最新日志
-
Curator-集群存储管理系统-中文翻译
Curator: Self-Managing Storage for Enterprise Clusters翻译
Curator:企业集群的自我管理存储系统
摘要
现代集群存储系统执行一系列的后台任务,以提高数据存储的性能、可用性、持久性和成本效益。例如,清理器压缩碎片数据来
生成长时间连续的运行,分层服务根据使用情况自动在固态硬盘和机械硬盘之间迁移数据,数据恢复机制提前备份数据以提高故障时的可用性和耐用性,成本节省技术通过执行数据转换来降低存储成本。在这项工作中,我们提出了Curator,这是在企业集群中使用的分布式存储系统的背景下用于集群管理任务的MapReduce后台执行框架。我们描述了Curator的设计和实现,并使用一些相关指标来评估其性能。我们进一步报告了在其五年建设期间的经验和教训,以及数以千计的客户部署。最后,我们提出了一个基于机器学习的模型,针对Curator的管理任务确定有效的执行策略,以适应不同的工作负载特征。
1.介绍
当今的集群存储系统为了满足企业集群的需求,会拥有各种功能。 例如它们提供自动备份和数据恢复以处理故障,支持扩展,并提供固态开盘和机械硬盘的无缝集成。 此外,它们通过快照和垃圾回收等机制支持适用于虚拟机的存储工作,并执行例如数据去重,压缩,擦除编码等节省空间的转换。
对这些任务仔细检查后发现许多功能可以在后台执行。 基于此结果,我们设计并实现了一个用于在企业集群存储中的后台自我管理层。 作为这项工作的一部分,我们解决了重新组合这样一个系统所面临的一系列工程和技术挑战。首先,我们需要一个可扩展、灵活的、可伸缩的框架来执行一系列的任务来维护存储系统的运行状况和性能。为此,我们借用了通常在不同领域中使用的大数据分析技术,构建了由两个主要组件组成的通用系统:
- Curator,一个用于集群管理任务的后台执行框架,其中所有任务都可以表示为对相应数据的MapReduce式操作
- 一个在多处备份且保持一致的key-value存储系统,用于维护存储系统中所有重要的元数据。
其次,我们需要在后台任务和前台任务之间进行适当的同步。 我们通过让后台守护程序充当存储系统的客户端来解决了这些同步问题,然后让后来者处理所有同步。 第三,要求对前台任务的干扰最小。 我们通过使用任务优先级和调度启发式方法来最大程度地减少开销和干扰,从而完成了这一任务。 由此产生的框架使我们能够实施各种后台任务,这些任务使存储系统能够连续执行一致性检查,并具有自我修复和自我管理的能力。
我们在Nutanix开发的商业企业集群的产品中执行了这项工作。 我们在五年的时间内开发了该系统,并将其部署在数千个企业集群中。 我们报告了系统的性能以及从构建和完善系统中获得的经验。 我们发现Curator有效地执行了垃圾回收和备份,平衡了各个磁盘的存储,并通过许多优化使存储访问效率更高。 而且我们意识到在简化了存储系统的构建下,该框架足够通用到可以在各种背景下进行转换。
尽管如此,我们注意到启发式方法不一定在所有集群中都有效,因为它们之间存在很大的异构性。 因此,我们最近开始开发一个基于机器学习的框架,以解决何时应该执行这些后台管理任务以及应该执行多少工作的问题。基于ML的方法有两个关键要求:1)较高的预测准确率;2)学习或适应(不断变化的)工作量特征的能力。我们提出使用强化学习,特别是Q-学习算法。我们最初的工作重点集中在以下分层问题上:在ssd和hdd中要保留多少数据?对五个模拟工作负载的实证评估证实了我们方法的总体有效性,并显示对延迟有了高达20%的改进。总之,我们的主要贡献是:
- 我们对Curator的设计和实现进行了广泛的描述,Curator是一种先进的分布式集群后台管理系统,它根据使用情况在存储层之间执行数据迁移、数据复制,磁盘平衡,垃圾回收等工作。
- 我们为了衡量Curator的优势使用了一系列相关指标,例如,在封闭的本地环境以及在客户部署和内部企业集群中的延迟、每秒的I/O操作(IOPS)、磁盘使用率等。
- 最后,我们提出一种基于强化学习的模型,以改善Curator的任务调度。 我们提供有关存储分层任务的经验结果,以展示我们解决方案的优点。
2 企业集群的分布式存储
我们在Nutanix为企业集群设计的分布式存储系统的环境中执行我们的工作。 在本节中,我们概述了软件体系结构,存储系统提供的关键功能以及用于支持它们的数据结构。 在这里我们提供了必要的背景资料,以了解Curator的设计。
2.1 集群体系结构
