指由各种网络设备运行状况、网络行为以及用户行为等因素所构成的整个网络的当前状态和变化趋势。值得注意的是,态势强调环境、动态性以及实体间的关系,是一种状态,一种趋势,一个整体和宏观的概念,任何单一的情况或状态都不能称其为态势。1
网络安全态势感知研究是近几年发展起来的一个热门研究领域。它融合所有可获取的信息实施评估网络的安全态势,为网络安全管理员的决策分析提供依据,将不安全因素带来的风险降到最低。网络安全态势感知在提高网络的监控能力、应急响应能力和预测网络安全的发展趋势等方面都具有重要的意义。
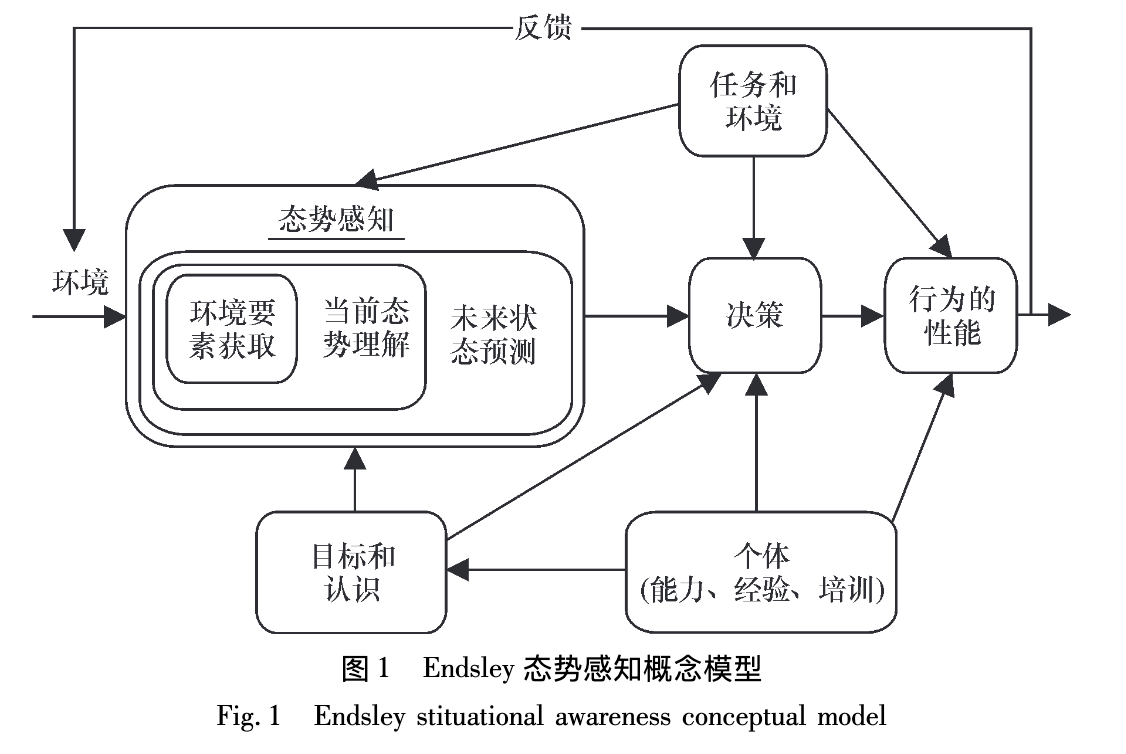
总的来说,态势感知目前理论上主要分为以下三个部分:对环境元素的感知、对状态的的理解、对未来状态的预测。
应用2
公安网监部门:优化公安网监部门对网络安全态势预警分析、通报预警、快速处置的能力。提升关键信息基础设施的防护能力,强化公安机关网安部门网络安全的基础能力。掌控安全态势感知,提升防范能力,打击预防违法犯罪。
大型企业:加强大型企业对已有的基础网络及信息化业务系统的脆弱性分析和安全态势预警分析能力。提升大型企业在复杂的网络环境中的感知和防护能力。巩固企业内网网络安全态势感知管理。
第三方运营机构:平台面向社会化网络安全态势感知运营的主管部门机构。加强对网络中的潜在威胁的感知能力,提升持续威胁监控、分析和应急响应的能力,减少网络恶性事件的发生,提升面向社会的服务能力。
关键技术3
网络安全要素提取
网络安全要素提取是指采集网络环境中相关要素的状态、属性和动态等信息,并将信息提取融合,归入各种可理解的表现方式。
当前主要数据采集来源为网络设备的系统配置信息、网络设备的运行日志信息以及防护工具的警报信息与日志 信息等,通过将这些信息进行有效整合,为态势感知的高维抽象理解提供了基础。但现阶段仍存在觉察结果的精度不足,如冗余数据或错误告警信息对攻击活动的重构仍然有很大的影响;觉察的效率不高,如很多采用离线的方式进行关联性分析和攻击过程重构,无法满足快速响应要求。
因此安全态势要采集的数据也因网络环境而不同,可根据实际情况有选择地采集。一般需要采集的数据包括:4
(1)网络流量数据(大小、流量成分信息)
(2)网络性能数据(延迟、抖动)
(3)关键网络设备性能数据(CPU利用率、端口利用率、路由稳定性数据等)
(4)关键网络设备的配置及漏洞信息
(5)关键网络设施的物理环境信息(温度、湿度、容灾能力)
(6)入侵事件的数量和严重等级
(7)拒绝服务工具事件的数量和等级
(8)僵尸网络的数量和规模
(9)仿冒及挂马网站的数量和分布
(10)垃圾邮件的数量
(11)感染恶意程序的主机数量
(12)安全预警信息(安全通告、安全事件、攻击情报)
网络安全态势理解
态势理解建立在要素提取的基础上,通过对海量数据的计算处理,绕过复杂难懂的表象,帮助分析者和决策者以更高维的视角理解网络状态。包括重大网络安全事件检测分析,指标体系构建,态势评估和数据可视化。
常用的安全事件检测方式有入侵检测系统和入侵防御系统。入侵检测系统主要对异常的可能性数据进行检测并对告警提供解决方式,是侧重于风险管理的安全产品。入侵防御系统主要对明确判别为攻击行为的危害进行检测和防御,侧重于风险控制。
网络安全指标体系是一套能全面反映网络安全特征,具有内在联系、相互互补的指标合集,指标体系的构建为态势理解和预测提供计算和评估依据。网络安全指标体系的构建是整个网络安全态势评估的核心,其主要的目标是建立态势评估因子到最终态势值之间的映射关系,因 为随着攻击事件、网络技术结构的不断发展变化,评估因子必然也随之在改进,正如上述具有代表性的指标体系一样,具有当时所处阶段的特点,所以指标体系构建是一个动态演化的过程。
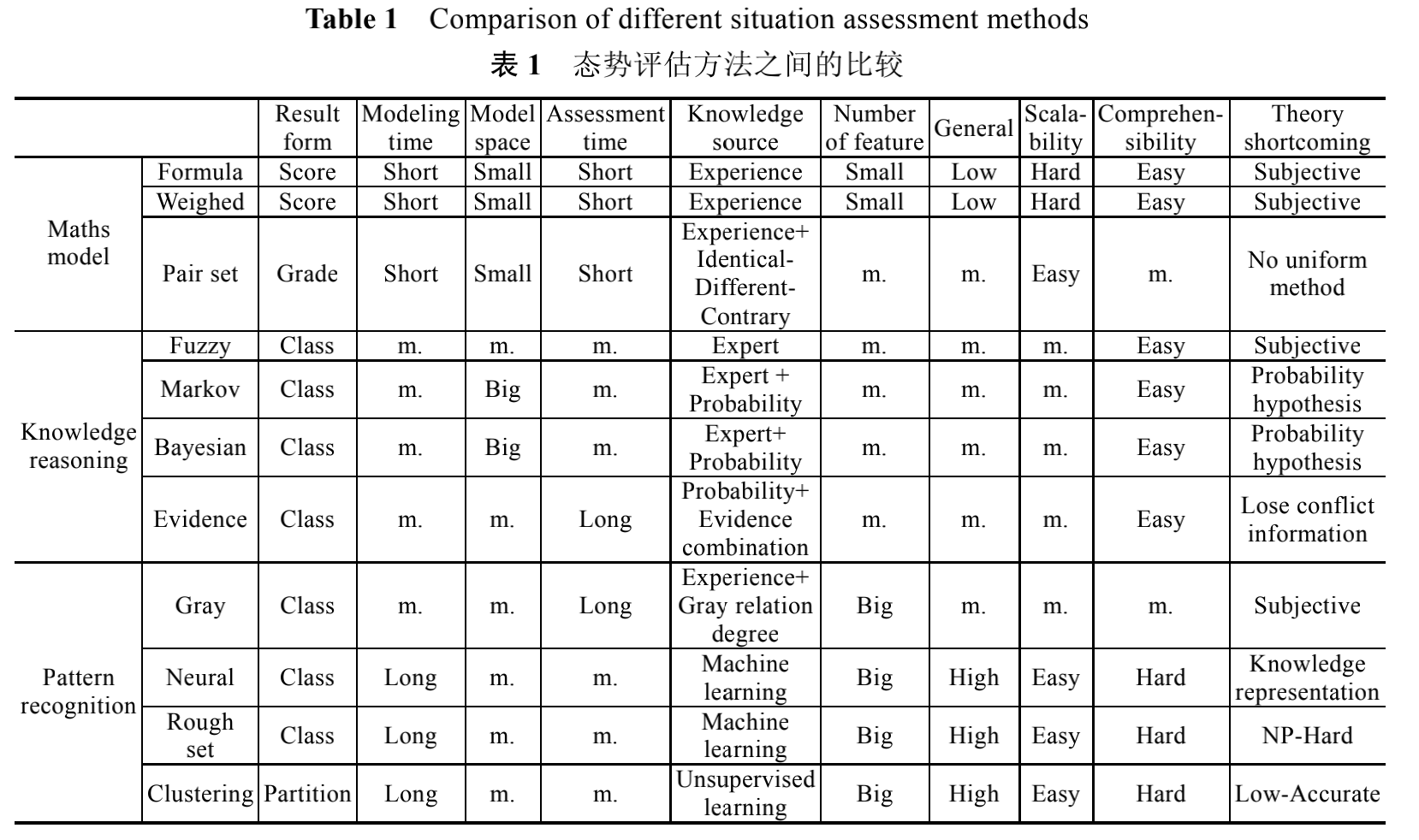
态势评估方法是态势感知乃至数据融合领域的重点因此备受关注,理论研究相对成熟。有些研究将理论创新引入态势评估领域,有些则对传统方法进行拓展,还有的将多种理论综合运用,目的就是对不确定性信息进行分析,提高态势评估的准确性,同时还要在时间开销、评估代价等因素之间进行折衷。在众多评估方法中,传统方法包括贝叶斯技术、基于知识的方法、人工神经网络、模糊逻辑技术,引入的新理论有集对分析、D-S 证据理论、粗集理论、灰关联分析、聚类分析等。这些方法大致可以分为 3 类:基于数学模型的方法、基于知识推理的方法和基于模式识别的方法。
数据可视化在网络安全态势感知的整个数据信息交流过程中起到了十分重要的支撑作用,如何快速、准确、有效地将态势传达给决策者是十分具有挑战性的问题。
网络安全态势预测
态势预测是态势安全的另一关键,是在获取、变换及处理历史和当前态势数据序列的基础上,通过建立数学模型,探寻演变规律,对未来发展趋势和状况进行推理。目前有很多预测方法,如神经网络、灰色理论、时间序列分析和支持向量机等。
基于传统方法的预测
根据态势的时间序列的历史变化,对未来做出延展预测,称为时间序列预测。另一预测方法是基于因果关系,由若干变量的观测值来确定变量之间的依赖关系。
基于神经网络的网络安全态势预测
得益于硬件计算速度的提升,基于神经网络、深度学习的机器学习方法在近几年发展迅速。在网络安全态势感知领域,通过建立机器的自动感知和自学习机制,使其拟合专家的思维能力和分析判断能力,可以更加灵活地对复杂网络安全事件进行预测。
但神经网络也并非一劳永逸,对数据量规模的敏感,造成其收敛计算过程中容易产生的过拟合或者欠拟合性;另 外,当前基于神经网络、深度学习的机器学习方法,在模型参数、复杂性设计上还存在依赖于人工经验的问题,也是亟待解决的方向。
未来趋势
网络安全态势感知和网络威胁必然会像盾与矛的关系一样,在对抗中不断交错提升,当互联网技术的更新无形推动着网络威胁的迭代升级时,网络安全态势感知也将会更好地利用新的技术、新的方法演化出更加完善的体系。
(1) 数据融合。网络安全态势的数据来源分布广、容量大、形态杂,不同的运 营 商、不同的管理系统和不同的软件生成数据结构都会给海量数据融合带来困难,现有的研究仍然存在许多不足,而面对海量流式安全数据的集中或分布式存储,快速融合的手段对于态势精准分析则显得更为重要,需要更多地结合当下的大数据处理技术进行改进研究
(2)人工智能应用。现阶段人工智能技术已经渗透到各行各业,很多传统技术都已经在这一过程中得到了蜕变,人工智能在网络安全领域的应用也有其积极的一面。威胁识别系统已经在使用机器学习技术来识别新的威胁,而通过机器学习对未来态势的预测也将越来越准确、迅速和成熟。因而,借助人工智能技术提升网络安全态势感知每个环节的能力是研究领域的大趋势。