该软件体系结构是为各种规模的企业集群设计的。 Nutanix在数千个不同的客户位置部署了集群,集群的大小通常从几个节点到几十个节点不等。因为客户可以根据需要添加节点,所以集群节点可能具有异构资源。 集群支持(传统)应用程序的虚拟化执行,这些应用程序通常打包为VM。 集群管理软件为用户提供了一个创建,启动,停止和销毁VM的管理层。 此外,该软件会根据当前用户身份和单个节点的负载,自动调度和迁移VM。 这些任务由在每个节点上运行的Controller Virtual Machine(CVM,控制器虚拟机)执行。
这些CVMs共同形成一个分布式系统,该系统管理集群中的所有存储资源。 CVMs和它们管理的存储资源提供了分布式存储结构(DSF,distributed storage fabric)的抽象,该结构随节点数扩展,并提供对在集群中任何节点上运行的用户VM(UVM,user VM)的透明存储访问。 图1显示了集群体系结构的高级概述。
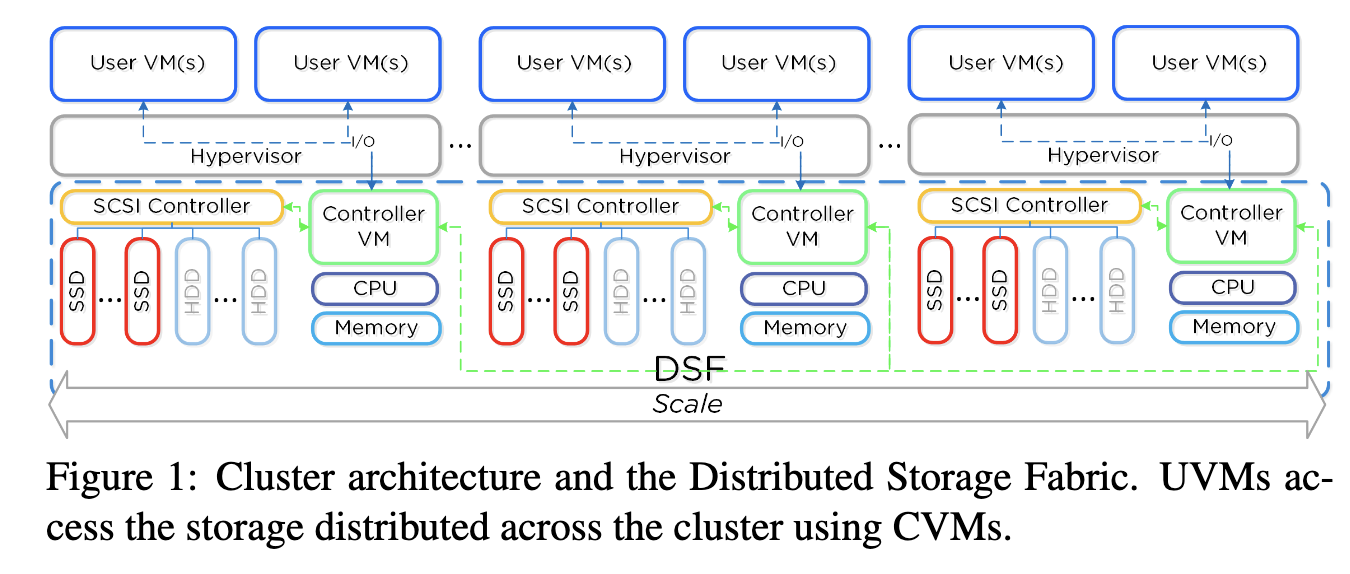
在UVM中运行的应用程序使用传统文件系统接口(例如NFS,iSCSI或SMB)访问分布式存储结构。 这些传统文件系统接口上的操作插入在管理程序层,并重定向到CVM。 CVM将显示为磁盘的一个或多个块设备导出到UVM。 这些块设备是虚拟的(它们由CVM内部运行的软件实现),称为vDisk。 因此,对于UVM,CVM似乎正在导出存储区域网络(SAN,storage area network),其中包含在其上执行操作的磁盘。UVM中的所有用户数据(包括操作系统)都驻留在这些vDisk上,并且最终将vDisk操作映射到位于群集内部任何位置的某些物理存储设备(SSDs或HDDs)。
尽管使用CVM在资源利用率方面带来了额外的开销,但也提供了很大的好处。 首先,它允许我们的存储堆栈在任何虚拟机监控程序上运行。 其次,它可以在不关闭节点的情况下升级存储堆栈软件。 为了支持此功能,我们在虚拟机监控程序级别实施了一些简单的逻辑,以将其I / O通过多路径有效的传输到能够满足存储请求的另一个CVM。 第三,它提供了角色的明确分离和更快的开发周期。 在管理程序(甚至内核)中构建复杂的存储堆栈将严重影响我们的开发速度。
2.2 存储系统和关联的数据结构
现在我们要描述DSF的几个关键要求,以及这些要求如何影响用于存储元数据和Curator的设计的数据结构。
- R1-可靠性/弹性:系统应能及时处理故障。
- R2-保存位置:数据应迁移到经常访问它的VM的节点。
- R3-分层存储:数据应在SSD,硬盘驱动器和公共云之间分层。 此外,SSD层不仅应充当热数据的缓存层,而且还要负责用户数据的永久存储。
- R4-快照:系统应允许用户快速创建快照以增强鲁棒性。
- R5-空间利用率:系统应在支持传统应用程序的同时实现高存储效率,而不必对文件大小或其他工作负载模式作出任何假设。
- R6-可扩展性:系统的吞吐量应该随着系统中节点的数量而扩展。
以上需求集在系统设计中以两种方式体现出来:(a)我们用于存储元数据的数据结构集,以及(b)系统将执行的管理任务集。 我们接下来讨论数据结构,将Curator执行的管理任务推迟到3.2中讲解。
每个vDisk(在2.1节中介绍的)都对应一个虚拟地址空间,该虚拟地址空间使用不同字节表示一个磁盘,并公开给用户VM。 因此,如果vDisk的大小为1 TB,则维护的相应地址空间为1TB。 该地址空间分为相等大小的单元,称为vDisk块。 每个存储在物理磁盘上的[vDisk块中的数据]都称为extent。 为了细化和提高效率,写入/读取/修改的操作在extent的子区域上(也称为切片)进行。 extent大小与vDisk块内的活动数据量相对应。 如果vDisk块包含未写入的区域,则extent的空间小于vDisk块空间(因此满足R5)。
【即vDisk和块代表磁盘空间,extent代表磁盘存储的数据】
多个extent被分组为一个单元称为extent组。 每个extent和extent组都分配有一个唯一的标识符,分别称为extent ID和extent组ID。 extent组是物理分配的单位,并作为文件存储在磁盘上,热extent组存储在SSD中,冷extent组存储在硬盘(R3)上。 extent和extent组在节点上动态分布,以实现容错,磁盘平衡和性能目标(R1,R6)。
给定以上核心构造(vDisk,extent和extent组),我们现在描述系统如何存储元数据,以帮助定位每个vDisk块的实际内容。系统维护的元数据包含以下三个主要映射:
-