(3)语义解构。现有对于网络攻击源头的攻击意图识别方式,主要利用人工经验判断,带来的弊端显而易见,依赖于先验知识,存在经验主义误区等,利用机器学习对特征提取和攻击场景聚类,解构网络攻击发起者背后的模式和意图,对于态势感知的“从哪里来,到哪里去,要干什么”的逻辑闭环,具有十分重要的意义。
(4)物联网。随着“5G”成为互联网领域被谈及最多的名词之一,基于5G网络的运营模式和架构必然将会很快催生出来,在可预见的未来,会有数量庞大 的5G物联网设备直接连接至5G网络,这一趋势将使设备更容易遭到攻击,也提高了监控的难度,因此,通过海量物联网设备发起的DDOS攻击将是网络安全态势感知一个新的必须深入研究的难点。
(5)政策法规。随着个人及商业数据隐私保护被提及的频率越来越高,今后的网络安全态势感知在数据层面的获取必然更加需要政策法规的支持,而面对日益凸显的整体安全态势的感知需要,如何平衡好隐私和共享、商业利益和社会安全的关系,是从政策层面必须不断构建巩固的核心
业界产品
华为云5
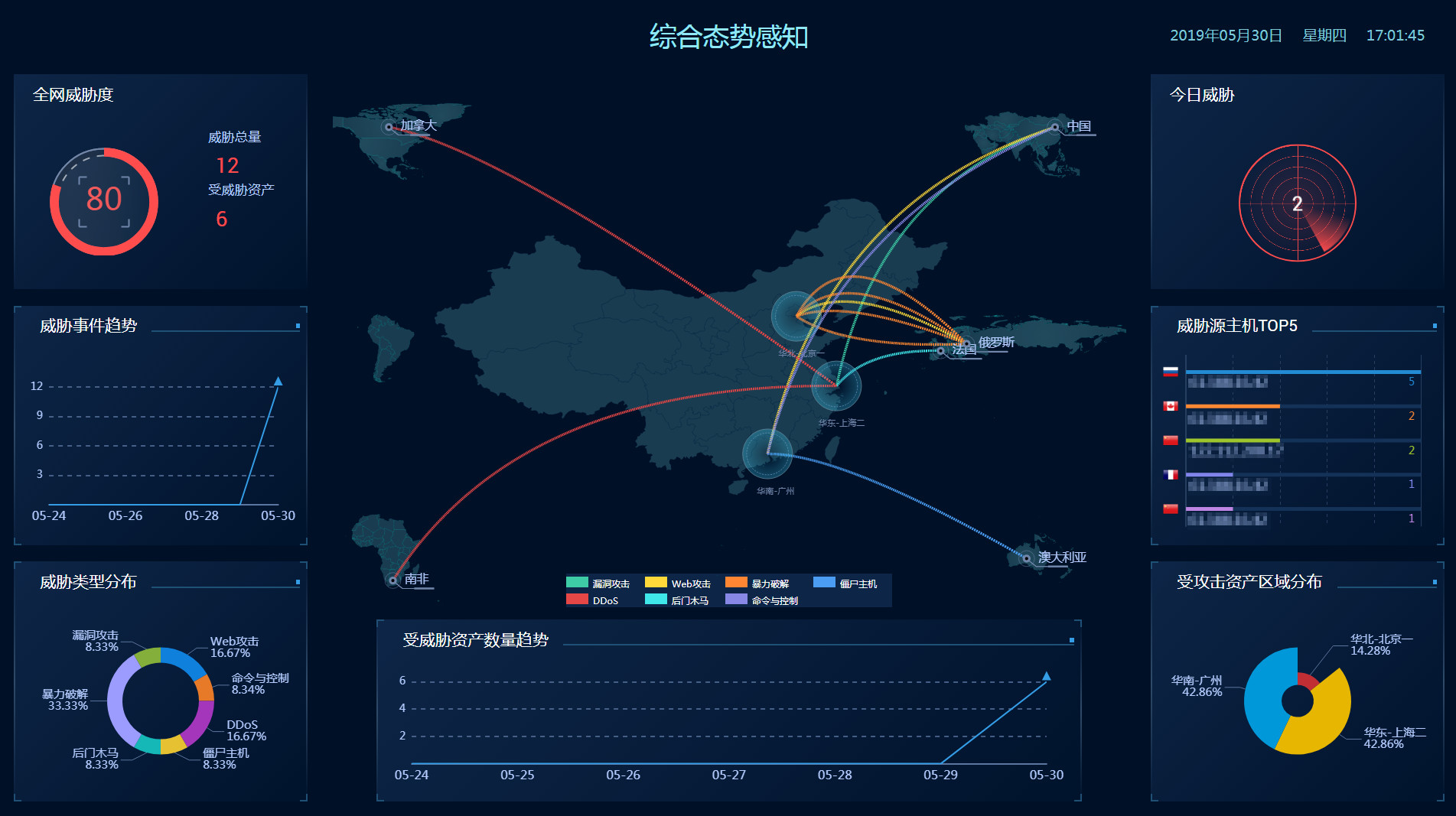
态势感知通过采集全网流量数据和安全防护设备日志信息,并利用大数据安全分析平台进行处理和分析,态势感知检测出威胁告警,同时将企业主机安全、Web防火墙和DDoS流量清洗等安全服务上报的告警数据进行汇合,实时为用户呈现完整的全网攻击态势,进而为安全事件的处置决策提供依据。
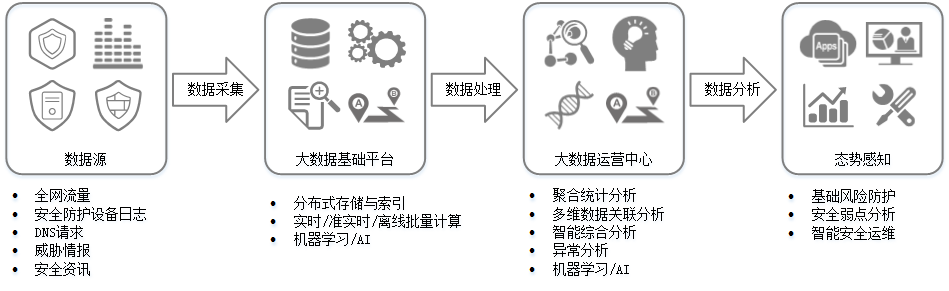
华为云的SA分为基础版和专业版两个版本。用户在注册华为云账号后,登陆SA管理控制台,即可免费体验基础版功能。其中专业版额外提供威胁检测、威胁分析、安全编排、主机漏洞扫描、网站漏洞扫描、应急漏洞、主机基线检查、云服务基线检查、告警设置、日志管理等功能。
计费模式:基础版(免费),专业版(¥150 / 台 / 月)
-
【精读】HOLMES:实时APT攻击检测
-
【精读】网络空间态势感知的态势预测研究
类型 内容 标题 Research on situation forecast of cyberspace situation awareness 时间 2016 会议 2016 Sixth International Conference on Instrumentation & Measurement, Computer, Communication and Control (IMCCC) 引用 Xin Z, Qiang L. Research on situation forecast of cyberspace situation awareness[C]//2016 Sixth International Conference on Instrumentation & Measurement, Computer, Communication and Control (IMCCC). IEEE, 2016: 140-144. DOI 10.1109/IMCCC.2016.47 原文链接:https://ieeexplore.ieee.org/document/7774753
读完感想
文章不长,没啥有用的东西
简介
标题
网络空间态势感知的态势预测研究
摘要
网络空间态势感知作为网络管理发展的必然趋势,能够融合多源信息和多属性信息,从而对整个网络的发展进行评估和预测。网络空间预测是网络态势感知的高级阶段,它可以帮助管理者预防和应对网络中可能出现的问题。本文阐述了网络空间态势感知的趋势预测技术,研究了态势预测的思想,明确了态势预测的实用性和重要趋势,总结了态势预测的发展和未来的研究方向 介绍为了保证网络的安全运行,必须实施有效的安全保护。计算机网络安全防护是防护、检测和响应的有机结合。安全防护手段包括资产识别、电子干扰测试、脆弱扫描、渗透测试、威胁检测、入侵检测、电子干扰测试、电磁波截止、辐射源定位技术等。主要问题如下:
1) 维度单一。安装防火墙、入侵防御等传统的单一维防御技术显得力不从心。网络安全管理者只使用一种或几种安全工具,这些工具很难处理复杂的安全问题,并且彼此之前存在很大的区别。因此,网络安全管理者很难选择一种适合其网络状况的安全工具。
2) 信息冗余。网络操作设备、安全防护设备和应用服务系统产生的大量冗余警报,使网络管理者关注于细节或大量重复信息,导致对网络安全事件缺乏宏观认识,且难以集中精力。 3) 整合困难。各类安全设备在网络中部署,独立运行。独立信息管理系统之间缺乏交互和集成形成了多个独立的“安全岛”,导致网络管理员无法了解网络当前的安全状况。网络中部署的安全设备越多,“安全岛”问题就越严重。态势感知的预测技术
网络空间态势感知的特征
与传统的网络管理系统相比,CSA具有以下特点:
1)数据融合技术的使用,综合考虑网络状况的影响因素,提供全面的宏观网络图,加深对网络的理解和控制,减轻了网络管理员的负担;
2)一个集成了网络管理平台的单位,对每个单位管理独立工作的局面进行了改善,实现信息共享并带来准确的分析结果;
3)为风险评估和决策提供支持,一旦态势感知完成,就可以根据情况自动生成决策。网络空间态势感知作为网络管理发展的必然方向,包括态势因素获取、态势理解和态势预测。整个态势感知过程如图1所示。态势预测作为网络空间态势感知的重要组成部分,能够在宏观上反应网络安全态势,通过对网络潜在的威胁做出及时有效的防御,达到提高网络安全水平的目的。态势预测是根据过去和现在的态势评估结果,预测未来某一时间点或某一时期网络整体或局部安全的发展趋势。

当前主要网络空间态势预测
基于态势评估的态势预测是网络空间态势发展的趋势。它作为网络空间态势感知的重要组成部分,网络管理员可以提高对网络状态的认知和理解,并通过它为威胁分析和网络规划提供决策支持。
态势预测可以通过分析数据与网络事件发生之间的内在联系,帮助管理员预测下一个时间段内可能出现的网络问题,从而提前进行预防和处理。 随着网络威胁的发展变化,可以根据实际情况预测网络的实际数据和历史数据。 网络管理员可以使用科学的理论,方法和各种经验知识来判断,推测,估计和分析这些数据将来可能发生的变化。 在网络空间态势感知中有很多多角度,多层次的预测方法和预测模型。 主要的预测模型包括:基于灰色理论的预测模型,基于灰色支持向量机的预测模型,灰色马尔可夫预测模型,基于BP神经网络的预测模型,基于RBF神经网络的预测模型和基于GA-BPNN的动态预测模型。网络空间预测模型
基于灰色理论的预测模型