vDiskBlock映射:将vDisk和偏移量(标识vDisk块)映射到extentID。这是一个逻辑映射。
-
extentID 映射:将extent映射到包含它的extent组里。这也是一个逻辑映射。
-
extentGroupID 映射:将extentGroupID映射到该extentGroupID的副本的物理位置及其当前状态。这是一个物理映射。
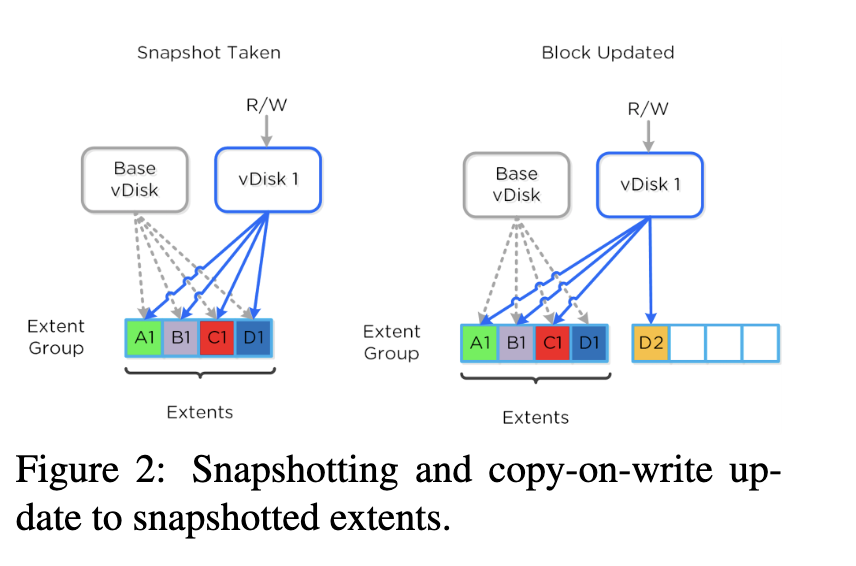
关于上述数据结构,这里有一些含义。 通过快照创建的多个vDisk可以共享同一extent。 快照的vDiskBlock映射可以直接指向与先前快照共享的extent,也可以缺少条目,在这种情况下,会参考上一个快照的vDiskBlock映射。 此功能允许即时创建快照,即,我们可以创建一个空的vDiskBlock映射条目,并使其指向所有未填充项(R4)的上一个快照。 同时,它通过延迟填充缺少的条目来进行元数据查找的后续优化(章节3.2.4)。 在新快照上更新vDisk块时,将创建一个新的extent来保存更新的数据。 图2显示了一个示例,其中将vDisk 1创建为快照,并且已经用指向相应extent的正确指针填充了vDiskBlock映射(左部分)。 之后,在更新其vDisk块之一(右侧部分)时,将其更新以指向新的extent。
只要来自一个extent组的数据重定位到另一extent组(例如,以优化访问权限),extentID映射引入的间接级别就可以进行有效的更新,因为它是我们将物理extentGroupID存储在单个位置 extent所在的位置(从而实现R2,R3)。
最终,仅通过查询extentGroupID映射即可执行一组管理操作。 例如,我们可以仅通过访问此映射来检测(并修复)给定程度上GroupID的副本数是否低于某个阈值-逻辑映射将保持不变-从而实现了R1。
总体而言,由此产生的数据结构使我们能够以高效且响应迅速的方式执行章节3.2中描述的各种管理任务。
3.Curator
Curator是集群管理组件,负责在整个集群中管理和分配各种存储管理任务,包括连续一致性检查,故障恢复,数据迁移,空间回收等。在这一节,我们描述Curator的体系结构(章节3.1),它执行的任务(章节3.2)以及执行这些任务的策略(章节3.3)。 最后,我们通过一组经验结果(章节3.4)展示其价值,并分享从构建Curator(章节3.5)中获得的经验和教训。
3.1 Curator 结构
Curator的设计受到以下考虑因素的影响。 首先,它应随存储系统所服务的存储量进行扩展,并应对节点资源中的异构性。 其次,Curator应提供一个灵活且可扩展的框架,以支持广泛的后台维护任务。 第三,Curator的机制不应干涉底层存储结构的操作或使其更复杂。 基于这些考虑,我们设计了一个具有以下关键组件和(或)概念的系统:
-
分布式元数据:元数据(即上一节中讨论的地图)以分布式环状方式存储,基于经过大量修改的Apache Cassandra [22],经过增强后可以为复制密钥的更新提供强大的一致性。 让元数据分布式存储是因为我们不希望元数据操作成为系统的瓶颈。 Paxos [23]用于强制执行严格的一致性以保证正确性。
-
分布式MapReduce执行框架:使用主/从体系结构,Curator在群集中的每个节点上作为后台进程运行。 主机是使用Paxos选举产生的,并负责任务和工作的委派。 Curator提供了一个MapReduce样式的基础结构[10]来执行元数据扫描,而主Curator进程管理MapReduce操作的执行。 这确保了Curator可以随群集存储量进行扩展,适应集群节点之间资源可用性的变化以及对元数据表执行有效的扫描/连接。
尽管我们的框架类似于一些数据并行引擎(例如Hadoop、Spark),但编写我们自己的框架而不是重新设计已有的框架有两个原因:1)效率,这些开源的大数据引擎没有对单个节点或小集群的高效工作进行很好的优化,而这对我们来说是必须的,2)它们对分布式存储系统(如HDFS)的需求,我们不希望在集群存储系统中具有递归依赖性。
-
【精读】Curator:企业集群存储管理系统
类型 内容 标题 Curator:Self-Managing Storage for Enterprise Clusters 时间 2017 会议 Symposium on Network System Design and Implementation 引用 Cano I, Aiyar S, Arora V, et al. Curator: Self-managing storage for enterprise clusters[C]//14th {USENIX} Symposium on Networked Systems Design and Implementation ({NSDI} 17). 2017: 51-66. 概览
作者构建了一个名为Curator的分布式集群存储管理系统。 它拥有以下功能:
- 数据迁移
- 恢复任务
- 空间回收
- 数据转换
这套系统在客户的集群中应用后,有明显的性能提升(主要表现在IO延迟的减少)和稳定性的提升。
背景
作者组成:2名来自华盛顿大学,8名来自Nutanix公司。
Nutanix(路坦力)公司在2009年成立,是一家提供超融合解决方案的设备厂商,他们的产品有两种形态:1、捆绑式的硬件 + 软件设备,2、纯软件模式
它在2013年进入中国市场,2016年和联想合作在2017年发表的文章SDN实战团分享(三十三):Nutanix超融合之架构设计里面就已经讲到了Curator,作为超融合集群中的一个组件来运行。
Curator将负责整个集群中存储的管理和分配,包括磁盘平衡、主动清理等任务。每个节点上d都会运行Curator进程,而且受主Curator的控制,主Curator会负责任务和作业的委派。
结构

- DSF(distributed storage fabric):分布式存储结构。
- vDisk: 映射到UVM中的虚拟块设备。(例如用户在虚拟机中看到磁盘大小是20G,但实际上这块磁盘并不存在,而是属于底层某一个真实的硬盘)
- extent:vDisk块中的数据。
- extent组:多个extent被分组为一个单元称为extent组。

功能
恢复任务(Recovery)
当出现磁盘故障或者磁盘被人为移除时,Curator将启动元数据扫描。
找到那些【故障磁盘】上存储的数据的备份。
通知底层系统,对备份不足的数据进行备份。数据迁移(Data Migration)
数据分层: 目的:将最常用的数据仅保留在最快的存储层中,以减少用户访问的延迟。 向下迁移:将不常用的数据从SSD移动到HDD(或从HDD移动到云) 向上迁移:在重复访问数据时开始迁移
磁盘平衡:
使不同磁盘的利用率接近于平均利用率。(数据横向迁移)
空间回收(Space Reclamation)
垃圾回收(GC,Garbage Collection):即减少碎片空间
- 迁移extent:将活动的extent迁移到新的extent组,删除旧的extent组,然后回收旧的extent组的垃圾。 这个操作成本很高,因为它涉及数据读取和写入。 因此,Curator针对每个extent组执行成本收益分析,并仅选择收益(扩展组中的死区数量)大于成本(被迁移的有效extent的空间总和)的extent组进行迁移。
- 打包extent:尝试在一个extent组中打包尽可能多的活动extent。
- 截断extent组:通过截断extent组来回收空间,即减小其空间大小。
数据删除(DR,Data Removal):即删除操作失败导致的空指针。
数据转换(Data Transformation)
目的:节省存储空间
压缩(C,Compression)和纠删码(EC,Erasure Coding) 重复数据删除(DD,Deduplication):在扫描时,Curator根据指纹检测出重复的数据,并通知DSF执行重复数据删除。 快照树深度缩减(STR,Snapshot Tree Reduction): 如果打的快照过多,可能导致快照树很深,以至于读取效率很低。
解决方法是将部分数据从父节点复制到子节点。执行策略
- 事件驱动:例如磁盘发生故障时,立即进行恢复任务
- 基于阈值:当个别磁盘使用率过高时,进行数据迁移
- 定期部分扫描
- 定期完整扫描
评估
评估恢复任务
大约60%的集群不存在数据备份不足的问题,95%的集群最多具有约为0.1%的备份不足的数据。显示了平均未复制数据的累积分布函数(CDF)占客户集群中总体存储容量的百分比(对数规模)。作者对剩余的40%集群进行观测,两周内并没有出现意外的停机事故。

评估数据分层
40%的集群的SSD利用率最多为70-75%。 在其余60%的集群中,大部分集群的SSD使用率在75%左右,这表明分层的任务已经被执行。
HDD的利用率通常较低,其中80%的集群的HDD利用率低于50%。
评估空间回收
90%的集群的垃圾少于2%,这证明垃圾收集任务非常有效。
评估磁盘平衡