在分析现状的基础上,根据未来形势的模糊性、随机性和不确定性的特点,提出了灰色理论预测模型。灰色系统理论是Deng Julong教授于1982年提出的,Deng Julong用GM(1,1)模型对灰色系统进行预测。灰色理论主要研究部分信息已知或部分信息未知的小行为样本,以不确定系统为研究对象。通过对已知信息的形成、发展和提取,达到对系统的正确认识和有效控制。
基于灰色支持向量机的预测模型
灰色马尔可夫预测模型
基于BP神经网络的预测模型
基于RBF神经网络的预测模型
基于GA-BPNN的动态预测模型
结论
本文从态势预测模型、预测和应用等方面,全面阐述了主流预测模型的思想和方法,深入研究了网络态势预测的相关技术,阐明了态势预测对网络管理的实用性和重要性。目前,虽然研究者在这方面做了大量的工作,但效果并不十分理想,还有许多问题需要进一步研究。它反映了以下几点: a)数据模型的建立相对简单。大多数趋势预测模型只在单一的预测模型中使用,很难摆脱单一模型的局限性;
b)不同的预测模型导致的差距较大。同一情况下,不同的预测模型是不同的,同一预测模型的预测精度也随着时间的变化而变化。
因此,下一步重点研究组合预测方法。组合预测法是建立各种不同的预测模型,然后通过对各种预测模型的结果进行加权和得到最终的预测结果。该模型的优点是可以利用不同的模型来考虑不同的因素,从而可以从不同的角度充分利用信息。总之,网络空间态势预测还需要长期、深入、细致的研究,才能更好地应用于网络安全领域。
-
【精读】实时加密勒索软件检测
类型 内容 标题 RWGuard: A Real-Time Detection System Against Cryptographic Ransomware 时间 2019 会议 International Symposium on Recent Advances in Intrusion Detection 引用 Mehnaz S, Mudgerikar A, Bertino E. Rwguard: A real-time detection system against cryptographic ransomware[C]//International Symposium on Research in Attacks, Intrusions, and Defenses. Springer, Cham, 2018: 114-136. 文章简介
RAID 2019.文章提出了一个关于加密勒索软件的实时检测系统RWGuard,它通过部署诱饵文件、监视进程、分析用户行为等方式对加密勒索软件进行了有效的检测。最后使用14个流行的加密勒索软件对该系统进行评估,假阴性率为0,假阳性为0.1%,并且只产生了1.9%的额外开销。
会议介绍
International Symposium on Research in Attacks, Intrusions and Defenses (攻击、入侵和防御研究国际研讨会),之前的名称为International Symposium on Recent Advances in Intrusion Detection (RAID),致力于在入侵检测领域共享信息。
作者介绍
Shagufta Mehnaz, Anand Mudgerikar,Elisa Bertino Purdue University,West Lafayette, IN, USA
摘要
勒索软件最近成为一种流行的恶意软件,其目标广泛,从个人用户到公司用户,都是为了金钱利益。现有勒索软件检测机制无法实时提供预警,这会导致大量文件的不可逆加密,而加密后的处理技术(例如,密钥提取,文件还原)则有很多的局限性。
现有的检测机制有较高的误报率且无法确定文件更改的原始意图,即它们无法区分文件变化是由于勒索软件加密还是由于用户对文件操作(例如正常加密或压缩)造成的。为了解决这些挑战,本文介绍了一种勒索软件检测机制RWGuard,它可以通过 (1)部署诱饵技术
(2)仔细监视正在运行的进程和文件系统中的恶意活动
(3)通过了解用户的加密行为,可以避免标记出正常的文件更改行为
我们对迄今为止14个最流行的勒索软件家族的样本进行了评估,实验表明RWGuard在实时检测时勒索软件时非常有效,假阴性率为0,假阳性率可以忽略不计(0.1%),同时只产生1.9%的开销。介绍
勒索软件是一类最近在网络犯罪中非常流行的恶意软件。这些网络罪犯的目标是通过劫持用户的文件来获取经济利益——要么加密文件,要么锁定用户的计算机。在本文中,我们将重点放在加密勒索软件上,它向用户索要赎金,以交换解密密钥,这些密钥可用于恢复攻击者加密的文件。这样一个勒索软件对个人和组织来说是一个重大的威胁。在最近的勒索软件攻击中,Petya是最致命的一个,它影响了好几家制药公司、银行和至少一个机场和一家美国医院。另一个席卷全球近100个国家的大规模勒索软件是WannaCry。这次袭击不仅针对大型机构,也针对个人用户。尽管自2005年以来勒索软件一直是最大的威胁之一,但第一次勒索软件攻击发生在1989年,目标是医疗保健行业。拥有非常敏感和关键信息的医疗行业仍然是首要目标。 即使已经提出了很多检测恶意软件的技术,但只要少数有关于勒索软件检测的技术,且这些现有技术具有以下限制:
(a)具有不可避险的延迟,当几个文件已经被加密时才能检测
(b)无法区分正常的文件更改与勒索软件加密
(c)离线检测系统无法实时检测勒索软件
(d)仅强调加密后阶段,该阶段大多数情况下无法恢复文件或与 安全的删除冲突
(e)安装后仅在有限的时间内监视应用程序的操作。问题和范围:在这项工作中,我们关注成功的勒索软件最关键的需求,即使用户无法获得有价值的资源(即文件、文档),并设计一个解决方案RWGuard,通过在早期阶段检测和停止勒索软件进程来保护文件。锁定用户机器的勒索软件系列不在本文的讨论范围内。
方法:RWGuard使用三种监视技术:诱饵监视,过程监视和文件更改监视。 与普通恶意软件不同,勒索软件能在几分钟(或几秒钟)内破坏系统。 因此,分析进程的文件使用模式并搜索类似勒索软件的行为会导致检测延迟。 为了应对这一挑战,我们从战略上在系统中部署了许多诱饵文件。 由于在正常情况下不应读写诱饵文件,因此,每当勒索软件进程读写该诱饵文件时,我们的诱饵监视技术便会立即识别出勒索软件进程。 尽管已经有一些研究工作使用诱饵文件来检测勒索软件,但先前的工作并未在任何实际系统设计中对这些诱饵文件的有效性进行分析。据我们所知,我们的工作首先对诱饵技术检测勒索进行了实证分析 。进程监视器检查运行中进程的I / O请求数据包(IRPs,I/O Request Packets),例如IRP写、创建、打开。尽管某些现有方法是基于签名的并且寻找特定的I / O请求模式,但我们利用勒索软件的快速加密属性,使用许多IRP指标为每个运行过程构建基线配置文件,并利用这些基线配置文件执行过程异常检测。文件更改监视器检查对文件执行的所有更改(例如,创建、删除和写入操作),以确定异常文件更改。从我们的实验观察中,我们发现仅监视过程活动或仅监视文件更改是不足以有效地检测恶意行为,并可能产生较高的假正率和假负率(例如,我们观察到Cryptolocker勒索软件对文件的加密非常慢,有时会逃避过程监控)。在本文中,我们将增强这些现有技术,并将其与诱饵监控模块结合起来,以提供有效的解决方案来防范勒索软件
如果发现了某一个文件(非诱饵文件)的潜在加密行为,则接下来是确定文件是由勒索软件还是由合法用户加密的。 因此,我们还设计了一种文件分类机制,该机制根据文件的属性将加密分类为良性或恶意。为了了解用户的文件加密行为,我们用现有的加密程序(它利用加密库CryptoAPI,例如Kryptel)供用户和应用程序使用。 最后,我们的方法使用了一种机制,该机制可以放置钩子并拦截对CryptoAPI库中的函数的调用,从而监视所有良性文件的加密
贡献:总而言之,RWGuard的贡献如下:
- 一种基于诱饵的勒索软件检测技术,能够实时识别运行中的勒索软件进程。
- 一个同时使用过程和文件更改监视的勒索软件监视系统(用于检测除诱饵以外的勒索软件加密文件)
- 一种分类机制,通过对CryptoAPI功能放置钩子并学习用户的文件加密行为,来区分良性文件更改和勒索软件加密
- 我们对该系统检测14个最流行的勒索软件的效果进行了广泛的评估
背景
混合密码系统
混合密码系统允许勒索软件使用不同的对称密钥和一个非对称密钥对不同的文件进行加密。 攻击者通过命令生成不对称的密钥对。 勒索软件代码为要加密的每个文件生成唯一的对称密钥,然后使用公钥对这些对称密钥进行加密。 这些加密的对称密钥与加密的文件一起保留。 用户需要支付赎金以获取私钥,使用私钥可以获取对称密钥,然后解密文件。IRPLogger 所有由进程发送到设备驱动程序的I/O请求都打包在I/O请求包(IRPs)中。这些请求是为所有文件系统的操作生成的(例如打开、关闭、写入、读取等),IRPLogger利用一个小的过滤器驱动程序来拦截I/O请求。IRPLogger条目的示例如下:
<Timestamp, PID, IRP/FastIO, Operation (READ/WRITE/OPEN/CLOSE/CREATE)>CryptoAPI CryptoAPI是Microsoft Windows平台特定的加密图形应用程序编程接口(API)。 这个API包含在Windows操作系统中,用于保护基于Windows的应用程序的服务。 它包括加密(CryptEncrypt)和解密(CryptDecrypt)数据,生成加密安全的伪随机数(CryptGenRandom),使用数字证书进行身份验证的功能。
微软Detours库 Detours库用于在与Windows兼容的处理器中检测任意Win32函数。它通过重新写入目标函数的内存代码来拦截Win32函数。Detours将未检测的目标函数(可通过蹦床调用???trampoline)作为子例程供检测使用。
RWGuard Design
3.1 威胁模型
在我们的威胁模型中,我们考虑攻击者通过看似合法但恶意的域在受害者机器上安装加密勒索软件。我们认为操作系统是可信的。勒索软件通常加密用户创建和关心的文件,且用户帐户已经拥有访问这些文件的所有权限。然而,尽管勒索软件仅以用户级权限执行的假设似乎是合理的(与其他假设一样,勒索软件可能能够击败主机保护机制中的任何现有机制,例如反恶意软件解决方案),但此假设并不适用于所有运行过的勒索软件情况。 我们观察到这种假设的一些例外情况,一些勒索软件仅影响预定义的文件列表,如果未检测到或被终止,则获取Root访问权限,然后关闭系统并在下次启动时执行完整磁盘加密并要求支付勒索金。因此,我们也将这些勒索软件样本包含在我们的威胁模型中。此外,组织内部的攻击人员可能会获得诱饵文件的知识,并构建一个定制的勒索软件来破坏组织(例如一个逻辑炸弹,在离职后触发)。
3.2 概览
图1显示了RWGuard的设计概述。首先,需要由I/O调度程序调度由任何用户空间进程生成的对文件系统的任何I/O请求。我们利用IRPLogger来获取这些系统范围的文件系统访问请求,并使用IRPParser解析这些请求, RWGuard包括五个模块: (1)诱饵监视(DMon)模块
(2)进程监视(PMon)模块
(3)文件更改监视(FCMon)模块
(4)文件分类(FCls)模块
(5)CryptoAPI函数钩子(CFHk)模块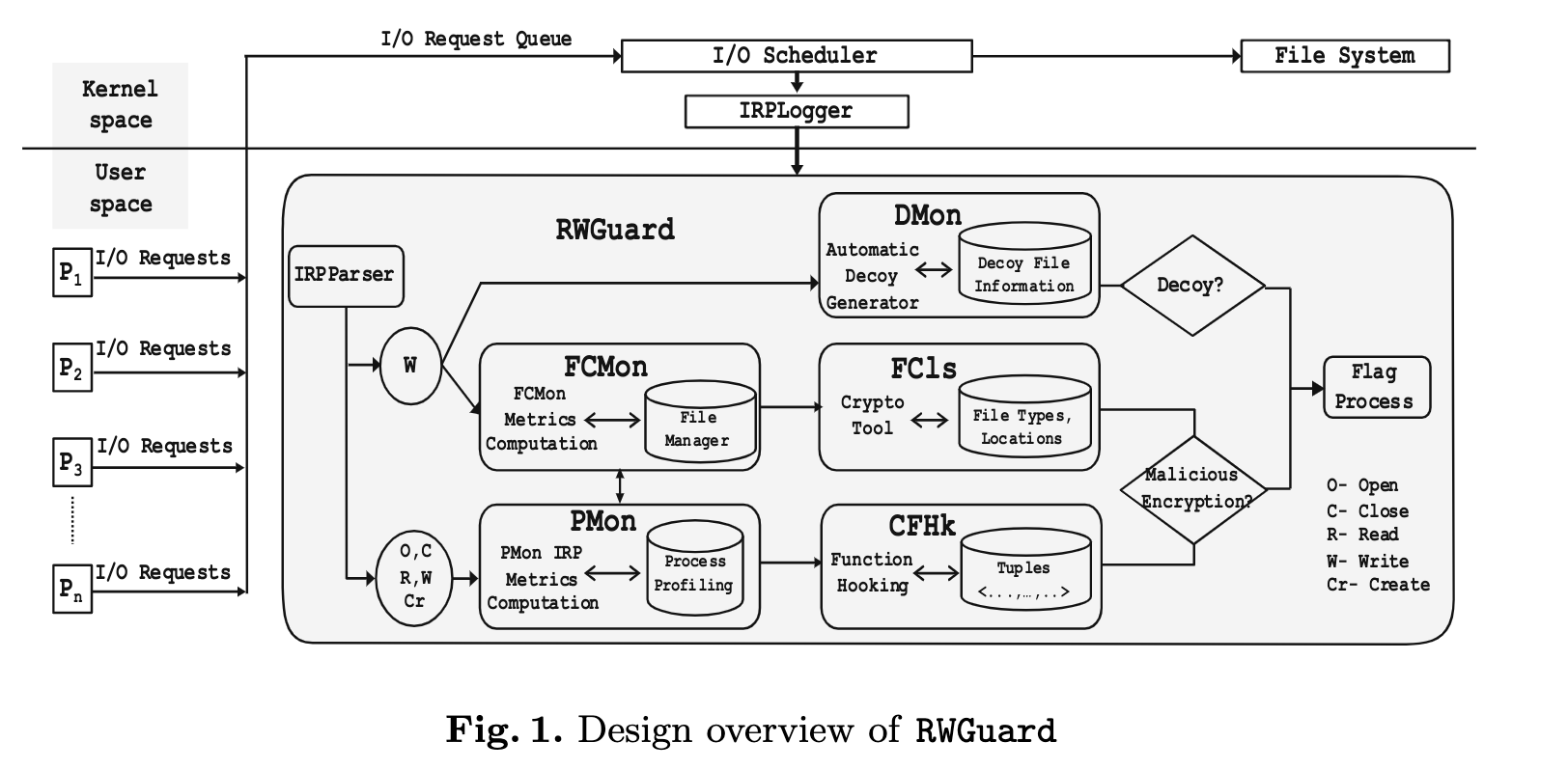 DMon模块仅将IRP写请求视为输入,并监视是否存在对诱饵文件的写请求。PMon和FCMon模块分别监视进程操作(IRP open、close、read、write、create)和文件更改(IRP write)。这两个模块互相通信以识别对文件进行重大异常更改的任何进程。如果识别出此类事件,FCls模块将检查文件的属性,并预测文件更改事件是正常的可能性。此外,CFHk模块还检查在文件发生重大更改时是否为此文件记录了良性加密。
DMon模块仅将IRP写请求视为输入,并监视是否存在对诱饵文件的写请求。PMon和FCMon模块分别监视进程操作(IRP open、close、read、write、create)和文件更改(IRP write)。这两个模块互相通信以识别对文件进行重大异常更改的任何进程。如果识别出此类事件,FCls模块将检查文件的属性,并预测文件更改事件是正常的可能性。此外,CFHk模块还检查在文件发生重大更改时是否为此文件记录了良性加密。3.3 诱饵监视(DMon)模块
DMon模块部署诱饵文件,使我们的系统能够实时识别运行的勒索软件进程。由于在正常情况下不应修改诱饵文件,因此每当(勒索软件)进程试图写入此类文件时,此模块可以立即将该进程标识为恶意。此外,大量诱饵文件(尽管体积较小)的存在增加了勒索软件甚至在试图加密原始文件之前加密其中一个文件的可能性。因此,使用诱饵文件的优点有两个:
(1)它允许检测系统容易地识别恶意进程
(2)它延迟了勒索软件开始加密原始文件的时间,从而为异常检测提供了足够的时间来完成其分析,并在恶意进程开始加密原始文件之前停止它们(关于RWGuard完成分析所需时间的实验数据,见第5.2节)。