60%的SSD和80%的HDD的最大磁盘使用率几乎与平均值相同。

是否启用-对比评估
-
【Python】爬取高顿网校中受版权保护的视频
朋友让我帮一个忙,下载某个网校中的网课视频,一开始本以为用传统的IDM之类的下载器,是可以捕获到这个视频流的。但是实际上根本捕不到,chrome上的各种插件也试了,都是无法识别的。
但是我在开发者模式上看收到的包,是有一堆序号连续的.ts文件的,请求的url格式大致为。
http://video1-cdn.gaodun.com/pub/09ohwP0Q0f1wJhRL/HD/1.ts根据多次试验发现,pub后面那段字符与课程有关,固定不变。而HD代表着视频的清晰度是高清。 百度了一下ts格式的视频,上面说ts格式的特点是无论从哪一段开始都可以直接进行解析。
于是直接请求下载下来一个ts文件,但尝试播放却失败了,提示无法解析。最后去了解了一下相关的原理。
M3U8 是 Unicode 版本的 M3U,用 UTF-8 编码。”M3U” 和 “M3U8” 文件都是苹果公司使用的 HTTP Live Streaming(HLS) 协议格式的基础,这种协议格式可以在 iPhone 和 Macbook 等设备播放。 HLS 的工作原理是把整个流分成一个个小的基于 HTTP 的文件来下载,每次只下载一些。当媒体流正在播放时,客户端可以选择从许多不同的备用源中以不同的速率下载同样的资源,允许流媒体会话适应不同的数据速率。在开始一个流媒体会话时,客户端会下载一个包含元数据的 extended M3U (m3u8) playlist文件,用于寻找可用的媒体流。 HLS 只请求基本的 HTTP 报文,与实时传输协议(RTP)不同,HLS 可以穿过任何允许 HTTP 数据通过的防火墙或者代理服务器。它也很容易使用内容分发网络来传输媒体流。
于是我返回去看chrome上记录的请求,果然看到有一个请求返回的response是m3u8,大致如下格式
#EXTM3U #EXT-X-VERSION:3 #EXT-X-PLAYLIST-TYPE:VOD #EXT-X-ALLOW-CACHE:YES #EXT-X-TARGETDURATION:37 #EXT-X-KEY:METHOD=AES-128,URI="http://live-hz.gaodun.com/player/authorize?id=09ohwP0Q0f1wJhRL&session=44512&token=1i48ds24mba12",IV=0x763f74c0066ef2a3e040262827d55c29 #EXTINF:30.080000, http://video1-cdn.gaodun.com/pub/09ohwP0Q0f1wJhRL/HD/0.ts #EXTINF:30.000000, http://video1-cdn.gaodun.com/pub/09ohwP0Q0f1wJhRL/HD/1.ts #EXTINF:30.000000, http://video1-cdn.gaodun.com/pub/09ohwP0Q0f1wJhRL/HD/2.ts #EXTINF:30.000000, http://video1-cdn.gaodun.com/pub/09ohwP0Q0f1wJhRL/HD/3.ts其中能大概看到的是EXTINF代表视频的时长,而后面的链接则代表视频的地址。那这个相当于播放列表的文件,就给我下载视频提供了方便。
但是我也注意到里面提到了AES-128,这是一个对称加密的算法,URI中存的链接,就是获取秘钥的方法。于是我根据网上的资料,以及别人关于解密的代码,整理出来一版解密并下载视频的
注意:需要安装pycrypto库(pip3 install pycrypto)import requests from Crypto.Cipher import AES def read_m3u8(filename): m3u8_file = open(filename,"r") all_content = m3u8_file.read(); if "#EXTM3U" not in all_content: raise BaseException("非M3U8的链接") file_line = all_content.split("\n") unknow = True key = "" for index, line in enumerate(file_line): # 第二层 if "#EXT-X-KEY" in line: # 找解密Key method_pos = line.find("METHOD") comma_pos = line.find(",") method = line[method_pos:comma_pos].split('=')[1] print("Decode Method:", method) uri_pos = line.find("URI") quotation_mark_pos = line.rfind('"') key_path = line[uri_pos:quotation_mark_pos].split('"')[1] key_url = key_path # 拼出key解密密钥URL res = requests.get(key_url) key = res.content print("key_url:",key_url) print("key:",key) if "EXTINF" in line: # 找ts地址并下载 unknow = False pd_url = file_line[index + 1] # 拼出ts片段的URL print(pd_url) res = requests.get(pd_url) c_fule_name = file_line[index + 1].rsplit("/", 1)[-1] if len(key): # AES 解密 cryptor = AES.new(key, AES.MODE_CBC, key) with open(c_fule_name + ".tmp", 'ab') as f: f.write(cryptor.decrypt(res.content)) else: with open(c_fule_name, 'ab') as f: f.write(res.content) f.flush()下载下来的是一堆.tmp文件(其实是.ts),直接进行用二进制进行合并即可。
代码待更新,届时以github为准。
-
临时笔记-后续考虑跟进
目的就是有一些看到的知识点,先记下来,以后再仔细看。
2019-12-8
SAN实际是一种专门为存储建立的独立于TCP/IP网络之外的专用网络。目前一般的SAN提供2Gb/S到4Gb/S的传输数率,同时SAN网络独立于数据网络存在,因此存取速度很快,另外SAN一般采用高端的RAID阵列,使SAN的性能在几种专业存储方案中傲视群雄。
SAN由于其基础是一个专用网络,因此扩展性很强,不管是在一个SAN系统中增加一定的存储空间还是增加几台使用存储空间的服务器都非常方便。通过SAN接口的磁带机,SAN系统可以方便高效的实现数据的集中备份。
目前常见的SAN有FC-SAN和IP-SAN,其中FC-SAN为通过光纤通道协议转发SCSI协议,IP-SAN通过TCP协议转发SCSI协议。2019-12-16
Tengine
Tengine是由淘宝网发起的Web服务器项目。它在Nginx的基础上,针对大访问量网站的需求,添加了很多高级功能和特性。Tengine的性能和稳定性已经在大型的网站如淘宝网,天猫商城等得到了很好的检验。它的最终目标是打造一个高效、稳定、安全、易用的Web平台。 http://tengine.taobao.org/
2019-12-21
Q-learning
2019-12-22
GTD:
- 收集箱(Inbox)
- 执行清单(@context task)
- 等待清单(waiting for task)
- 项目清单(plan project)
- 可能清单(someday/maybe)
- 参考资料(Reference)
- 回收箱(Trash)
问题 方案 这件事情可行动吗? 否→ 参考资料、可能清单、回收箱 这件事可以一部搞定吗? 否→ 项目清单 这件事可以在2分钟内搞定吗? 立即做 这件事该我做吗? 否→ 等待清单 有特定时间吗? 否→ 执行清单 2019-12-23
纠删码
-
【Python】Python的命令行解析库argparse
简介
这个库用于命令行参数解析
import argparse # 初始化解析器 parser = argparse.ArgumentParser( description='示例', ) # 添加解析的参数,可以多个 parser.add_argument("-a","--any",help="message",action='store',default='1') # 开始解析 args = parser.parse_args() # 直接可以访问这个变量 print(args.a)参数中的可选的设置