RWGuard诱饵文件是用一个自动诱饵生成器工具生成的,我们将在第4.2节中详细讨论这个工具。注意,我们的诱饵生成器会定期修改诱饵文件,这样即使勒索软件查看最后一次修改文件的时间(以确保其加密的文件对用户有价值),它也无法识别诱饵文件。3.4 进程监控(PMon)模块
与某些现有方法在进程的I / O请求中使用特定模式(例如,读取→加密→删除)不同,我们利用勒索软件通常试图快速加密数据这一事实( 以最大程度地破坏并最大程度地减少被发现的机会),从而导致IRP数量异常。
利用此属性可以加快检测速度,因为IRP可以在实际的文件操作前进行记录。我们的PMon模块监控系统上运行的进程发出的I/O请求。尽管IRP是请求I/O操作的默认机制,但许多勒索软件使用快速I/O请求执行文件操作。快速I/O是专门为高速缓存文件上的快速同步I/O操作而设计的,它绕过了文件系统和存储驱动程序堆栈。 因此,在我们的设计中,我们同时监视IRP和快速I/O请求。快速I/O操作可以是表1中列出的任何类型。由于勒索软件进程对文件进行了快速加密,这些进程的行为具有一定的特征。因此,在这个模块中,我们训练一个机器学习模型,该模型给定进程的I/O请求,将进程标识为良性或勒索软件。缓慢加密文件的勒索软件可能会避开此模块,但可以由第3.5节所述由FCMon模块标识。进程分析 为了训练机器学习模型,第一步,我们收集了良性和勒索软件过程的IRP(这里的IRP同时表示I/O和快速I/O)。表2显示了这个训练阶段使用的IRP特征,其中还包括创建的临时文件的数量。临时文件(.TMP)通常由勒索软件创建,用于在复制或删除原始文件时保存数据。一旦在训练阶段建立了良性和勒索软件过程的概要文件,PMon模块的进程概要文件组件(图1)将存储模型参数,以实时检查运行进程的参数(即测试阶段)。PMon模块通过3s滑动窗口为每个运行的进程计算表2中列出的特征。
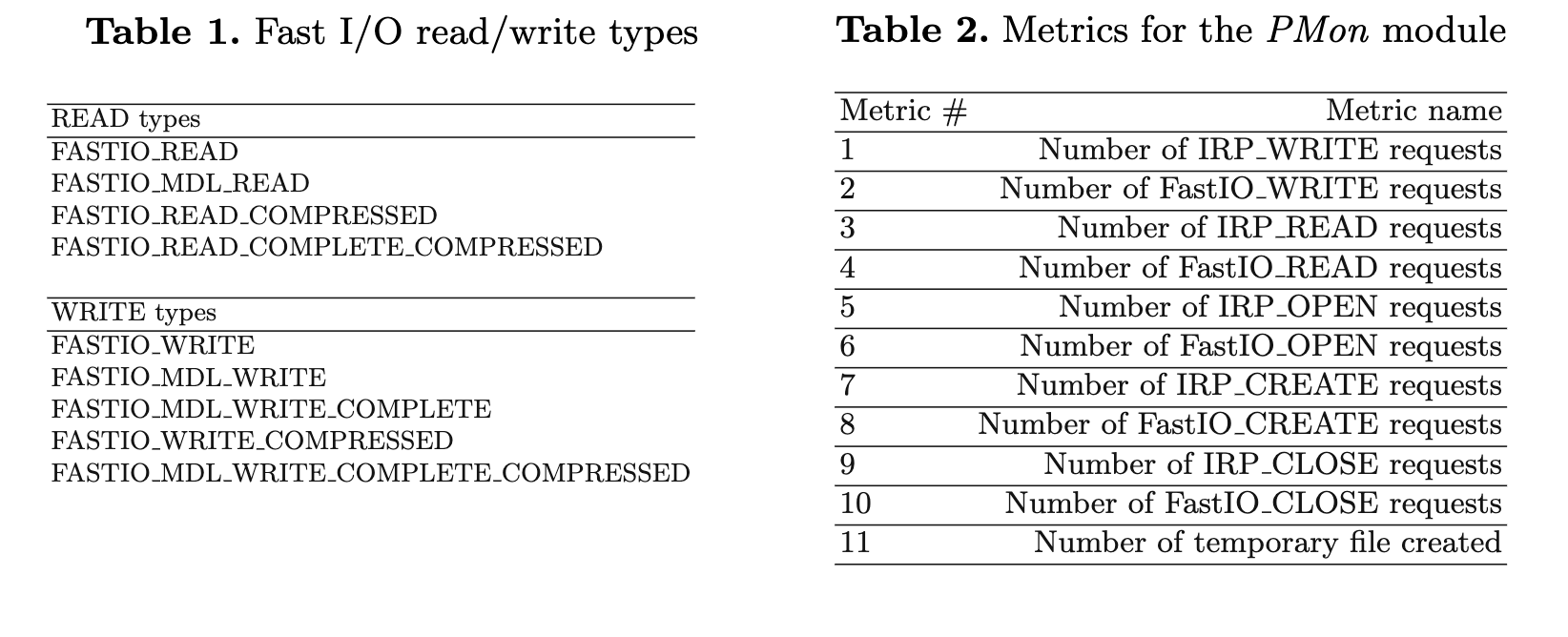
训练阶段:数据收集和分类器训练步骤如下:
1.数据收集:对于训练集,我们从勒索软件样本和良性应用程序中收集进程的IRP数据。我们使用九个最受欢迎的勒索软件家族,即:Wannacry, Cerber, CryptoLocker, Petya, Mamba, TeslaCrypt, CryptoWall, Locky, 和Jigsaw的IRP数据用于训练。良性进程包括如Explorer.exe、WmiPrvSE.exe、svchost.exe、FileSpy.exe、vmtoolsd.exe、csrss.exe、System、SearchFilter-Host.exe、SearchProtocolHost.exe、SearchIndexer.exe、chrome.exe、GoogleUp-date.exe、services.exe、audiodg.exe、WinRAR.exe、taskhost.exe、drpbx.exe、lsass.exe.值得注意的是,大多数勒索软件在执行过程中会产生多个恶意进程。我们最终的训练数据集包含261个进程(良性和恶意)的IRP。
2.训练分类器:利用训练数据,我们训练了一个机器学习分类器,该分类器在给定一组进程的情况下,能够区分勒索软件进程和良性进程。为了确定最佳的分类器,我们对不同的机器学习算法进行了分析即:朴素贝叶斯(使用估计类)、logistic回归(带岭估计的多项式logistic回归模型)、决策树和随机森林。我们对所获得的数据集进行了10折交叉验证,并对上述每个分类器的准确度、精确度、召回率、真阳性率和假阳性率进行了测量。
表3给出了分析中使用的分类器的比较
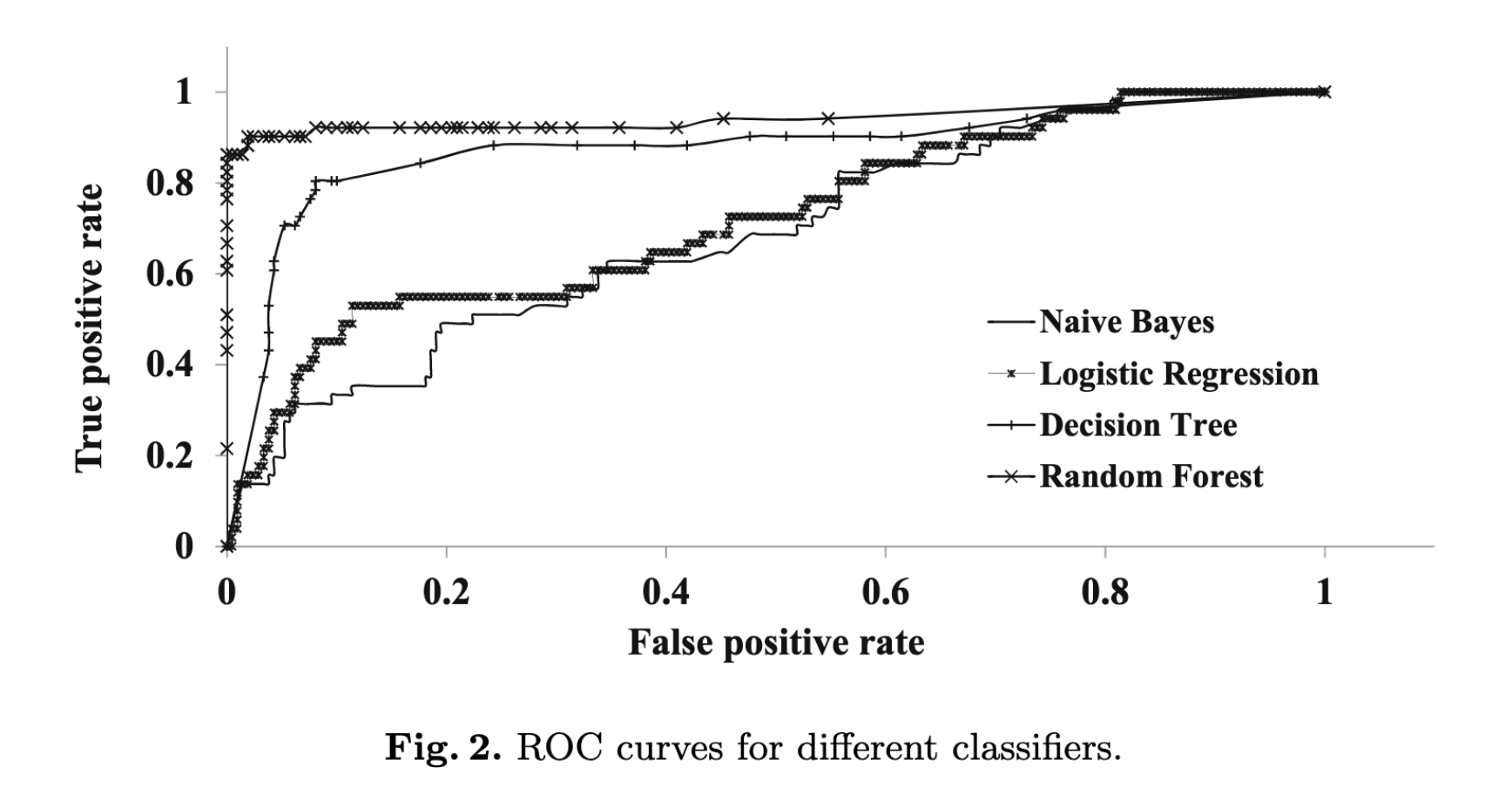
图2显示了所有分类器的ROC曲线结果(绘制了真实阳性率与阴性阳性率)
朴素贝叶斯分类器的低准确性(〜80%)可以归因于其条件独立性。勒索软件通常采用读,写,打开和关闭请求的组合,因此假设这些参数彼此独立会导致较低的精度。 回归分类器比朴素的贝叶斯分类器稍好一些,准确度约为81%。逻辑回归模型在特征空间中搜索以个线性决策边界。因此,较低的准确度可归因于我们的数据没有决策的线性边界这一事实。原因:与打开/关闭请求相比,许多勒索软件发出了大量的写/读请求。 因此我们的数据集的理想决策边界将是非线性的。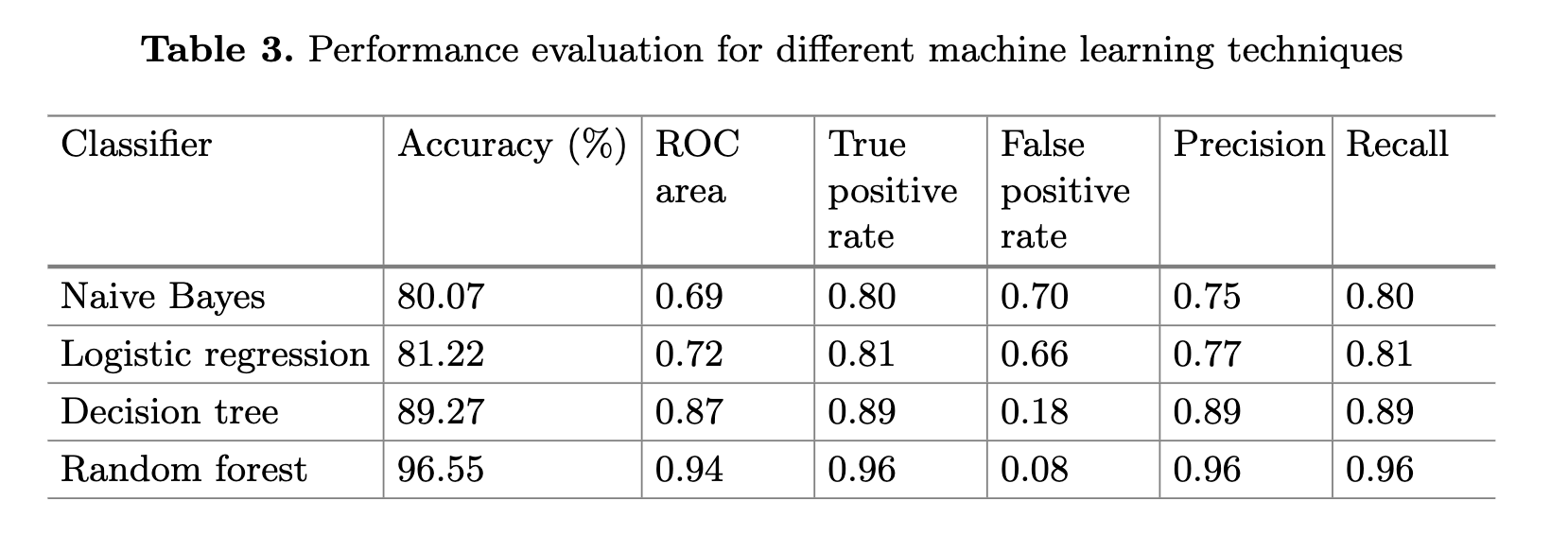
测试阶段:在测试阶段,除了训练用的9个勒索软件家族,我们在实验集中添加了另外5个勒索软件家族:Vipasana,Satana,Ramamant,Rex和Matsnu。 这些样本一次执行一个,并根据生成的进程及其活动来标记恶意进程。 测试阶段结果的详细信息在第五节中给出
文件加密。在我们的实验中,我们发现很有少数良性进程(例如Chrome,VMware工具)由于I / O行为而被模型分类为恶意程序。 因此,除了监视进程分析指标外,监视特定进程是否负责任何重要的文件更改也很重要。 因此,我们的PMon模块将文件加密视为重要参数(如第3.5节中所述,与FCMon模块进行通信),并且仅在对文件进行加密以及带有异常I / O行为的迹象时,才将进程识别为恶意。
3.5 文件更改监视(FCMon)模块
此监视模块可以配置为针对从单个目录到整个文件系统的一系列文件。它计算并存储文件的初始属性(或在创建文件时动态计算属性),这些属性在文件更改时会相应地更新。在实时性方面,FCMon模块在每次写操作之后使用以下度量来查找这些文件中的显著更改: (1)相似性(2)熵(3)文件类型更改(4)文件大小更改。
虽然这些度量中的一些已经在现有的工作中被用于勒索软件检测,我们的目标是验证PMon模块的快速检测,从而最小化假阳性率。在下面的内容中,我们描述了FCMon模块的文件管理器组件,并给出了上述度量的详细信息。
文件管理器。此组件存储每个文件的当前属性(例如,文件类型、文件的熵、文件大小、最近修改时间等),以便在写入操作时检测到文件属性的任何重大更改。如果创建了新文件,此组件将立即计算新文件的属性并将其存储在映射中(键:文件名和路径,值:计算属性)。
指标 FCMon模块的度量如下:
-
相似性度量:与良性文件更改(例如,修改一些现有文本或添加一些文本)相比,加密将导致与原始数据非常不同的数据。因此,文件先前(写操作之前)和之后(写操作之后)版本之间的相似性是理解文件更改特征的重要因素。为了计算两个版本之间的相似度,我们使用了由Roussev等人提出的一个保持相似度的hash函数sdhash用于生成文件哈希。sdhash函数输出0-100范围内的分数。当我们计算两个完全随机的数据数组之间的相似性时,得到0分。相反,当我们计算两个完全相同的文件之间的相似性时,会得到100分。因此在加密的情况下,此函数会输出接近0的值。
-
熵度量:熵,与数字信息有关,是对一组给定值(数据)中的随机性的度量,即在文件上计算时,它提供有关文件中数据随机性的信息。 因,可以肯定,用户的纯文本格式的数据文件具有较低的熵,而其加密版本将具有较高的熵。 与加密数据相比,压缩数据与其纯文本格式相比还具有较高的熵。
广泛使用的熵计算技术是香农熵。N字节数组(假设ASCII字符的值从0到255)的Shannon熵可以用如下公式计算:$\sum_{i=0}^{255}P_i\log_2 {1\over {P_i}}$。 $P_i$在这里是从数组中随机选择的字节是i的概率,例如$P_i = {F_i \over N}$,$F_i$是字节i在数组中出现的频率。这个方程的返回值在0-8范围内,价值数组中字节值是均匀分布的,则输出值为8。由于加密文件的字节分布更均匀(与明文版本相比),加密后的香农熵会显著增加,结果接近8
-
文件类型更改度量:文件在存在期间通常不会更改其类型。然而,勒索软件家族在加密后更改文件类型是很常见的。因此每当写入文件时,我们都会比较写入操作前后的文件类型。
-
文件大小更改度量:与文件类型更改不同,文件大小更改是一个常见事件,例如,向文档添加大文本。但是,此度量和其他度量一起采用时可以确定文件更改是良性的还是恶意的。
在检测到导致文件类型更改或文件更改超过指标的给定阈值:
相似性得分<50,熵值> 6,显着改变了文件大小
FCMon模块将与PMon,FCls和dCFHk模块共享记录的指标,以进行进一步评估。
3.6 文件分类(FCls)模块
在PMon和FCMon模块协同识别出对异常的I/O行为和文件更改负责的进程之后,我们的检测系统会对文件是被勒索软件加密的还是由于良性操作而导致的更改进行分类。我们的FCls模块通过学习crypto工具(一个利用CryptoAPI的实用程序,用于用户敏感文件的加密和解密,例如Krypte)的用法并分析用户的加密行为来执行此分类。例如,如果一个文件是从同一个目录中加密的,并且具有与以前有益的加密文件相同类型的文件,则此模块会认为此文件是良性加密的概率比较高(但是勒索软件不能滥用这一思想,见第3.7节CFHk模块)。如果一个文件属于良性加密的概率太低,并且已经被被加密,FCls模块会立即发出一个标志。为了消除假阴性的误报(即勒索软件对具有良性加密可能性的文件进行加密),将使用CFHk模块验证加密信息,该模块拦截良性加密。
保护敏感文件:如果在勒索软件攻击时敏感文件已经加密,勒索软件可以进一步加密这些文件,使这些文件不可用。请注意,FCMon模块可能无法以高概率标记此事件。原因是熵不会发生显著变化,因为两个文件版本(勒索软件加密之前和之后)的熵都很高。为了解决这个问题,我们修改加密文件的权限设置,即当用户使用加密工具加密文件时,我们仅允许对加密文件进行解密和删除(每个操作都需要用于加密的对称密钥),因为在解密前编辑/修改加密文件是不切实际的
3.7 CryptoAPI函数钩子(CFHk)模块
如第3.6节所述,如果FCls模块将更改归类为可能是良性加密的结果之后,我们需要进一步研究是否是使用加密工具执行的加密。 因此,CFHk模块将钩子放在CryptoAPI库函数的开头,以将执行控制重定向到我们自定义编写的函数。图3显示了在CryptoAPI库中勾住CryptEncrypt功能的示例。 每当进程调用CryptEncrypt函数对某些文件进行加密时,放在CryptEncrypt函数的钩子都会将控制转移到影子CryptEncrypt函数中。 该影子CryptEncrypt函数为该特定调用提取一个元组<key,algo,file,timestamp,process>,并出于安全目的以加密形式存储此信息,以便其他进程无法访问它。 用于此加密的密钥来自用户设置的秘密密码。 一旦存储了元组,影子CryptEncrypt函数就将控制权返回到原始过程,并且该进程继续执行,就好像它根本没有被中断一样。 该挂钩过程的实现细节在第4.3节中讨论。
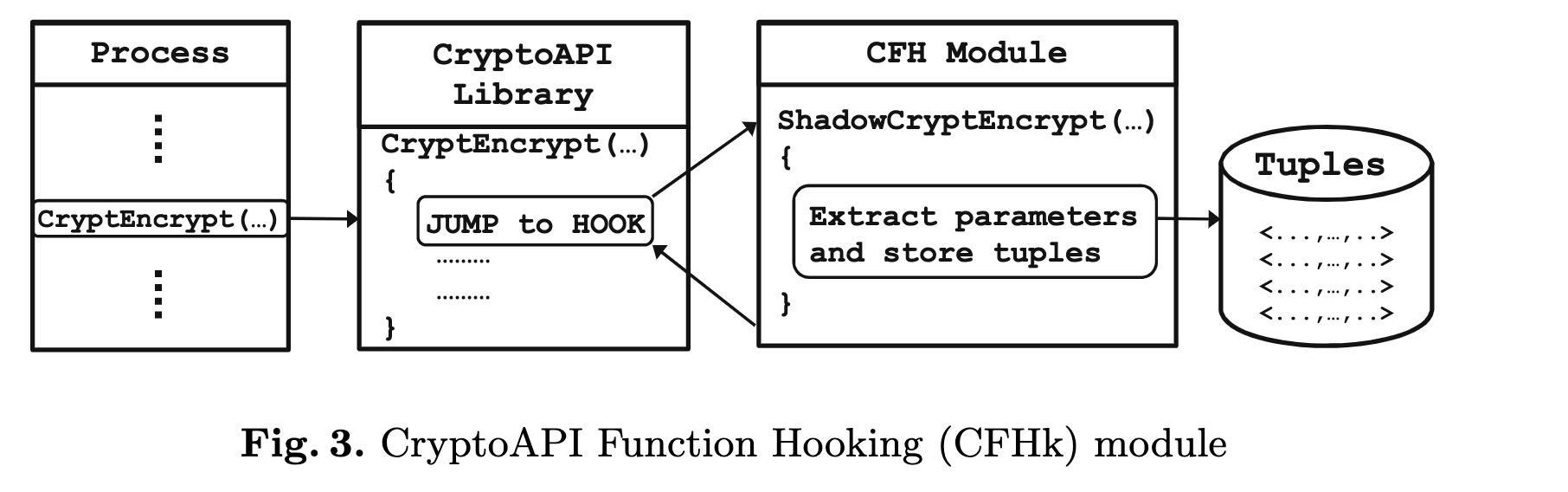 为了确定是否使用加密工具执行文件加密,我们只需搜索由CFHk模块捕获的“CryptEncrypt”元组。
为了确定是否使用加密工具执行文件加密,我们只需搜索由CFHk模块捕获的“CryptEncrypt”元组。- 如果找不到这样的元组,我们将终止修改文件的进程,以便不再进行加密。
- 如果找到这样的元组,则加密是良性的(不需要任何操作),或者勒索软件使用CryptoAPI加密。在第二种情况下,我们可以使用元组中的密钥和算法信息来恢复所有文件(详见第5.4节)。因为在我们的系统中,我们还存储文件信息(通过将ReadFile调用与CryptEncrypt相关联),所以我们不需要遍历所有密钥来进行单个文件解密,这是对现有工作的改进[16]。
因此,钩住CryptoAPI库函数的好处有两个:(1)跟踪用户的所有良性加密;(2)在勒索软件使用系统提供的加密库的情况下,恢复加密文件(例如Windows CryptoAPI)。
4 RWGuard实现
4.1 IRP解析器
当IRPLogger记录I/O请求时,IRPParser组件解析日志条目,提取I/O请求,并输入给DMon、PMon和FCMon模块。
4.2 诱饵文件生成器
我们设计了一个自动诱饵文件生成器工具,它根据原始文件系统和用户偏好生成诱饵文件。默认情况下在每个目录中,它都会生成一个诱饵文件。 其名称类似于同一目录中的一个原始文件(根据用户偏好随机选择或由用户选择),这样诱饵文件的名称对勒索软件来说就不会是随机的。 为了确保用户能够很容易地识别诱饵文件,根据用户的偏好选择命名选项,这也使得诱饵文件对于勒索软件来说更加不可预测。用户可以为不同的目录设置不同数量的诱饵文件。这样,更敏感的文件可以用一组更大的诱饵文件来保护,而且,手动设置数字可以让用户在正常操作期间更容易识别诱饵文件。 生成的诱饵文件的类型扩展名为
.txt,.doc,.pdf,.ppt和.xls,文件的内容是从相邻文件的内容生成的。尽管我们没有观察到任何勒索软件中有选择性行为(例如,在加密前检查文件名、文件内容等),但我们的诱饵设计对未来的高级勒索软件是有弹性的。 我们系统中的诱饵文件的大小是根据原始文件系统中文件的大小从一个范围(通常从1kb到几MBs)随机抽取的,而诱饵文件的总空间开销限制为原始文件系统大小的5%。