default
设置默认值
action
- store:默认action模式,存储值到指定变量。
- store_const:存储值在参数的const部分指定,多用于实现非布尔的命令行flag。
- store_true / store_false:布尔开关。可以2个参数对应一个变量。
- append:存储值到列表,该参数可以重复使用。
- append_const:存储值到列表,存储值在参数的const部分指定。
- count: 参数出现的次数
- version 输出版本信息然后退出。
其中store_true代表这个参数后面不用跟东西,是一个开关的作用
type
输入的结果进行类型转换
choice
设置允许的参数值 例如
choice=[1,2,3]
-
【Linux】jupyter的安装及使用
本文不完整参考于工作时写的jupyter调研报告,可能信息略有滞后性。
快速启动命令
jupyter notebook --ip='0.0.0.0' --allow-root- –port 默认为8888
- –notebook-dir
安装
使用pip安装jupyter
安装pip
wget "https://pypi.python.org/packages/source/p/pip/pip-1.5.4.tar.gz tar -xzvf pip-1.5.4.tar.gz cd pip-1.5.4 python setup.py install重新编译python
./configure Make && make install使用pip安装juypter
yum install sqlite-devel -y pip install jupyter使用Docker启动jupyter
镜像依赖关系
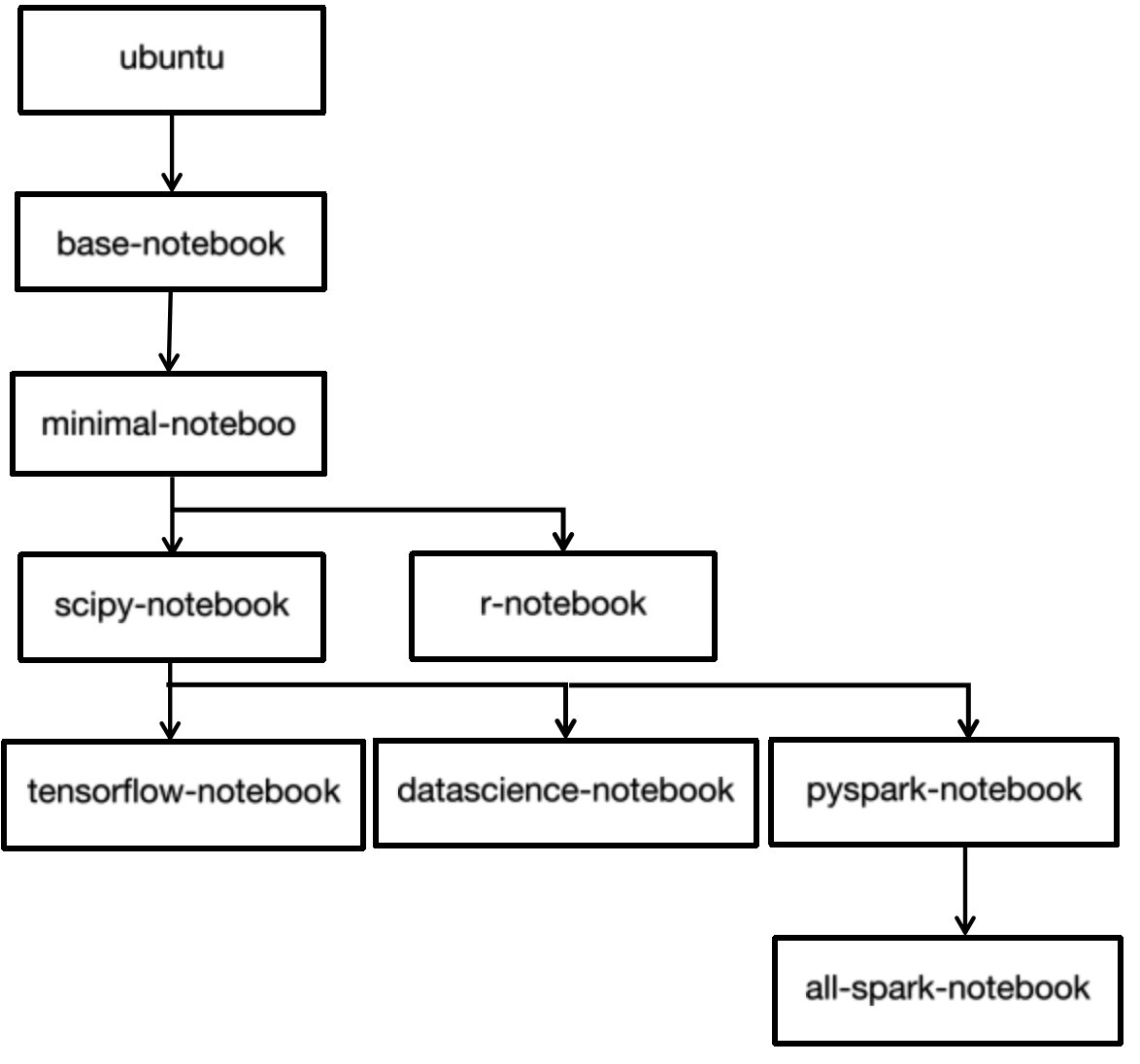 其中的Scipy-notebook安装了
其中的Scipy-notebook安装了pandas, numexpr, matplotlib, scipy, seaborn, scikit-learn, scikit-image, sympy, cython, patsy, statsmodel, cloudpickle, dill, numba, bokeh, sqlalchemy, hdf5, vincent, beautifulsoup, protobuf, xlrd拉取镜像
docker pull jupyter/datascience-notebook启动命令
docker run -it -p 8888:8888 jupyter/tensorflow-notebook其它选项:把参数传递给start-notebook.sh
docker run -it -p 8888:8888 jupyter/base-notebook start-notebook.sh --NotebookApp.base_url=/some/path后台运行
docker run -d --name jupyter -p 8888:8888 -v "$PWD":/home/jovyan/work jupyter/datascience-notebook启动jupyter lab
docker run -d --name jupyter -p 8888:8888 -v "$PWD":/home/jovyan/work jupyter/datascience-notebook start.sh jupyter lab --NotebookApp.password='argon2:$argon2id$v=19$m=10240,t=10,p=8$7gVfSxZ7wIXugW0RfJvQUw$xmoeKSekY5VuNdwZfnWctA' -e GRANT_SUDO=yes --user root选项
配置自定义密码
In [1]: from notebook.auth import passwd In [2]: passwd() Enter password: Verify password: Out[2]: 'sha1:67c9e60bb8b6:9ffede0825894254b2e042ea597d771089e11aed'启动时
docker run -d -p 8888:8888 jupyter/base-notebook start-notebook.sh --NotebookApp.password='sha1:74ba40f8a388:c913541b7ee99d15d5ed31d4226bf7838f83a50e'start-notebook.sh在启动笔记本服务器之前指示脚本自定义容器环境。可以通过将参数传递给docker run命令来完成此操作。