-
【精读】IDS综述
类型 内容 标题 A Detailed Investigation and Analysis of using Machine Learning Techniques for Intrusion Detection 时间 2018 会议 2018 IEEE Communications Surveys & Tutorials 引用 Mishra P, Varadharajan V, Tupakula U, et al. A detailed investigation and analysis of using machine learning techniques for intrusion detection[J]. IEEE Communications Surveys & Tutorials, 2018, 21(1): 686-728. 本文是一篇来自2018年S&T的关于IDS的综述。
I. 介绍
随着科技的发展,黑客事件日益增多。公司每年都会报告大量的黑客事件。2007年,俄罗斯对爱沙尼亚网站发起分布式拒绝服务(DDoS)攻击。2008年6月17日,Amazon[2]开始从其一个位置的多个用户接收一些经过身份验证的请求。请求开始显著增加,导致服务器速度减慢。2013年1月,欧洲网络和信息安全局(ENISA)报告说,Dropbox受到DDoS攻击,并在超过15小时的时间内遭受严重服务损失,影响到全球所有用户。2014年9月28日,Facebook遭到疑似DDos攻击。Panjwani等人报告在50%的网络系统攻击前会有网络扫描活动。攻击者不仅发起了泛洪和探测攻击,而且还以病毒、蠕虫、垃圾邮件的形式传播恶意软件文件,以利用现有软件中存在的漏洞,对存储在计算机上的用户敏感信息造成威胁。
思科年度安全报告提到与波士顿马拉松爆炸案有关的垃圾邮件占2013年4月17日全球所有垃圾邮件的40%。在思科最近于2017年进行的一项调查中,特洛伊木马被列为五大恶意软件之一,用于获得用户计算机和组织网络的初始访问权限。因此,在这样一个复杂的技术环境中,安全是一个巨大的挑战,需要智能地加以解决。
研究人员考虑了另一种入侵检测攻击类型。例如,基于KDD’99数据集的DoS(Denial of Service)攻击、扫描攻击(Probe)和R2L(Remote to Local)攻击以及U2R(User to Root)攻击。最近的一个攻击数据集(UNSW-NB1)将攻击分为九类:模糊攻击、分析攻击、侦察攻击、ShellCode、Worm、一般攻击、Dos、Exploit and Generic。第三节详细讨论了所有这些攻击。
目前的安全解决方案包括使用防火墙、杀毒软件和入侵检测系统(IDS)等middle-box。防火墙根据源地址或目标地址控制进入或离开网络的流量,它根据防火墙规则控制流量。防火墙受限于可用状态的数量及其对网络中主机的了解。IDS是一种安全工具,它监视网络流量,扫描系统中的可疑活动,并向系统或网络管理员发出警报。这是本文关注的主要焦点。
入侵检测系统主要有两种类型:基于主机的入侵检测系统和基于网络的入侵检测系统。基于主机的入侵检测系统(HIDS,Host based Intrusion Detection System)监视单个主机或设备,并在检测到可疑活动(如修改或删除系统文件,错误的系统调用,配置的意外更改)时向用户发送警报。基于网络的入侵检测系统(NIDS,Network based Intrusion Detection System)通常放置在网关和路由器上,以检查网络流量中是否存在入侵。
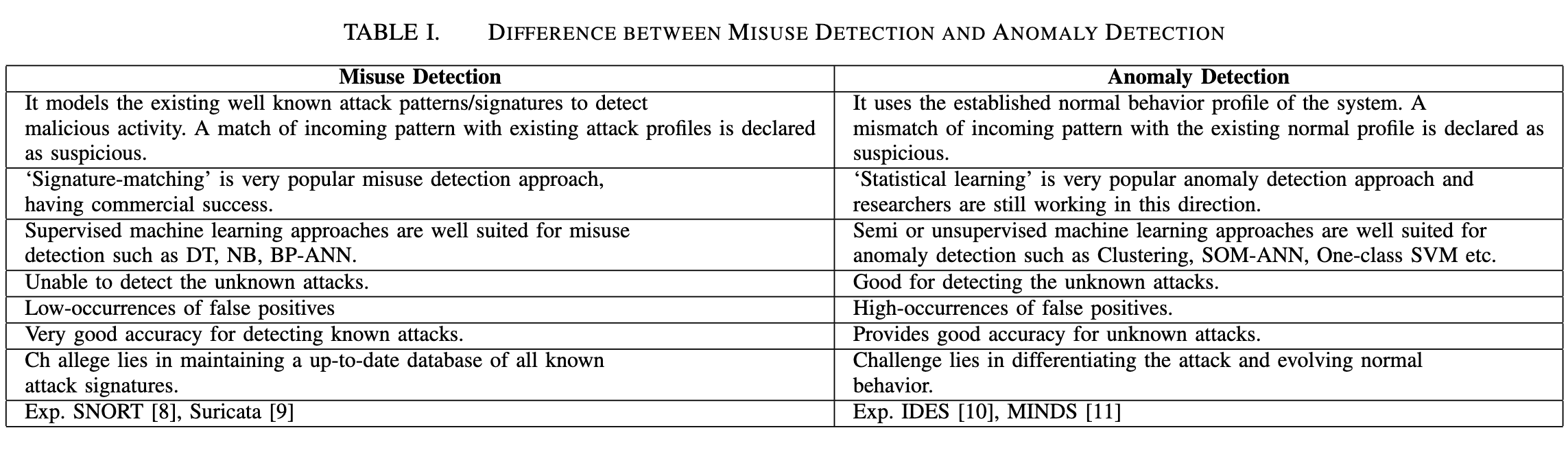
从高层次上讲,这些IDS使用的检测机制分为三种类型:误用检测,异常检测和混合检测。 在误用检测方法中,IDS维护一组知识库(规则)以检测已知的攻击类型。误用检测技术可大致分为基于知识库的技术和基于机器学习的技术。在基于知识库的技术中,将网络流量或主机审计数据(如系统调用跟踪)与预定义的规则或攻击模式进行比较。基于知识库的技术可分为三类:(i)特征匹配(ii)状态转移分析和(iii)基于规则的专家系统2。
基于特征匹配的误用检测技术根据固定模式扫描数据包。如果任何模式与数据包头匹配,则该数据包被标记为异常。基于状态转移分析的方法针对已知的可疑模式维护系统的状态转移模型。模型的不同分支导致机器的最终受损状态。基于规则的专家系统为不同的入侵场景维护规则数据库。基于知识库的入侵检测系统需要动态地对知识库进行定期维护,并且无法检测到攻击的变体。误用检测也可以使用有监督的机器学习算法,如反向传播人工神经网络(BP-ANN)、决策树 C4.5和多类支持向量机(SVM)。
基于机器学习的IDS提供了一个可以基于学习到的正常行为和攻击行为来判断攻击类别的系统。基于机器学习的IDS(有监督的)的目标是生成已知攻击的一般表示。误用检测技术无法检测未知攻击,但可以准确的检测已知攻击。这种类型的IDS还需要对特征数据库进行定期维护,这增加了人工成本。
基于误用检测的IDS特别是基于特征匹配的IDS非常受欢迎,并获得了商业成功。 与这些方法相关的优缺点如表I所示。这些IDS维护着一个已知攻击特征的数据库。 它可以采用代码,系统调用模式序列或行为配置文件等形式来表示,IDS以某种格式存储攻击特征。 我们使用TCP-ping攻击来说明基于特征的滥用检测系统(特别是SNORT)。如果攻击者想知道计算机是否处于活动状态,他会扫描该计算机。 攻击者发送ICMP ping数据包。 如果计算机设置为不响应ICMP ECHO REQUEST ping数据包,则攻击者可以使用nmap工具将TCP ping数据包发送到端口80,并将ACK标志设置为序号0。此攻击的特征在于标志设置为’A’值,并设置确认值为03。 因为这样的数据包在受害方是不可接受的; 收到封包后,如果RST数据包会发送到攻击者的计算机,则表明计算机还处于运行状态。 例如针对IP为192.168.1.0/24网络中的计算机,检测TCP ping攻击的规则如下:
alert TCP any any ->192.168.1.0/24 any,(flags: A;ack: 0; msg: ”TCP ping detected”;)基于特征匹配的IDS的主要限制是需要定期更新系统以添加规则。它对于未定义规则的新攻击会生成很多假警报。所以,异常检测方法也被用来检测入侵。