-e NB_USER=jovyan-指示启动脚本将默认容器用户名更改jovyan为提供的值。使脚本重命名jovyan用户主文件夹。-e NB_UID=1000指示启动脚本将数字用户ID切换$NB_USER为给定值。在装入具有特定所有者权限的主机卷时,此功能非常有用。要使此选项生效,必须使用运行容器–user root。(启动脚本将su $NB_USER调整该用户ID后。)您可以考虑使用现代化的码头工人的选择–user和–group-add替代。有关详细信息,请参见下面的子弹。-e NB_GID=100-指示启动脚本将添加$NB_USER到具有给定组ID的新补充组。在装入具有特定组权限的主机卷时,此功能非常有用。要使此选项生效,必须使用运行容器--user root(启动脚本将su $NB_USER调整组ID后。)您可以考虑使用现代化的码头工人的选择–user和–group-add替代。有关详细信息,请参见下面的子弹。-e CHOWN_HOME=yes-指示启动脚本来改变$NB_USER主目录的所有者和组的当前值$NB_UID和$NB_GID。即使使用-v如下所述从主机安装用户主目录,此更改也将生效。默认情况下,不会递归地应用更改。您可以chown通过设置CHOWN_HOME_OPTS(例如-e CHOWN_HOME_OPTS=’-R’)更改修改行为。-e CHOWN_EXTRA="<some dir>,<some other dir>- 指示启动脚本将每个以逗号分隔的容器目录的所有者和组更改为当前值$NB_UID和$NB_GID。默认情况下,不会递归地应用更改。您可以chown通过设置CHOWN_EXTRA_OPTS(例如-e CHOWN_EXTRA_OPTS=’-R’)更改修改行为。-e GRANT_SUDO=yes指示启动脚本授予NB_USER用户无密码sudo功能。但是,当您希望能够在容器中$NB_USER安装apt或修改其他根拥有文件时,此选项很有用。要使此选项生效,必须使用运行容器–user root。(该start-notebook.sh脚本将su $NB_USER在添加$NB_USER到sudoers之后。)-e GEN_CERT=yes- 指示启动脚本生成自签名SSL证书并配置Jupyter Notebook以使用它来接受加密的HTTPS连接。-e JUPYTER_ENABLE_LAB=yes- 指示启动脚本jupyter lab而不是默认jupyter notebook命令。在容器编排环境中很有用,其中设置环境变量比更改命令行参数更容易。-v /some/host/folder/for/work:/home/jovyan/work- 将主机目录安装为容器中的文件夹,需要授予容器内用户或组(NB_UID或NB_GID)对主机目录的写访问权限(例如sudo chown 1000 /some/host/folder/for/work)。--user 5000 --group-add users- 使用特定用户ID启动容器,并将该用户添加到该users组,以便它可以修改默认主目录中的文件/opt/conda。您可以使用这些参数作为设置$NB_UID和的替代方法$NB_GID。
使用Anaconda安装jupyter
从清华的镜像站下载最新的miniconda的镜像包: https://mirrors.tuna.tsinghua.edu.cn/anaconda/miniconda/
执行安装脚本sh Miniconda3-latest-Linux-x86_64.sh执行命令conda install jupyter
下载速度慢的解决方法: 执行命令,添加清华镜像源conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/ conda config --set show_channel_urls yes conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/ conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2/同样也可以
conda install jupyterhub,conda install jupyterlab等