基于异常检测的IDS基于以下假设:攻击者的行为与正常用户的行为不同4。 它有助于检测不断发展的攻击。 基于异常检测的IDS对系统的正常行为进行建模,并不断对其进行更新。 例如,每个网络连接由一组特征值来标识(例如协议,服务,登录尝试次数,每个流的数据包,每个流的字节,源地址,目标地址,源端口,目标端口等)。 这些特征值的行为统计信息会在一段时间内被记录。 对于流中特征值中的异常偏差都将被异常检测引擎标记为异常。 异常检测技术大致分为三类:统计技术,基于机器学习的技术和基于有限状态机(FSM)的技术。 有限状态机(FSM)会生成一个由状态,转移和动作组成的行为模型。 Kumar等人提出了一种IDS,它利用隐马尔可夫模型对较长时间范围内的用户行为进行建模5。异常检测也可以使用半监督和非监督机器学习算法,如自组织映射(SOM,Self Organizing Map)神经网络,聚类算法和一类支持向量机(SVM)。基于异常检测的且基于机器学习的IDS提供了一个系统来发现零日攻击。 但是由于这些技术在区分攻击行为和正常行为方面的存在局限性,所以有较高的误报率。 表I显示了误用检测和异常检测方法之间的区别。
混合检测方法将误用和异常检测方法集成在一起以检测攻击。 第五部分介绍了这些方法的详细信息。通常,与传统的基于特征的IDS相比,使用基于机器学习的IDS的一些优势如下:
- 在攻击模式中进行一些细微的改变,可以很容易的绕过基于特征的IDS,而基于监督学习的IDS可以在学习流量的行为时,可以轻松检测到攻击行为的变化。
- 在基于机器学习的IDS中,CPU负载相对较低,因为它们不像基于特征的IDS那样分析特征数据库中的所有特征。
- 一些基于机器学习的IDS,尤其是基于无监督学习算法的IDS,可以检测到新颖的攻击。
- 不同类型的攻击不断发展。 基于特征的IDS将需要不时维护特征数据库并保持其最新,而基于聚类和离群点检测的机器学习IDS系统则不需要更新。
我们的贡献如下:
- 介绍了基于攻击特征的攻击分类。 讨论了机器学习技术难以检测低频攻击(如U2R和R2L,蠕虫,ShellCode等)的各种因素,并提出了提高检测率的方法。
- 对现有的入侵检测文献进行了讨论,重点介绍了关键特征、检测机制、特征选择、攻击检测能力。
- 分析了各种入侵检测技术在攻击检测能力方面的性能,还讨论了局限性及与其它方法的比较。并对每一种技术都提供了改进的建议。
- 为基于机器学习的入侵检测应用程序提供了未来的方向。
论文分为十一个部分。在第二节中与相关的调查进行比较,突出我们工作方面的具体贡献。第三节详细描述了不同类型的攻击及其特点。第四节介绍了各种机器学习技术及其特点,讨论了特征选择在机器学习中的重要性。第五节对不同的入侵检测机器学习方法进行了详细而全面的总结,第六节根据它们检测攻击的能力对它们进行了分类。第七节讨论了几种用于检测不同安全攻击的机器学习技术的性能分析。讨论了与各类机器学习技术相关的安全问题,并提出了解决方案。第八节描述了检测低频攻击时的问题,随后介绍了提高其检测率的各种有效措施。第九节讨论了用于机器学习和深度学习的各种数据挖掘工具。在第十节中,提供了未来的方向,以便对正在进行的和未来的研究工作进行简要的了解。最后,在第十一节中,提出了总结意见和今后的工作范围。
III. 具有相关攻击特征的攻击分类
-
N. Moustafa and J. Slay, “Unsw-nb15: A comprehensive data set for network intrusion detection systems (unsw-nb15 network data set),”in Military Communications and Information Systems Conference (MilCIS), Canberra, Australia, 2015, pp. 1–6. ↩
-
A.-S. K. Pathan, The State of the Art in Intrusion Prevention and Detection. CRC Press, 2014. ↩
-
S. Kumar, “Survey of current network intrusion detection techniques,” Washington Univ. in St. Louis, pp. 1–18, 2007. ↩
-
M. Ahmed, A. N. Mahmood, and J. Hu, “A survey of network anomaly detection techniques,”Journal of Network and Computer Applications, vol. 60, pp. 19–31, 2016. ↩
-
P. Kumar, N. Nitin, V. Sehgal, K. Shah, S. S. P. Shukla, and D. S.Chauhan, “A novel approach for security in cloud computing using hidden markov model and clustering,” in World Congress on Infor-mation and Communication Technologies (WICT). IEEE, 2011, pp. 810–815. ↩
-
使用MBR分区安装Windows 7
分区格式分为MBR分区和GPT分区,笔记本电脑默认是BIOS+MBR分区的引导模式,重装系统后可能变为UEFI+GPT分区的引导。MBR分区的缺点是不能管理超过2T的硬盘,且只支持四个主分区,而GPT可以管理18EB的硬盘。
在win 8以后好像都是用的UEFI+GPT的引导,我的旧电脑出厂就是win 8,最近有需求装成win7,我使用的方法几乎和装win 8 一样:在legacy模式下进入PE,装完后再切换成UEFI才能进系统。但这样出现了一个问题就是无法用软件激活win 7,提示是无法在GPT分区下激活系统。
使用DiskGenious的时候,右键选中硬盘就有转换成MBR分区表的功能,但点击后会提示试用版不能用此功能,需要去下标准版,但实际上使用命令行就可以实现这个功能。
diskpart list disk select disk 0 #即第一个硬盘 clean #清除这个硬盘,变成没有格式化的样子 convert mbr create partition primary size = xxx # 创建主分区大小(MB) format fs=ntfs quick # 格式化磁盘为ntfs格式这样子就变成MBR分区了